 2014-02-09
2014-02-09 3599
3599Понятие образа.
Образ – это некоторое структурированное приближенное(!) описание изучаемого объекта, явления или процесса. Любой образ представляется некоторым набором признаков.
[Не следует путать два понятия: образ и объект (вид из окна – словесное описание видимого – картина-пейзаж). Чем большее число свойств и качеств объекта отражено в образе, тем полнее это описание, тем полнее этот образ характеризует описываемый объект. ]
Основное назначение образов – это их использование в процессе установления соответствия объектов, т.е. при доказательстве их идентичности, аналогичности, подобия, сходства и т.п., которое осуществляется путем сравнения (сопоставления). Два образа считаются подобными, если удается установить их соответствие.
Задача распознавания образов возникает в различных разделах ИИ, например, в понимании естественного языка компьютером, символьной обработке алгебраических выражений, экспертных системах, преобразовании и синтезе программ ЭВМ. Причем в различных задачах образу придается разный смысл.
|
|
|
Важным термином в теории РО является понятие «класса». [При получении некоторых характеристик объекта (создании образов) обычно происходит его отождествление с некоторым классом. Например, характеристики выхода из строя систем АЭС – класс опасных отказов или класс отказов, требующих определенного технического вмешательства, но не опасных.]
Классы – это объединения объектов, явлений или процессов, отличающиеся общими свойствами. При этом целью распознавания является отнесение объекта, представленного своим образом, к тому или иному заранее определенному классу.
[
]
Система распознавания – это сложная динамическая система, состоящая из совокупности технических средств получения и обработки информации и коллектива специалистов, обеспечивающих на основе определенных алгоритмов решение задачи классификации соответствующих объектов, явлений или процессов.
Задача 1:
Задача состоит в подробном и тщательном изучении объектов, для распознавания которых предназначена проектируемая система. Её цель – уяснить особенности изучаемых объектов и выяснить, что роднит и отличает их друг от друга. В решении этой задачи - главное найти все признаки, характеризующие существо распознаваемых объектов (явлений). Любые ограничения, любая неполнота приводят к ошибкам или полной невозможности правильной классификации объектов (явлений).
Но чтобы назначать признаки распознавания, необходимо, во-первых, понять, что не существует способов их автоматической генерации. На сегодня это под силу только человеку. Поэтому говорят, что выбор признаков - эвристическая операция. Во-вторых, выбор признаков можно осуществлять, имея представление об их общих свойствах. С этих позиций достаточно принять, что признаки могут подразделяться на детерминированные, вероятностные, логические и структурные.
|
|
|
Детерминированные признаки - это такие характеристики объектов или явлений, которые имеют конкретные и постоянные числовые значения.
Примерами детерминированных признаков могут быть, например, ТТХ бомбардировщиков и истребителей США (таблиц № 1).
Числовые значения признаков по каждому из самолетов можно интерпретировать как координаты точек, представляющих каждый самолет в 11-мерном пространстве признаков.
Таблица № 1
| Характеристики | Т и п ы с а м о л е т о в | ||||||||
| Бомбардировщики | Истребители | ||||||||
| В-1А | В-52 | В-57А | FB-111 | F - 4 E Фантом | F - 105 E Тандерчиф | F - 15 Игл | F - 100 D Суперсейбр | Хантер | |
| Экипаж (чел.) | |||||||||
| Vmax (км\ч) при H=15 км | |||||||||
| Vmin (км\ч) при H=0.3 км | |||||||||
| Потолок (м) | |||||||||
| Бомб.нагрузка (т) | 7.2 | 6.4 | - | 3.4 | 0.9 | ||||
| Макс.взлетная масса (т) | |||||||||
| Размах крыльев (м) | |||||||||
| Длина самолета (м) | |||||||||
| Кол-во двигателей | |||||||||
| Тяга двигателей (т) | 13.6 | 7.7 | 3.3 | 9.2 | 5.4 | 10.9 | 5.3 | 4.5 | |
| Дальность полета (км |
Распознавание осуществляется путем сравнения полученных размеров с имеющимися в базе данных характеристиками деталей.
Вероятностные признаки - это характеристики объекта (явления), носящие случайный характер. С такими признаками в основном и имеют дело в природе и технике.
Отличаются эти признаки тем, что в силу случайности соответствующей величины признак одного класса может принимать значения из области значений других классов, каждый из которых подлежит распознаванию в системе.
Если признак не может принять значений в области соответствующих значений для других классов, то, следовательно, имеем дело не с вероятностным, а с тем же детерминированным признаком. Это как раз подчеркивает, почему вероятностные системы являются системами более общего порядка.
Примеры вероятностных признаков распознавания:
· среднее значение мощности сигнала радиолокатора, отраженного от самолета (причина - изрезанность круговой диаграммы рассеяния сигнала радиолокатора самолетом и электронные и атмосферные шумы в том же радиолокационном диапазоне);
· размер листа растения (причины - отличия в питании, освещенности, влаги и т.п.);
· размер патологического изменения какого-либо органа человека (причины - различные стадии заболевания при его обнаружении, различные ракурсы и сечения наблюдений образования и т.п.) и т.д.
Логические признаки распознавания - это характеристики объекта или явления, представленные в виде элементарных высказываний об истинности (“да”, "нет” или “истина”, “ложь”).
Эти признаки не имеют количественного выражения, то есть являются качественными суждениями о наличии, либо об отсутствии некоторых свойств или составляющих у объектов или явлений.
Примеры логических признаков:
· наличие ТРД на самолете;
· боль в горле пациента;
· кашель;
· насморк;
· растворимость реактива и т.д.
Здесь по каждому признаку можно сказать только то, что он есть, либо его нет. К логическим можно отнести также такие признаки, у которых важна не величина признака у распознаваемого объекта, а лишь факт попадания или непопадания ее в заданный интервал. (например, крейсерская скорость самолета больше или меньше 2000 км/ч).
|
|
|
Структурные признаки - непроизводные (то есть, элементарные) элементы (символы), примитивы изображения объекта распознавания.
Примеры структурных признаков:
а)для изображения прямоугольника:
- горизонтальный отрезок прямой;
- вертикальный отрезок прямой.
б) для любого изображения на экране дисплея:
-пиксел.
В результате связей из непроизводных элементов (структурных признаков) образуется объект, аналогично тому, как предложения языка строятся путем соединения слов, в свою очередь состоящих из букв. В этом структурные методы проявляют аналогию с синтаксисом естественного языка. Отсюда структурные признаки носят еще название лингвистических или синтаксических.
Задача 2:
Эта задача заключается в первоначальной классификации объектов (явлений), подлежащих распознаванию т.е. в составление априорного алфавита классов.
Основное в данной задаче – выбор надлежащего принципа классификации. Для этого:
1-е - определяется, какие решения могут приниматься по результатам распознавания либо человеком, либо автоматической системой управления объектом (цель распознавания).
2-е - на основе определенной выше цели формулируются требования к системе распознавания, позволяющие выбрать принцип классификации.
3-е - составляется априорный алфавит классов объектов (явлений).
[
]
Однако, возможны ситуации, когда количество классов, по которым надежно распознаются некоторые объекты (явления), заранее неизвестно и должно определяться самой системой распознавания. Эта задача называется задачей кластеризации, в которой можно отказаться уже от эвристического подхода. Однако решение здесь достигается при выборе некоторых общих правил кластеризации, которые задает разработчик системы.
Задача 3:
Эта задача состоит в разработке априорного словаря признаков распознавания.
При разработке словаря признаков сталкиваются с рядом ограничений.
Ограничение 1. Оно состоит в том, что в словарь могут быть включены только признаки, относительно которых может быть получена априорная информация, достаточная для описания классов на языке этих признаков.
|
|
|
Ограничение 2. Это ограничение связано с нецелесообразностью включения в словарь всех признаков. Так, некоторые признаки, относительно которых хотя и имеется достаточный объём априорных данных, включать в словарь признаков нет смысла, поскольку они либо совсем бесполезны при решении задачи распознавания, либо весьма мало полезны. О таких признаках говорят, что они малоинформативны и не обладают достаточными разделительными свойствами.
Ограничение 3. Это ограничение связано с наличием или с возможностью создания технических средств наблюдений, обеспечивающих на основе проведения экспериментов определение предварительно отобранных признаков.
Эффективность СР в значительной мере определяется объёмом и качеством измерительной информации о распознаваемых объектах, что обуславливает необходимость создания таких средств наблюдений, которые позволяют с максимально возможной точностью определять наиболее информативные признаки.
Задача 4:
Задача состоит в описании классов объектов на языке априорного словаря признаков.
В рамках этой задачи необходимо каждому классу поставить в соответствие числовые параметры детерминированных и вероятностных признаков, значения логических признаков и предложения, составленные из структурных признаков-примитивов.
Значения этих параметров описаний можно получить из экспериментальных наблюдений, математических расчетов, результатов моделирования, извлечения из литературных источников.
Если признаки распознаваемых объектов - детерминированные, то описанием класса может быть точка в n -мерном пространстве детерминированных признаков из априорного словаря, сумма расстояний до которой от точек, представляющих объекты данного класса, минимальна.
[ Например, в таблице с ТТХ самолетов мы имеем дело с 11-мерным пространством признаков. Каждая координата - это одна какая-нибудь характеристика, например “экипаж”.
| Характеристики | Типы самолетов | |||||
| Бомбардировщики | Истребители | |||||
| В-1А | В-52 | В-57А | Фантом | Игл | Хантер | |
| Экипаж (чел.) |
Если рассматривать только одну координату “экипаж”, то точкой эталона для истребителей будет - 1, для бомбардировщиков - 4. Это точки, суммы расстояний которых от всех истребителей и всех бомбардировщиков, представляющих эти два класса, минимальны.
Точно также это можно сделать по всем 11 координатам (т.е. “потолок”, “размах крыльев”, ”бомбовая нагрузка “ и т.д.), в результате чего будем уже иметь дело с точками эталонов в 11-мерном пространстве.
]
Если признаки распознавания - логические, то для описания каждого класса необходимо, прежде всего, иметь полный набор элементарных логических высказываний A, B, C, входящих в состав априорного словаря, а также установить соответствие между набором значений приведенных признаков A, B, C и классами W1, W2,...Wm.
[
Например, необходимо распознавать два заболевания - обычная простуда и ангина (W1,W2), а в качестве логических признаков выберем:
А - повышенная температура (А=0 - нет, А=1 - да);
В - насморк (В=0 - нет, В=1 - да);
С - нарывы в горле (С=0 - нет, С=1 - да).
Тогда так называемое булево соотношение между классом W1 (обычное простудное заболевание) и значениями признаками (а эти значения - бинарные) выглядит так: 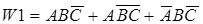
Здесь умножение, как вы знаете, соответствует логическому “И”, а сложение - “ИЛИ”.
Точно также для второго класса заболеваний получим следующее описание: 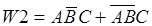
]
Если распределение объектов распознавания, представляемых числовыми значениями их признаков по областям соответствующего пространства вероятностное, то для описания классов необходимо определить характеристики этих распределений:
· функции плотности распределения вероятностей fi (x1,x2,....,xn), где x1.....xn - вероятностные признаки, i - номер класса;
· P(Wi) - априорная вероятность того, что объект, случайно выбранный из общей совокупности, окажется принадлежащим к классу Wi.
Для того чтобы получить fi (x1,x2,....,xn) и P(Wi) можно воспользоваться одним из трех способов: 1) экспериментальное определение по статистическим данным; 2) теоретический вывод; 3) моделирование.
Если признаки распознавания - структурные, то описанием каждого класса должен быть набор предложений (цепочек из непроизводных элементов с правилами соединения). Каждое из предложений класса - характеристика структурных особенностей объектов этого класса. [Пример – код Фримена???]
Задача 5:
Выбор алгоритма классификации, обеспечивающего отнесение распознаваемого объекта или явления к соответствующему классу.
Алгоритмы распознавания основываются на сравнении значений той или иной меры близости распознаваемого объекта с каждым классом. При этом если значение выбранной меры близости (сходства) L данного объекта w с каким-либо классом Wg достигает экстремума относительно значений ее по другим классам, то есть
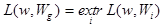
то принимается решение о принадлежности этого объекта классу Wg, т.е. w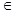 Wg.
Wg.
В алгоритмах распознавания, использующих детерминированные признаки в качестве меры близости, используется среднеквадратическое расстояние между данным объектом w и совокупностью объектов (w1,w2,....,wn), представляющих (описывающих) каждый класс. Так для сравнения с классом Wg это выглядит так
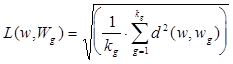
где kg - количество объектов, представляющих Wg -й класс.
При этом метод измерения расстояния между объектами d(w,wg) свободен для выбора. Так, если сравнивать непосредственно координаты, то
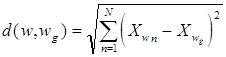
где N - размерность признакового пространства.
Если сравнивать угловые отклонения, то, рассматривая вектора, составляющими которых являются признаки распознаваемого объекта w и класса wg, будем иметь:
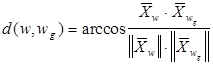
где ||Xw|| и ||Xwg|| - нормы соответствующих векторов.
В алгоритме распознавания, использующем детерминированные признаки можно учитывать и их веса Vj (устанавливать степень доверия или важности). Тогда рассмотренное среднеквадратическое расстояние принимает следующий вид:
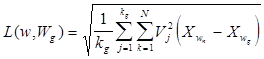
В алгоритмах распознавания, использующих вероятностные признаки, в качестве меры близости используется риск, связанный с решением о принадлежности объекта к классу Wi, где i - номер класса. (i=1,2,..,m.).
Пусть даны описания классов
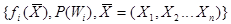
и риски правильных и ошибочных решений, представляющие собой элементы платежной матрицы вида:
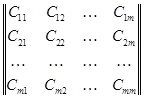
Здесь на главной диагонали расположены потери при правильных решениях. Обычно принимают Сii=0 или Cii<0.
По обеим сторонам от главной диагонали - потери при ошибочных решениях. В каждой системе эти потери свои, свойственные только ей.
Если вектор признаков распознаваемого объекта w - 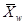 , то риск, связанный с принятием решения о принадлежности этого объекта к классу Wg, когда на самом деле он может принадлежать классам W1,W2,...,Wm, наиболее целесообразно определять как среднее значение потерь
, то риск, связанный с принятием решения о принадлежности этого объекта к классу Wg, когда на самом деле он может принадлежать классам W1,W2,...,Wm, наиболее целесообразно определять как среднее значение потерь
С1g, C2g,...,Cmg,
то есть, потерь, стоящих в g -ом столбце платежной матрицы.
Тогда этот средний риск можно записать:
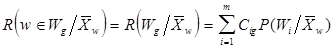
где P(Wi/Xw) - условная апостериорная вероятность того, что wWi в соответствии с теоремой гипотез или по формуле Байеса
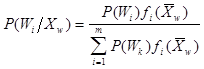
Вероятности и плотности, входящие в формулу - ни что иное, как характеристики описания классов в вероятностной системе.
Для алгоритмов, основанных на логических признаках, понятие “мера близости” не имеет смысла. Вспомним упрощенный пример, рассмотренный нами для логических признаков заболеваний (простой простуды и ангины).
Имея значения признаков А,B,C, достаточно подставить их в булевы соотношения между классами и признаками, чтобы сразу получить результат как истинность или ложность булевой функции описания того или иного класса.
Действительно, пусть признаки приняли следующие значения:
-Повышенная температура: A=1
-Насморк: B=0
-Нарывы в горле: C=1
Тогда подстановка их в булевы соотношения даст следующий результат:
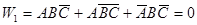
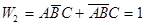
То есть, истинным является второе соотношение, соответствующее распознаванию ангины как диагностируемого класса из двух заболеваний.
Для алгоритмов, основанных на структурных (лингвистических) признаках, понятие “меры близости” более специфично.
С учетом того, что каждый класс описывается совокупностью предложений, характеризующих структурные особенности объектов соответствующих классов, распознавание неизвестного объекта осуществляется идентификацией предложения, описывающего этот объект, с одним из предложений в составе описания какого-либо класса.
При этом идентификация может подразумевать наибольшее сходство предложения, описывающего распознаваемый объект, с предложениями из наборов описания каждого класса.

