 2018-02-14
2018-02-14 4508
4508Полезность группировки
Данные, полученные в результате выборки, представляют собой «сырой» материал. Обычно перед тем, как приступить к вычислению характеристик выборки, его подвергают предварительной обработке. Наиболее распространенным методом такой обработки является ранжирование (группировка, классификация) данных. Эта процедура состоит в том, что мы все данные разбиваем на группы (ранги), и в дальнейшем всем результатам, отнесенным к одной группе, присваивается одно и то же значение (один и тот же ранг, если речь идет о качественном признаке). Например, так происходит при шитье на фабрике мужских костюмов – всех мужчин, чей рост находится в диапазоне 168-178 см., относят к одной группе(2-й рост) и всех их рассматривают как людей одного роста: 173см.
Этот метод применяется отнюдь не только в тех случаях, когда необходимость группировки данных диктуется потребностями стандартизации. Так поступают в очень многих случаях поскольку такой подход не только упрощает процедуру расчета, но и позволяет снизить влияние случайных небольших ошибок.
При разбиении всего множества вариант на группы (классы, ранги) стирается разница между дискретными и непрерывными величинами. Отметим сразу, что при работе с реальными данными непрерывных случайных величин не существует уже хотя бы потому, что любые измерения производятся с некоторой точностью, а значит любая непрерывная величина в результатах опыта предстает как дискретная, и в роли минимально возможного различия (шага дискретизации) выступает цена деления прибора.
С другой стороны, если максимальное число возможных значений дискретной случайной величины (максимальное минус минимальное значение, деленное на шаг измерения) очень велико, принципиальное различие между дискретной и непрерывной случайной величиной исчезает.[5] Т.е. практически при работе с конкретными данными имеет смысл говорить не о непрерывных и дискретных величинах, а о совокупностях данных с малым и большим числом градаций.
Способы разбиения и границы интервалов
 Когда мы приступаем к разбиению данных на группы (классификации данных), прежде всего мы должны выбрать количество групп данных, если, разумеется, это количество не продиктовано самим смыслом задачи, как происходит в случае, скажем, классификации людей по размеру обуви. Выбирая количество групп данных следует руководствоваться здравым смыслом, следя за тем, чтобы количество элементов в группе не было слишком малым,[6] а общее число групп не было слишком большим. Смысл слов «слишком» диктуется целью обработки данных и опытом исследователя. Так, указанные выше ограничения направлены на то, чтобы избежать излишней дробности представления данных, но конечно следует помнить и о том, чтобы вместе с водой не выплеснуть и «ребенка» - не слить в одну группу слишком разные данные, реально существующие существенные различия должны быть сохранены.
Когда мы приступаем к разбиению данных на группы (классификации данных), прежде всего мы должны выбрать количество групп данных, если, разумеется, это количество не продиктовано самим смыслом задачи, как происходит в случае, скажем, классификации людей по размеру обуви. Выбирая количество групп данных следует руководствоваться здравым смыслом, следя за тем, чтобы количество элементов в группе не было слишком малым,[6] а общее число групп не было слишком большим. Смысл слов «слишком» диктуется целью обработки данных и опытом исследователя. Так, указанные выше ограничения направлены на то, чтобы избежать излишней дробности представления данных, но конечно следует помнить и о том, чтобы вместе с водой не выплеснуть и «ребенка» - не слить в одну группу слишком разные данные, реально существующие существенные различия должны быть сохранены.
Когда мы осуществляем группировку, мы фактически все множество возможных значений разбиваем на интервалы, и все значения, попавшие в один интервал, заменяем одним стандартным значением – центром интервала. При этом границы интервала определяются как средние арифметические между величинами двух соседних центров.
Отметим, что при группировке количественных характеристик, центральные значения групп всегда образуют прогрессию. Однако не всегда эта прогрессия арифметическая, иногда разумно считать что центры групп образуют геометрическую прогрессию. Последнее встречается в тех случаях, когда отношение наименьшего и наибольшего значения очень велико (ситуация большого динамического диапазона). Кроме того, геометрическая прогрессия для центров групп достаточно часто встречается в экономике потому, что для экономических задач весьма характерно «процентное» рассмотрение: результат вычисляется как некая доля исходных данных (прибыль, доход, налог – все они описываются чаще всего как доли или проценты). В случае, когда интервалы образуют арифметическую прогрессию, мы говорим о равномерной шкале, а в случае геометрической прогрессии о логарифмической шкале.
Рассмотрим примеры.
Пусть нам дана таблица данных
| Значение Х | <210 | 210 | 270 | 330 | 390 | >390 |
| Количество n | 7 | 23 | 45 | 42 | 28 | 15 |
Легко заметить, что наши стандартизованные значения Х образуют арифметическую прогрессию, т.е. перед нами равномерная шкала. В группу со стандартным значением 270 при этом попали все значения, у которых в ходе опыта были получены результаты, лежащие в диапазоне 240< х < 300 (эта ситуация изображена на Рис.1, верхняя линия)
Пусть теперь наша таблица данных выглядит так:
| Значение Х | <210 | 210 | 280 | 375 | 500 | >500 |
| Количество n | 7 | 23 | 45 | 42 | 28 | 15 |
Здесь вполне очевидно, что центры групп образуют геометрическую прогрессию со знаменателем 1,33 (логарифмическая шкала). В группу со стандартным значением 280 при этом попали все значения, у которых в ходе опыта были получены результаты, лежащие в диапазоне 240< х < 320 (эта ситуация изображена на Рис.1, нижняя линия). Границы интервалов определяются не как средние арифметические, а как средние геометрические двух соседних стандартов; так граница между классами «210» и «280» равна  = 242,7 @ 240; граница между классами «500» и «375» равна
= 242,7 @ 240; граница между классами «500» и «375» равна  @ 430. Обычно и при назначении стандартных значений групп (центров интервалов), и при вычислении границ групповых интервалов не следуют строго закону прогрессии, а прибегают к округлению значений.
@ 430. Обычно и при назначении стандартных значений групп (центров интервалов), и при вычислении границ групповых интервалов не следуют строго закону прогрессии, а прибегают к округлению значений.
Отдельно следует сказать о полубесконечных интервалах, очень часто именно такими являются первый и последний интервалы. Т.е. в первый интервал попадают все значения, меньшие стандарта для первого интервала, в последний – все значения большие стандарта для последнего интервала. Так они показаны в большинстве книг.
ВНИМАНИЕ!! Однако здесь содержится очевидная неточность. Указанные в таблице значения представляют ведь не границы, а центры интервалов. В частности, значение 210 приписывается всем результатам, которые оказались в диапазоне от 180 до 240. Следовательно, в группу «<210» попадают все результаты, меньшие 180, а вовсе не меньшие 210 – название противоречит сути.
Далее какое значение следует приписать первой группе?
Для первой таблицы разумно поступить так же, как и для всех данных в этой таблице – стандартное значение меньше правого края ровно на 30 единиц. Это значит, что при вычислении характеристик всем элементам этой группы приписывают значение 150.
Для второй таблицы ситуация несколько сложнее. В первую группу как и в предыдущем случае попадают все значения, меньшие 180. Но вот со стандартом (значением, которое присваивается всем элементам) тут сложнее: т.к. масштаб у нас логарифмический, то ширина интервала у всех групп разная, однако мы знаем, что стандартные значения образуют геометрическую прогрессию с частным 1,33. Значит стандарт для левого полубесконечного интервала получается делением стандарта первого конечного интервала на 1,33, получим: 210: 1,33 @ 160.
Для правого полубесконечного интервала аналогично получим: стандартное, т.е. приписываемое всем элементам интервала значение составляет 500×1,33 @ 670.
Т.е. в логарифмической шкале стандарты для крайних интервалов вычисляются исходя из ближайшего стандартного значения путем умножения или деления ближайшего значения на знаменатель прогрессии.
Распределение вариант и распределение средних. Выборочные характеристики как оценки характеристик генеральной совокупности. Свойства оценок: несмещенность, состоятельность, эффективность.
Обычно ситуация не бывает столь простой, как мы ее представили в п.1. Чаще всего мы не располагаем всей генеральной совокупностью данных и поэтому лишены возможности точно вычислить основные характеристики генеральной совокупности: генеральное среднее µ и стандартное отклонение σ. Приходится производить некоторые выборки из генеральной совокупности и на основании полученных таким образом данных вычислять не сами характеристики генеральной совокупности, а некие их оценки.
Обычно используемые оценки генерального среднего, генеральной дисперсии и стандартного отклонения по выборочным данным описываются такими формулами:
 (1.3)
(1.3)
Обратите внимание: в этих формулах n есть объём выборки, а не генеральной совокупности.
Разумеется, желательно, чтобы наши формулы давали «хорошие» оценки, но для этого прежде всего следует ввести некие характеристики оценок, позволяющие судить, какие оценки хороши, а какие нет. Обычно используют три таких характеристики: несмещённость, состоятельность и эффективность.
Несмещённость. Если матожидание оценки совпадает с генеральным средним (или матожиданием случайной величины), оценка называется несмещенной.
Состоятельность. Если предел оценки по вероятности равен оцениваемому значению, то оценка называется состоятельной. Несколько упрощая ситуацию, можно сказать, что состоятельной называется такая оценка, которая дает практически точное значение, если используемая выборка достаточно велика и представительна.
Эффективность оценки определяется не предельным, а актуальным значением разброса оценок: из двух оценок величины более эффективна та у которой меньше дисперсия, а значит ее плотность распределения более «сжата».
Для того, чтобы правильно понимать смысл приведенных здесь характеристик нужно отчетливо представлять себе следующее. Как только мы начинаем рассматривать выборку, хотя бы только одну, мы сразу должны рассматривать ситуацию с точки зрения двух распределений: исходного распределения значений переменной х (распределение вариант) и распределения выборочных средних. Последнее трактуется следующим образом.
 Пусть мы сделали не одну, а очень много выборок одинакового объёма n из одной и той же генеральной совокупности и для каждой из них вычислили среднее значение. Вполне очевидно, что различные выборки – пусть они одного объема, осуществлялись по одному принципу и в одинаковых условиях – вот у таких схожих выборок средние величины и стандартные отклонения окажутся все-таки различными. Причем различия эти продиктованы случайными причинами, поскольку случайным образом отбирались представители генеральной совокупности, попавшие в выборку, а это означает, что сами выборочные средние и выборочные стандартные отклонения являются случайными величинами. Поскольку такие выборочные средние сами есть случайные величины, мы можем построить распределение выборочных средних по данным многих выборок.
Пусть мы сделали не одну, а очень много выборок одинакового объёма n из одной и той же генеральной совокупности и для каждой из них вычислили среднее значение. Вполне очевидно, что различные выборки – пусть они одного объема, осуществлялись по одному принципу и в одинаковых условиях – вот у таких схожих выборок средние величины и стандартные отклонения окажутся все-таки различными. Причем различия эти продиктованы случайными причинами, поскольку случайным образом отбирались представители генеральной совокупности, попавшие в выборку, а это означает, что сами выборочные средние и выборочные стандартные отклонения являются случайными величинами. Поскольку такие выборочные средние сами есть случайные величины, мы можем построить распределение выборочных средних по данным многих выборок.
Распределение средних отличается такими важными особенностями:
а) Распределение средних при росте объёма выборки по форме стремится к нормальному распределению, независимо от того, каким по форме было распределение вариант. Т.е. оно постепенно становится близким к нормальному, даже если исходное распределение вариант сильно ассиметрично (например, экспоненциальное). Однако понятно, что для гладких, одновершинных и симметричных распределений практическая близость к нормальному будет наступать раньше, при меньших объемах выборки;
б) чем больше объем выборки n, тем более вытянутым по вертикали и сжатым по горизонтали оказывается кривая распределения выборочных средних, на рис.2б показаны кривые распределения для выборок из одной и той же генеральной совокупности, содержащих по 5 и по 12 элементов;
в) отметим, что выборочное среднее 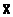 является несмещенной и эффективной оценкой генерального среднего µ.
является несмещенной и эффективной оценкой генерального среднего µ.
 Несмещенность оценки означает, что если по кривой распределения выборочных средних найти для случайной величины ее матожидание
Несмещенность оценки означает, что если по кривой распределения выборочных средних найти для случайной величины ее матожидание  , то оно совпадет с матожиданием генеральной совокупности µ (на рис.2б распределение вариант симметрично, симметричны и оба распределения средних; ось симметрии у всех трех распредлений общая, что и указывает на равенство = µ). Можно показать, что существует много несмещенных оценок для матожидания генеральной совокупности µ, однако они обладают различной эффективностью.
, то оно совпадет с матожиданием генеральной совокупности µ (на рис.2б распределение вариант симметрично, симметричны и оба распределения средних; ось симметрии у всех трех распредлений общая, что и указывает на равенство = µ). Можно показать, что существует много несмещенных оценок для матожидания генеральной совокупности µ, однако они обладают различной эффективностью.
А вот эффективность как оценки µ означает, что среди всех несмещенных оценок µ именно имеет наименьшую дисперсию.
Таким образом, несмещенной и эффективной оценкой стандартного отклонения  в распределении средних является величина
в распределении средних является величина  ,[7] т.е. матожидание величины совпадает с : M[ ] = , причем из всех оценок с таким матожиданием имеет наименьшую дисперсию
,[7] т.е. матожидание величины совпадает с : M[ ] = , причем из всех оценок с таким матожиданием имеет наименьшую дисперсию
г) Стандартное отклонение в распределении средних всегда будет меньше стандартного отклонения для распределения вариант (встретить на улице человека выше 190см много вероятнее, чем встретить 20 человек, средний рост которых более 190см); причем чем больше объем выборки, тем меньше стандартное отклонение в распределении средних; точная зависимость величины стандартного отклонения от объема выборки приведена ниже
Итак, пусть мы располагаем данными полученными всего из одной выборки, все равно мы можем получить оценку характеристик генеральной совокупности на основе этой единственной выборки. При этом мы рассматриваем эти данные двояко: как описание нашей выборки, представленное таблицей; по этой таблице мы можем вычислить и σ для данной выборки. И одновременно как одну из точек на кривой распределения , этот подход будет активно использоваться при построении доверительных интервалов.
Отметим еще одно важное следствие. Выборочное среднее является несмещенной оценкой генерального среднего µ, а вот выборочное стандартное отклонение  является смещенной оценкой генерального стандартного отклонения, несмещенной оценкой (см. 1.3) является s:
является смещенной оценкой генерального стандартного отклонения, несмещенной оценкой (см. 1.3) является s:  ; нетрудно заметить, что
; нетрудно заметить, что 

