2015-08-21
2015-08-21 2332
2332Нейросетевой регулятор, описанный в этом разделе, использует в качестве модели управляемого процесса модель нелинейной авторегрессии со скользящим средним (Nonlinear Autoregressive-Moving Average – NARMA-L2). Схема демонстрационного примера управления магнитной подушкой показана на рис. 9.42.
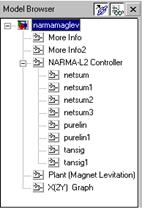 | 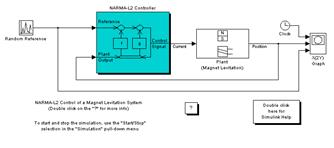 |
Рис. 9.42
Окно Model Browser в левой части рисунка содержит перечень всех блоков, входящих в состав системы управления, представленной в виде модели системы Simulink.
Управляемым объектом является магнит, который движется только в вертикальном направлении в электромагнитном поле, как это схематично показано на рис. 9.43.
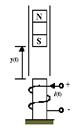 Рис. 9.43
Рис. 9.43
Уравнение движения этой системы имеет вид:
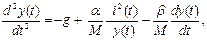 (9.6)
(9.6)
где y (t) – расстояние движущегося магнита от электромагнита; g – ускорение силы тяжести; a – постоянная магнитного поля, зависящая от числа витков обмотки и намагниченности электромагнита; i (t) – управляющий ток электромагнита; M – масса магнита;
b – коэффициент вязкого трения.
Соответствующая динамическая модель, реализованная в системе Simulink, показана на рис. 9.44. Точно такую же модель, но с конкретными числовыми данными вы сможете увидеть на экране терминала, если активизируете блок Plant (Magnet Levitation) в окне Model Browser.
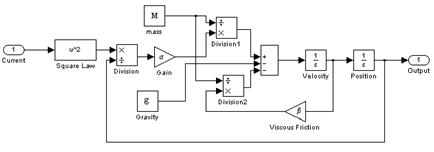 Рис. 9.44
Рис. 9.44
Заметим, что рассматриваемая динамическая система является нелинейной, и мы будем строить ее дискретную нелинейную модель как авторегрессионную модель со скользящим средним, или NARMA-модель, в форме
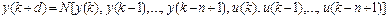 , (9.7)
, (9.7)
где y (k) – выход модели; d – число тактов предсказания; u (k) – вход модели.
На этапе идентификации необходимо построить нейронную сеть для NARMA-модели вида (9.7). Эта процедура аналогична описанной выше процедуре идентификации для регулятора с предсказанием.
Если требуется спроектировать следящую систему, которая обеспечивает движение по заданной траектории
y (k+d) = yr (k+d), (9.8)
то это означает, что необходимо сформировать нелинейный регулятор следующего
общего вида:
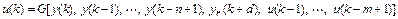 . (9.9)
. (9.9)
Хотя такой регулятор с помощью нейронной сети и может быть сформирован, однако
в процессе минимизации среднеквадратичной ошибки он требует чрезмерных вычислений, поскольку использует динамический вариант метода обратного распространения ошибки [16]. Для практического решения задачи слежения Нарендра (Narendra) и Макхопадхаи (Mukhopadhyay) [31] предложили приближенную NARMA-модель с выделенной составляющей управления. Такая модель регулятора, именуемая моделью NARMA-L2, имеет вид:
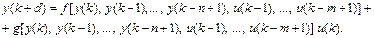 (9.10)
(9.10)
Преимущество этой формы состоит в том, что теперь текущее управление можно
непосредственно вычислить, если известна желаемая траектория yr, предыстория управления { u (k – 1), …, u (k – m + 1)}, а также предшествующие и текущее значения выхода { y (k), …, y (k – n + 1)}:
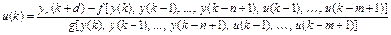 . (9.11)
. (9.11)
Непосредственное применение этого соотношения для реализации регулятора затруднительно, поскольку управление u (k) зависит от текущего значения выхода y (k). Поэтому управление (9.11) модифицируется следующим образом:

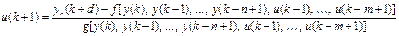 , (9.12)
, (9.12)
но при этом параметр предсказания должен удовлетворять условию d ³ 2.
На рис. 9.45 показана структура соответствующего регулятора в виде нейронной сети.
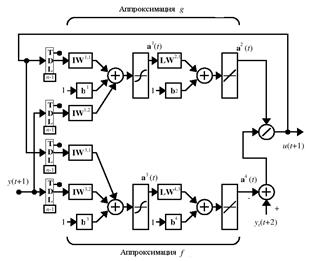 Рис. 9.45
Рис. 9.45
Здесь следует обратить внимание на участки сети, которые выполняют аппроксимацию нелинейных операторов g и f в виде выходов 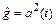 и
и 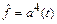 . Входами регулятора являются сигналы y (t +1) и u (t +1), последний реализован в виде обратной связи,
. Входами регулятора являются сигналы y (t +1) и u (t +1), последний реализован в виде обратной связи,
а также эталонный сигнал yr (t +2). Блоки задержки осуществляют запоминание соответствующих последовательностей входа и выхода, а затем используются двухслойные нейронные сети, которые формируют оценки нелинейных операторов и вычисляют сигнал управления в форме (9.12).
Общая структурная схема системы с регулятором NARMA-L2 показана на рис. 9.46.
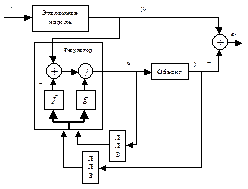 Рис. 9.46
Рис. 9.46
На схеме явным образом выделена эталонная модель, которая задает желаемую траекторию для выхода управляемого процесса.
Демонстрационный пример NARMA-L2 Controller использует следующие файлы, размещенные в каталоге toolbox\nnet\nncontrol.
MAT-файлы данных:
ball1– данные для обучения нейросетевой модели магнитной подушки.
Функции активации, используемые в нейронной сети контроллера NARMA-L2:
netinv – функция активации (1/n);
dnetinv – производная функции активации (1/n).
Модели Simulink:
ballrepel0 – модель магнитной подушки;
narmamaglev – GUI-приложение для контроллера NARMA-L2.
Вспомогательные функции:
sfunxy2 – S-функция для вывода графиков;
nncontrolutil – утилита, обеспечивающая возможность обращения к частным функциям из системы Simulink.
Выполнить запуск демонстрационного примера можно несколькими способами:
· в окне запуска приложений Launch Pad выбрать опцию Demos для ППП Neural Network Toolbox;
· ввести команду narmamaglev в командном окне системы MATLAB.
Для того чтобы начать работу, необходимо активизировать блок NARMA-L2 Controller двойным щелчком левой кнопки мыши. Появится окно, показанное на рис. 9.47.
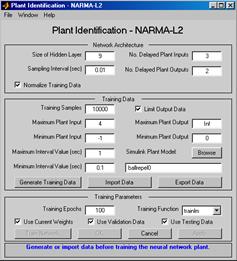 Рис. 9.47
Рис. 9.47
Обратите внимание, что это окно дает возможность обучить модель NARMA-L2.
Отдельного окна для обучения регулятора нет, так как регулятор NARMA-L2, в отличие от регулятора с предсказанием, определяется непосредственно по модели.
Это окно работает так же, как и другие окна идентификации объекта управления, поэтому повторно подробно процесс обучения рассматривать не будем.
После окончания обучения нажать на клавишу OK дляввода данных регулятора в модельSimulink.Возвращаемся к модели Simulink (см. рис. 9.34) и начинаем моделирование, выбрав опцию Start из меню Simulation. Графики задающего сигнала и выхода системы приведены на рис. 9.48.
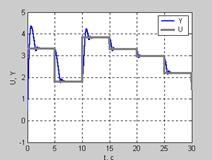 Рис. 9.48
Рис. 9.48
Из анализа полученных данных следует, что реакция системы на ступенчатые воздействия со случайной амплитудой вполне удовлетворительна, имеет колебательный характер с достаточно быстрым затуханием; на интервале 5 с все уставки эффективно отрабатываются. Таким образом, регулятор NARMA-L2, реализованный в виде нейронной сети, можно использовать для управления магнитной подушкой.