 2014-02-24
2014-02-24 1471
1471В технике передачи дискретных сообщений приходится решать задачу сопряжения (согласования) источников дискретных сообщений с каналом. Решение этой задачи связано с поиском путей передачи информации со скоростью, возможно более близкой к предельной.
Для большинства источников дискретных сообщений, характеризующихся информационной избыточностью, максимальная скорость передачи может быть достигнута в результате устранения избыточности в передаваемом сообщении. Процедуры, направленные на устранение избыточности источника дискретных сообщений, передаваемых по каналу без помех, называются эффективным кодированием.
Пусть имеется сообщение, записанное с помощью букв некоторого первичного алфавита 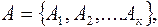 содержащего К букв.
содержащего К букв.
Требуется закодировать это сообщение, т.е. указать правило сопоставления каждой букве первичного алфавита последовательности «0» и «1», образующих вторичный алфавит.
При передаче дискретных сообщений по каналам связи буквы алфавита обычно отображаются кодовыми комбинациями постоянной длины (равномерное кодирование). Длина кодовой комбинации n выбирается из условия 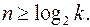
Применение эффективного кодирования позволяет уменьшить среднее число l двоичных символов на букву сообщения:
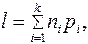 (3.1)
(3.1)
где 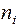 -длина кодовой комбинации, отображающей i-ю букву;
-длина кодовой комбинации, отображающей i-ю букву;
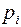 -вероятность появления i-ой буквы.
-вероятность появления i-ой буквы.
Уменьшение средней длины кодовой комбинации, отображающей букву сообщения, позволяет увечить скорость передачи.
Эффективное кодирование базируется на теореме Шеннона для каналов без шума.
Согласно этой теореме (основной теореме кодирования), сообщения, составленные из букв некоторого алфавита, можно закодировать так, что среднее число l двоичных символов, приходящихся на букву, будет сколь угодно близко к энтропии источников этих сообщений Н(А), но не менее этой величины, т.е.
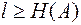 (3.2)
(3.2)
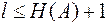
Под энтропией дискретного источника Н(А) понимается среднее количество информации, приходящееся на одну букву сообщения:
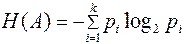 (3.3)
(3.3)
Для построения эффективных кодов наибольшее распространение нашли методики Шеннона-Фано и Хаффмена.
3.2. Метод Шеннона-Фано
1. Все К букв алфавита располагаются в один столбец в порядке убывания их вероятностей.
2. Эти буквы разбиваются на две группы: верхнюю и нижнюю так, чтобы суммы вероятностей в каждой из групп были по возможности ближе друг к другу.
3. Для букв верхней группы в качестве первого символа кодовой комбинации выбирается “ 1 ”, а для нижней - “ 0 ”.
4. Вновь каждую из полученных групп делят на две части с близкими, по возможности, суммарными вероятностями.
5. Верхним частям вновь образованных групп присваивается “ 1 ”, а нижним — “ 0 ”. Эти значения элементов считаются вторыми разрядами формируемых кодовых комбинаций.
Эти процедуры повторяются до тех пор, пока в каждой группе останется по одной букве.
Построение кода Шеннона-Фано для ансамбля из 8 букв приведено в
табл. 3.1.
При равномерном кодировании 8-ми букв кодовые комбинации содержат по три двоичных разряда. При использовании кода Шеннона-Фано средняя длина кодовой комбинации составляет:
к
l =åni pi=0,2·2+0,2· 3+0,15·3+0,13·3+0,12·3+0,10·3+0,07·4+0,03·4=2,9
i=1Это меньше, чем при равномерном кодировании и не очень далеко от энтропии к
Н(А)=-å рi log2pi=2,806 бит/буква. (3.4)
i=1
3.3. Метод Хаффмена
1. Буквы алфавита выписываются столбцом в порядке убывания вероятностей.
2. Находится сумма вероятностей последних двух букв.
3. Вероятности букв, не участвующих в объединении, и полученная суммарная вероятность снова располагаются столбцом в порядке убывания.
Второй и третий этапы повторяются до тех пор, пока суммарная вероятность не будет равна единице.
Таблица 3.1.Построение кода Шеннона - Фано
| Буквы | Рi | Деление букв на группы | Код Шеннона-Фано |
| А1 | 0,20 | ||
| А2 | 0,20 | ||
| А3 | 0,15 | ||
| А4 | 0,13 | ||
| А5 | 0,12 | ||
| А6 | 0,10 | ||
| А7 | 0,07 | ||
| А8 | 0,03 |
Построение кода Хаффмена для ансамбля из 8 букв приведено в табл. 3.2.
Таблица 3.2. Построение кода Хаффмена
| Буквы | Pi | Вспомогательные столбцы |
| 1 2 3 4 5 6 7 | ||
| А1 | 0,20 | 0,20 0,20 0,25 0,35 0,40 0,60 1 |
| А2 | 0,20 | 0,20 0,20 0,20 0,25 0,35 0,04 |
| А3 | 0,15 | 0,15 0,20 0,20 0,20 0,25 |
| А4 | 0,13 | 0,13 0,15 0,20 0,20 |
| А5 | 0,12 | 0,12 0,13 0,15 |
| А6 | 0,10 | 0,10 0,12 |
| А7 | 0,07 | 0,10 |
| А8 | 0,03 |
Кодовое дерево строится следующим образом (рис.3.1). Сначала находятся буквы с наименьшими вероятностями 0,07 (A7) и 0,03 (A8), затем от них проводятся линии к точке, изображающей “укрупненный” символ с суммарной вероятностью 0,10. На рисунке эта процедура обозначена цифрой I. Затем берутся две наименьшие вероятности со значением 0,10 и получают новый “укрупненный” символ с вероятностью 0,20 (процедура I I). Теперь наименьшие вероятности имеют символы А4 (0,13) и А5 (0,12). Соединяя их линиями формируют новый символ с суммарной вероятностью 0,25 (процедура I I I).
Эти процедуры повторяются до тех пор, пока линии от основных и “укрупненных” символов не соединятся в точке с суммарной вероятностью, равной 1. Верхнюю линию обозначают цифрой “ 1 ”, а нижнюю “ 0 ”. Любая кодовая комбинация представляет собой последовательность “ 1 ” и “ 0 ”, которые встречаются на пути от вершины дерева с вероятностью 1 к точке, изображающей нужную букву.
Сравнение рассмотренных методик построения эффективных кодов позволяет сделать вывод, что методика Хаффмена более удобна для практического использования. В общем случае код Хаффмена экономичнее кода Шеннона-Фано.
| Буква | pi | Кодовое дерево | Код | ni | nipi |
| А1 | 0,2 | 0,4 | |||
| А2 | 0,2 | 0,6 | |||
| А3 | 0,15 | 0,45 | |||
| А4 | 0,13 | 0,39 | |||
| А5 | 0,12 | 0,36 | |||
| А6 | 0,10 | 0,3 | |||
| А7 | 0,07 | 0,28 | |||
| А8 | 0,03 | 0,12 |
Рис. 3.1 Кодовое дерево.
Нетрудно заметить, что сокращение средней длины кодовой комбинации эффективного кода по сравнению с равномерными кодами достигается благодаря присвоению более вероятным буквам коротких кодовых комбинаций, а менее вероятным буквам — более длинных кодовых комбинаций. Таким образом, эффективность рассматриваемых кодов связана с различием в числе символов кодовых комбинаций. Это приводит к определенным трудностям при декодировании. Конечно, для различия кодовых комбинаций можно ставить разделительный символ, но при этом существенно снижается эффект, который достигается использованием неравномерных кодов, так как средняя длина кодовой комбинации, по существу, увеличивается на один символ. Более разумным является обеспечение однозначного декодирования без введения разделительных символов. Для этого эффективный код строят так, чтобы ни одна комбинация кода не совпадала с первыми символами более длинной кодовой комбинации. Коды, удовлетворяющие этому условию, называются префиксными.
Коды, представляющие первичные алфавиты с неравновероятными символами, имеющие минимальную среднюю длину кодового слова, называются оптимальными неравномерными кодами (ОНК).
Максимально эффективными будут те ОНК, у которых энтропия дискретного источника Н(А) численно равна среднему числу двоичных символов на букву l:
Н(А)= l (3.5)
или с учетом (3.1) и (3.3)
к к
ånipi=-åpilog2pi (3.6)
i=1 i=1
Очевидно, что это равенство будет иметь место только тогда, когда
ni=-log2pi=log2(1/pi) (3.7)
Величина l точно равна Н(А), если вероятности рi представляют собой целочисленные отрицательные степени двойки. Если это не выполняется, то l> Н(А) и согласно основной теореме кодирования Шеннона для каналов без шумов средняя длина кодовой комбинации приближается к энтропии источника сообщений по мере укрупнения кодируемых блоков.
Для оценки эффективности ОНК предназначены следующие характеристики.
1. Коэффициент статистического сжатия.
Нmax (А) log2К

 l = (3.8)
l = (3.8)
к åni pi
i=1
Он характеризует уменьшение количества двоичных символов на букву алфавита при применении ОНК по сравнению с применением методов нестатистического кодирования.
2. Коэффициент относительной эффективности.
Н(А)
 l =
l =
Кэ (3.9)
Этот коэффициент показывает, насколько устраняется статистическая избыточность передаваемого сообщения.
Методы устранения избыточности позволяют эффективно использовать пропускную способность канала связи. Они полезны также в тех случаях, когда требуется хранить большой объем информации в различных запоминающих устройствах. Экономия в пропускной способности канала или в объеме запоминающего устройства приводит к снижению стоимости, сокращению размеров и веса аппаратуры. Рассмотренные методы кодирования получили применение при передаче факсимильных сообщений.

