 2015-10-13
2015-10-13 3761
3761Коэффициент детерминации (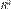 - R-квадрат) — это доля дисперсии зависимой переменной, объясняемая рассматриваемой моделью зависимости, то есть объясняющими переменными. Более точно — это единица минус доля необъяснённой дисперсии (дисперсии случайной ошибки модели, или условной по факторам дисперсии зависимой переменной) в дисперсии зависимой переменной. Его рассматривают как универсальную меру связи одной случайной величины от множества других. В частном случае линейной зависимости
- R-квадрат) — это доля дисперсии зависимой переменной, объясняемая рассматриваемой моделью зависимости, то есть объясняющими переменными. Более точно — это единица минус доля необъяснённой дисперсии (дисперсии случайной ошибки модели, или условной по факторам дисперсии зависимой переменной) в дисперсии зависимой переменной. Его рассматривают как универсальную меру связи одной случайной величины от множества других. В частном случае линейной зависимости 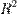 является квадратом так называемого множественного коэффициента корреляции между зависимой переменной и объясняющими переменными. В частности, для модели парной линейной регрессии коэффициент детерминации равен квадрату обычного коэффициента корреляции между y и x.
является квадратом так называемого множественного коэффициента корреляции между зависимой переменной и объясняющими переменными. В частности, для модели парной линейной регрессии коэффициент детерминации равен квадрату обычного коэффициента корреляции между y и x.
Истинный коэффициент детерминации модели зависимости случайной величины y от факторов x определяется следующим образом:
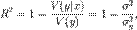
где 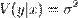 — условная (по факторам x) дисперсия зависимой переменной или дисперсия случайной ошибки модели.
— условная (по факторам x) дисперсия зависимой переменной или дисперсия случайной ошибки модели.
В данном определении используются истинные параметры, характеризующие распределение случайных величин. Если использовать выборочную оценку значений соответствующих дисперсий, то получим формулу для выборочного коэффициента детерминации (который обычно и подразумевается под коэффициентом детерминации):
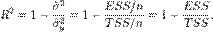
где 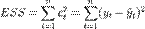 -сумма квадратов остатков регрессии,
-сумма квадратов остатков регрессии, 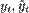 - фактические и расчетные значения объясняемой переменной.
- фактические и расчетные значения объясняемой переменной.
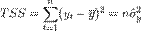 - общая сумма квадратов.
- общая сумма квадратов.
В случае линейной регрессии с константой 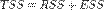 , где
, где 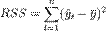 — объяснённая сумма квадратов, поэтому получаем более простое определение в этом случае — коэффициент детерминации — это доля объяснённой суммы квадратов в общей:
— объяснённая сумма квадратов, поэтому получаем более простое определение в этом случае — коэффициент детерминации — это доля объяснённой суммы квадратов в общей:
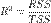
Необходимо подчеркнуть, что эта формула справедлива только для модели с константой, в общем случае необходимо использовать предыдущую формулу.
Интерпретация:
1. Коэффициент детерминации для модели с константой принимает значения от 0 до 1. Чем ближе значение коэффициента к 1, тем сильнее зависимость. При оценке регрессионных моделей это интерпретируется как соответствие модели данным. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50% (в этом случае коэффициент множественной корреляции превышает по модулю 70%). Модели с коэффициентом детерминации выше 80% можно признать достаточно хорошими (коэффициент корреляции превышает 90%). Значение коэффициента детерминации 1 означает функциональную зависимость между переменными.
2. При отсутствии статистической связи между объясняемой переменной и факторами, статистика 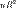 для линейной регрессии имеет асимптотическое распределение
для линейной регрессии имеет асимптотическое распределение 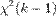 , где
, где 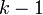 — количество факторов модели (см. тест множителей Лагранжа). В случае линейной регрессии с нормально распределёнными случайными ошибками статистика
— количество факторов модели (см. тест множителей Лагранжа). В случае линейной регрессии с нормально распределёнными случайными ошибками статистика 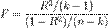 имеет точное (для выборок любого объёма) распределение Фишера
имеет точное (для выборок любого объёма) распределение Фишера 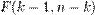 (см. F-тест). Информация о распределении этих величин позволяет проверить статистическую значимость регрессионной модели исходя из значения коэффициента детерминации. Фактически в этих тестах проверяется гипотеза о равенстве истинного коэффициента детерминации нулю.
(см. F-тест). Информация о распределении этих величин позволяет проверить статистическую значимость регрессионной модели исходя из значения коэффициента детерминации. Фактически в этих тестах проверяется гипотеза о равенстве истинного коэффициента детерминации нулю.
Дисперсионный анализ применяют для изучения влияния качественных признаков на количественную переменную. Например, пусть имеются k выборок результатов измерений количественного показателя качества единиц продукции, выпущенных на k станках, т.е. набор чисел (x 1(j), x 2(j), …, x n(j)), где j – номер станка, j = 1, 2, …, k, а n – объем выборки. В распространенной постановке дисперсионного анализа предполагают, что результаты измерений независимы и в каждой выборке имеют нормальное распределение N (m (j), σ2) с одной и той же дисперсией. Хорошо разработаны и непараметрические постановки.
Проверка однородности качества продукции, т.е. отсутствия влияния номера станка на качество продукции, сводится к проверке гипотезы
H 0: m (1) = m (2) = … = m (k).
В дисперсионном анализе разработаны методы проверки подобных гипотез. Теория дисперсионного анализа и расчетные формулы рассмотрены в специальной литературе.
Гипотезу Н 0 проверяют против альтернативной гипотезы Н 1, согласно которой хотя бы одно из указанных равенств не выполнено. Проверка этой гипотезы основана на следующем «разложении дисперсий», указанном Р.А.Фишером:
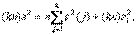 (7)
(7)
где s 2 – выборочная дисперсия в объединенной выборке, т.е.
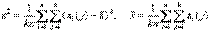
Далее, s 2(j) – выборочная дисперсия в j -ой группе,
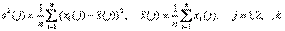
Таким образом, первое слагаемое в правой части формулы (7) отражает внутригрупповую дисперсию. Наконец, 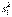 - межгрупповая дисперсия,
- межгрупповая дисперсия,
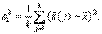
Область прикладной статистики, связанную с разложениями дисперсии типа формулы, называют дисперсионным анализом. В качестве примера задачи дисперсионного анализа рассмотрим проверку приведенной выше гипотезы Н 0в предположении, что результаты измерений независимы и в каждой выборке имеют нормальное распределение N (m (j), σ2) с одной и той же дисперсией. При справедливости Н 0 первое слагаемое в правой части формулы (7), деленное на σ2, имеет распределение хи-квадрат с k (n -1) степенями свободы, а второе слагаемое, деленное на σ2, также имеет распределение хи-квадрат, но с (k -1) степенями свободы, причем первое и второе слагаемые независимы как случайные величины. Поэтому случайная величина
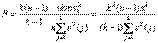
имеет распределение Фишера с (k -1) степенями свободы числителя и k (n -1) степенями свободы знаменателя. Гипотеза Н 0 принимается, если F < F 1-α, и отвергается в противном случае, где F 1-α – квантиль порядка 1-α распределения Фишера с указанными числами степеней свободы. Такой выбор критической области определяется тем, что при Н 1 величина F безгранично увеличивается при росте объема выборок n. Значения F 1-α берут из соответствующих таблиц.
Разработаны непараметрические методы решения классических задач дисперсионного анализа, в частности, проверки гипотезы Н 0.

