 2015-09-06
2015-09-06 525
525В настоящее время выбор структуры корпоративных информационно-вычислительных сетей (КИВС) чаще всего осуществляется эмпирическим путем. Как правило, это делают специалисты, основываясь на собственном опыте. Таким образом, процесс проектирования КИВС субъективен и зависит от конкретного человека (или фирмы, осуществляющей проектирование). На начальном этапе, когда число КИВС было невелико, такой подход к проектированию был приемлем. Стремительное развитие информационных технологий, их активное внедрение в производство и бизнес привело к резкому увеличению спроса на корпоративные вычислительные сети. Кроме того, назрела необходимость оценки качества и модернизации большого количества КИВС, спроектированных и введенных в эксплуатацию в 90-х годах XX века. Появились компании осуществляющие проектирование, монтаж и техническое сопровождение КИВС. Методики и алгоритмы проектирования в таких компаниях являются основным производственным средством (ноу-хау) и составляют коммерческую тайну. Из-за этого они недоступны для широкого круга специалистов, нельзя оценить их достоинства и недостатки, вносить изменения, направленные на улучшение качества методик и алгоритмов проектирования. Отсутствие общедоступных методик и алгоритмов выбора структур КИВС негативно сказывается на развитии данной области IT. Наличие общедоступных методик и алгоритмов выбора структур КИВС сделают эту область открытой для более широкого круга специалистов, ускорит темп её развития.
Научные исследования и разработки, посвященные данной проблемной области, сделанные как несколько десятилетий назад, так и современные обладают рядом существенных недостатков, основными из которых являются: синтез структуры КИВС без тщательного анализа потребностей организации в информационном обмене, без учета структуры и параметров информационного взаимодействия внутри организации; использование при расчете и оптимизации сетевой инфраструктуры низкоэффективных алгоритмов, делающими практически невозможным получение решений с удовлетворительной точностью за приемлемое время даже на современных вычислительных машинах (30), (41), (43); несоответствие получаемых проектам сетей требованиям современных стандартов (34), что существенно снижает их практическую ценность. Такие недостатки присущи большей части работ, за исключением лишь некоторых, например, посвященных проектированию региональных сетей.
Анализ проектных процедур показывает, что наиболее сложными и трудоемкими являются начальные этапы проектирования КИВС, поскольку именно на этих этапах принимаются решения, оказывающие влияние на качество всей сети. Ошибки, допущенные на начальных этапах проектирования, в конечном счете, приводят к необходимости переделки всего проекта, а значит к значительным материальным убыткам. Поэтому представляется актуальным разработка эффективной методики, в рамках которой осуществляется формализация, алгоритмизация и автоматизация решения задач выбора структуры КИВС на начальных этапах проектирования.
Несмотря на относительную молодость этой области IT, на некоторые ее компоненты введены международные стандарты. Кроме того, существует довольно обширный опыт и наработки в сфере проектирования вычислительных сетей (ВС), накопленный ведущими компаниями производителями оборудования для компьютерных сетей, таких как Cisco, 3Com и д.р. Поэтому, для повышения практической значимости и легкой реализации разработанного проекта сети на практике, выбор структуры КИВС в рамках разрабатываемой методики в обязательном порядке должен вестись в соответствии с международными стандартами в области компьютерных сетей, а также учитывать опыт ведущих компаний.
20. Основы СОМ и СОМ+
Конец формы
Основной прикладной сервис — СОМ+, среда выполнения СОМ компонентов. Средствами СОМ+ вы сможете объявить сервисы или выяснить, какие из них доступны. Инфраструктуру, обеспечивающую работу сервисов СОМ+, разработала компания Microsoft. Основной элемент этой инфраструктуры — координатор распределенных транзакций (Distributed Transaction Coordinator, DTC), позволяющий объединять компоненты в функциональные модули. Он позволяет убедиться, что ресурсы, которые должны обновляться вместе, изменены либо все сразу, либо вообще не изменены (даже если модуль включает нескольких компонентов). Кроме того, существуют и средства администрирования, упрощающие развертывание и комплектацию многокомпонентных приложений. Попросту говоря, СОМ+ — это новый этап эволюции хорошо всем знакомой технологии СОМ и сервера транзакций MTS (он поставляется в составе пакета Option Pack Windows NT).
Microsoft объединила эти технологии в одну модель программирования СОМ+ и включила ее в состав Windows 2000. Большая часть моей лекции посвящена разработке приложений для MTS. Описанные мною принципы пригодятся вам, даже если ваша программа должна работать в Windows NT 4 или ваши клиенты не могут использовать новые функции Windows 2000. Вместе с СОМ+ используются еще некоторые важные сервисы. Это — Internet Information Server и активные серверные страницы (Active Server Pages, ASP), применяемые для динамической генерации HTML-страниц и их передачи интернет-клиентам.
Компоненты инкапсулируют большую часть функций, выполняемых ASP-страницами, а для вызова компонентов применяются сценарии. Для реализации представительского уровня используется HTML —- этот язык позволяет отображать информацию одинаково на всех платформах. Еще один прикладной сервис — Microsoft Message Queue Server (MSMQ) — предназначен для передачи сообщения в определенную вами стандартную инфраструктуру и позволяет определять формат сообщения и объединять слабо связанные приложения. Еще одно преимущество MS V1Q заключается в том, что сообщение доставляется только один раз, причем выбирается наименее затратный механизм маршрутизации. Кроме того, вы можете назначать сообщениям приоритеты. Как видите, технология MSMQ превосходит методы работы с сообщениями в ПСОМ. В СОМ уже введено понятие объекта и интерфейса.
Основное свойство СОМ таково: доступ к объекту осуществляется с помощью его интерфейса. Чтобы создать объект, к которому вы хотите обращаться, нужно использовать фабрику классов (class factory). Для доступа к интерфейсам применяется стандартный интерфейс IDnknown. на основе которого должны создаваться все объекты. Классы объединяются в двоичные модули, называемые СОМ-компонентами. В такие компоненты включена регистрационная информация, необходимая для их установки на компьютере.
Они также содержат данные о методах упаковки объектов, необходимые для их загрузки и вызова операционной системой. MTS может похвастаться новинками, в частности декларативным программированием и управлением состояния. Используя декларативное программирование, вы вправе работать с базовыми компонентами, обращаясь к ним посредством интерфейсов. Клиенты получают интерфейсные указатели и с их помощью взаимодействуют с объектами. Вы можете определить информацию о способах использования сервисов данного компонента на уровне самого компонента, класса, интерфейса, а в СОМ+ — и на уровне метода.
21.Правила выполнения запросов на выборку данных:
· правила выполнения простых однотабличных запросов;
Однотабличные запросы в большинстве своем являются простыми, и смысл такого запроса обычно можно легко понять, просто прочитав инструкцию select. Однако по мере возрастания сложности запроса появляется необходимость в более точном определении результатов, которые будут возвращены данной инструкцией select.
Результаты запроса, возвращенные инструкцией select, получаются в результате поочередного применения входящих в инструкцию предложений. Вначале применяется предложение from (оно выбирает таблицу, содержащую требуемые данные), затем — where (которое по определенному критерию отбирает из таблицы строки), далее — select (которое создает указанные столбцы результатов запроса и при необходимости удаляет повторяющиеся строки) и, наконец, order by (сортирует результаты запроса).
Таблица результатов запроса на выборку генерируется следующим образом:
Взять таблицу, указанную в предложении from.
Если имеется предложение where, применить заданное в нем условие отбора к каждой строке таблицы и оставить только те строки, для которых это условие выполняется, т.е. имеет значение true; строки, для которых условие отбора имеет значение false или null, — отбросить.
Для каждой из оставшихся строк вычислить значение каждого элемента в списке возвращаемых столбцов и создать одну строку таблицы результатов запроса. При каждой ссылке на столбец используется значение столбца для текущей строки.
Если указано ключевое слово distinct, удалить из таблицы результатов запроса все повторяющиеся строки.
· правила выполнения многотабличных запросов;
На практике многие запросы считывают информацию сразу из нескольких таблиц базы данных. Например, приведенные ниже запросы к учебной базе данных извлекают данные из двух, трех или четырех таблиц.
- Вывести список служащих и офисов, в которых они работают (таблицы salesreps и offices).
- Вывести список заказов, сделанных на прошлой неделе, включая следующую информацию: стоимость заказа, имя клиента, сделавшего заказ, и описание заказанного товара (таблицы orders, customers и products)
- Показать все заказы, принятые в восточном регионе, в том числе описания товаров и имена служащих, принявших заказы (таблицы orders, salesreps, offices и products).
SQL позволяет получить ответы на эти запросы посредством многотабличных запросов, которые объединяют данные из нескольких таблиц. В настоящей главе рассматриваются такие запросы и имеющиеся в SQL средства объединения.
Пример двухтабличного запроса
Чтобы понять, как в SQL реализуются многотабличные запросы, лучше всего начать с рассмотрения простого запроса, который объединяет данные из двух различных таблиц.
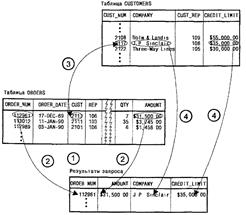
Вывести список всех заказов, включая номер и стоимость заказа, а также имя и лимит кредита клиента, сделавшего заказ.
Из рисунка 1 видно, что четыре запрашиваемых элемента данных хранятся в двух различных таблицах:
В таблице orders содержится номер и стоимость каждого заказа, но в ней отсутствуют имена клиентов и лимиты предоставленных им кредитов.
В таблице customers содержатся имена клиентов и данные о состоянии их счетов, но в ней нет информации о заказах.
Однако между двумя этими таблицами существует связь. В каждой строке столбца cust таблицы orders содержится идентификатор клиента, сделавшего заказ, соответствующий значению одной из строк столбца cust_NUM таблицы customers. Очевидно, чтобы получить требуемые результаты, в инструкции select, с помощью которой осуществляется запрос, необходимо как-то учесть эту связь между таблицами.
Прежде чем рассматривать инструкцию select, выполняющую этот запрос, будет полезно обдумать, как бы вы выполнили этот запрос вручную с помощью карандаша и бумаги. На рисунке 2 изображены действия, которые предположительно придется выполнить:
1. Сначала нарисуйте таблицу для результатов запроса, содержащую четыре столбца, и запишите имена столбцов. Затем перейдите к таблице orders и начните с первого заказа
2. Найдите в строке для первого заказа его номер (112961) и стоимость ($31,500 00), а затем перепишите оба значения в первую строку таблицы результатов
3. В строке для первого заказа найдите идентификатор клиента, сделавшего заказ (2117) Перейдите к таблице customers и в столбце custjnjum найдите строку с идентификатором клиента 2117.
4. В данной строке таблицы customers найдите имя клиента (J.P. Sinclair) и лимит кредита ($35,500.00) и перепишите их в таблицу результатов.
5. Вы создали только одну строку результатов запроса’ Вернитесь к таблице orders и принимайтесь за следующую строку. Повторяйте процесс, начиная с пункта 2, до тех пор, пока не переберете все заказы.

Конечно, это не единственный способ получить результаты данного запроса, но как бы вы их ни получали, всегда будут справедливы две вещи:
- Каждая строка таблицы результатов запроса формируется из пары строк: одна строка находится в таблице orders, а другая — в таблице customers.
- Для нахождения данной пары строк производится сравнение содержимого соответствующих столбцов в этих таблицах.
· итоговые запросы на выборку
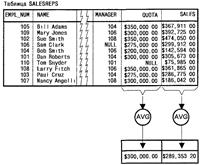
Для подведения итогов по информации, содержащейся в базе данных, в SQL предусмотрены статистические (агрегатные) функции. Статистическая функция принимает в качестве аргумента какой-либо столбец данных целиком, а возвращает одно значение, которое определенным образом подытоживает этот столбец. Например, функция avg () принимает в качестве аргумента столбец чисел и вычисляет их среднее значение. Ниже приведен запрос, в котором функция avg () используется для вычисления среднего значения в двух столбцах таблицы salesreps:
Каковы средний плановый и средний фактический объемы продаж в нашей компании?
SELECT AVG(QUOTA), AVG(SALES) FROM SALESREPS
AVG(QUOTA) AVG(SALES)
$300,000.00 $289,353.2
На рисунке изображена схема выполнения такого запроса. Первая статистическая функция принимает в качестве аргументов все значения, содержащиеся в столбце quota, и вычисляет их среднее значение; вторая функция подсчитывает среднее значение столбца sales Результатом запроса является одна строка, представляющая итоги по информации, содержащейся в таблице salesreps.
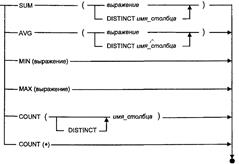
В SQL имеется шесть статистических функций, которые позволяют получать различные виды итоговой информации:
- функция sum () вычисляет сумму всех значений столбца;
- функция avg () вычисляет среднее всех значений столбца;
- функция min () находит наименьшее среди всех значений столбца;
- функция мах () находит наибольшее среди всех значений столбца;
- функция count () подсчитывает количество значений, содержащихся в столбце;
- функция count (*) подсчитывает количество строк в таблице результатов запроса.
Аргументом статистической функции может быть простое имя столбца, как в предыдущем примере, или выражение, как в следующем запросе
Каков средний процент выполнения плана в нашей компании?
SELECT AVG(100 * (SALES/QUOTA)) FROM SALESREPS
AVG(100 * (SALES/QUOTA))
102.60
При выполнении этого запроса СУБД создает временный столбец, содержащий значения 100 * (Sales/quota) для каждой строки таблицы salesreps, а затем вычисляет среднее значение временного столбца.
· сложные запросы
ОБЪЕДИНЕНИЕ ТАБЛИЦ
Одна из наиболее важных особенностей запросов SQL - это их способность определять связи между многочисленными таблицами и выводить информацию из них в терминах этих связей, всю внутри одной команды. Этот вид операции называется - объединением, которое является одним из видов операций в реляционных базах данных. Используя объединения, мы непосредственно связываем информацию с любым номером таблицы, и таким образом способны создавать связи между сравнимыми фрагментами данных. При объединении, таблицы представленные списком в предложении FROM запроса, отделяются запятыми. Предикат запроса может ссылаться к любому столбцу любой связанной таблицы и, следовательно, может использоваться для связи между ими. Обычно, предикат сравнивает значения в столбцах различных таблиц чтобы определить, удовлетворяет ли WHERE установленному условию.
ИМЕНА ТАБЛИЦ И СТОЛБЦОВ
Полное имя столбца таблицы фактически состоит из имени таблицы, сопровождаемого точкой и затем именем столбца. Имеются несколько примеров имен:
Salers.snum
Salers.city
Orders.odate
До этого, вы могли опускать имена таблиц потому что вы запрашивали только одну таблицу одновременно, а SQL достаточно интеллектуален чтобы присвоить соответствующий префикс, имени таблицы. Даже когда вы делаете запрос многочисленных таблиц, вы еще можете опускать имена таблиц, если все ее столбцы имеют различные имена. Но это не всегда так бывает. Например, мы имеем две типовые таблицы со столбцами называемыми city. Если мы должны связать эти столбцы(кратковременно), мы будем должны указать их с именами Salers.city или Customers.city, чтобы SQL мог их различать.
СОЗДАНИЕ ОБЬЕДИНЕНИЯ
Предположим что вы хотите поставить в соответствии вашему продавцу ваших заказчиков в городе в котором они живут, поэтому вы увидите все комбинации продавцов и заказчиков для этого города.
SELECT Customers.cname, Salespeople.sname,
Salespeople.city
FROM Salespeople, Customers
WHERE Salespeople.city = Customers.city;
Что SQL в основном делает в объединении - так это исследует каждую комбинацию строк двух или более возможных таблиц, и проверяет эти комбинации по их предикатам. В предыдущем примере, требовалась строка продавца Peel из таблицы Продавцов и объединение ее с каждой строкой таблицы Пользователей, по одной в каждый момент времени. Если комбинация производит значение которое делает предикат верным, и если поле city из строк таблиц Заказчика равно London, то Peel - это то запрашиваемое значение которое комбинация выберет для вывода. То же самое будет затем выполнено для каждого продавца в таблице Продавцов (у некоторых из которых не было никаких заказчиков в этих городах).
ОБЪЕДИНЕНИЕ ТАБЛИЦ ЧЕРЕЗ СПРАВОЧНУЮ ЦЕЛОСТНОСТЬ
Эта особенность часто используется просто для эксплуатации связей встроенных в базу данных. В предыдущем примере, мы установили связь между двумя таблицами в объединении. Это прекрасно. Но эти таблицы, уже были соединены через snum поле. Используя объединение можно извлекать данные в терминах этой связи. Например, чтобы показать имена всех заказчиков соответствующих заказов:
SELECT Orders.odate, Salespeople.sname
FROM Orders, Salespeople
WHERE Salespeople.snum = Orders.snum;
ОБЪЕДИНЕНИЯ ТАБЛИЦ ПО РАВЕНСТВУ ЗНАЧЕНИЙ В СТОЛБЦАХ И ДРУГИЕ ВИДЫ ОБЪЕДИНЕНИЙ
Объединения которые используют предикаты основанные на равенствах называются - объединениями по равенству. Все наши примеры в этой главе до настоящего времени, относились именно к этой категории, потому что все условия в предложениях WHERE базировались на математических выражениях использующих знак равно (=). Строки 'city = 'London' и 'Salespeople.snum = Orders.snum ' - примеры таких типов равенств найденных в предикатах. Объединения по равенству - это вероятно наиболее общий вид объединения, но имеются и другие. Вы можете, фактически, использовать любой из реляционных операторов в обьединении.
SELECT sname, cname FROM Salespeople, Customers
WHERE sname < cname AND rating < 200;
ОБЪЕДИНЕНИЕ БОЛЕЕ ДВУХ ТАБЛИЦ
SELECT onum, cname, Orders.cnum, Orders.snum
FROM Salespeople, Customers,Orders
WHERE Customers.city < > Salespeople.city
AND Orders.cnum = Customers.cnum
AND Orders.snum = Salespeople.snum;
ОБЪЕДИНЕНИЕ ТАБЛИЦЫ С СОБОЙ ПСЕВДОНИМЫ
Синтаксис команды для объединения таблицы с собой, тот же что и для объединения многочисленых таблиц, в одном экземпляре. Когда вы объединяете таблицу с собой, все повторяемые имена столбца, заполняются префиксами имени таблицы. Чтобы ссылаться к этим столбцам внутри запроса, вы должны иметь два различных имени для этой таблицы.
SELECT first.cname, second.cname, first.rating
FROM Customers first, Customers second
WHERE first.rating = second.rating;








