 2015-01-07
2015-01-07 10593
10593Устойчивые закономерности открытого текста и их использование при дешифровании шифров простой замены и перестановки. Возможность дешифрования какого либо шифра в значительной мере зависит от того, в какой степени криптографические преобразования разрушают вероятностно-статистические закономерности, присутствующие в открытом тексте. К наиболее устойчивым закономерностям открытого сообщения относятся следующие:
1) В осмысленных текстах любого естественного языка различные буквы встречаются с разной частотой, при этом относительные частоты букв в различных текстах одного языка близки между собой. То же самое можно сказать и о частотах пар, троек букв открытого текста;
2) Любой естественный язык обладает так называемой избыточностью, что позволяет с большой вероятностью «угадывать» смысл сообщения, даже если часть букв в сообщении не известна.
В приводимой ниже таблицы указаны относительные частоты букв алфавита русского языка.
| а - 0,062 | л - 0,035 | ц - 0,004 | |||
| 6-0,014 | м- 0,026 | ч- 0,012 | |||
| в - 0,038 | н - 0,053 | ш - 0,006 | |||
| г -0,013 | о - 0,090 | щ - 0,003 | |||
| д - 0,025 | п - 0,023 | ы- 0,016 | |||
| е,ё - 0,072 | р - 0,040 | ъ,ь- 0,014 | |||
| ж - 0,077 | с - 0,045 | э - 0,003 | |||
| 3-0,016 | т - 0,Q53 | ю - 0,006 | |||
| и - 0,062 | у -0,021 | я -0,018 | |||
| и -0,010 | ф - 0,002 | - 0,175 | |||
| к - 0,28 | х - 0,009 |
Подобные таблицы приводятся в разных книгах. Они получены на основе подсчетов частот на больших объемах открытого текста. Учитывая, что для экспериментов берется различный исходный материал, значения вероятностей несколько отличаются между собой.
Если упорядочить буквы по убыванию вероятностей, то мы получим вариационный ряд
О,Е,А,И,Н,Т,С,Р,В,Л,К,М,Д,П,У,Я,3,Ы,Б,Ь,Г,Ч,Й,Х,Ж,Ю,Ш,Ц,Щ,Э,Ф.
Как запомнить первые 10 наиболее частых букв? Помните, как запоминают основные цвета в физике? Надо запомнить фразу ^ Каждый охотник желает знать, где живет фазан. Первые буквы слов фразы указывают на основные цвета. В криптографии надо запомнить слово СЕНОВАЛИТР - в нем все 10 наиболее частых букв.
Частотная диаграмма, конечно, зависит от языка. В нижеследующей таблице приводятся в процентах относительные частоты наиболее употребляемых букв некоторых языков.
| Английский язык | е- 12,75 | t-9,25 | г -8,50 | i - 7,75 | h - 7,75 | о - 7,50 |
| Французский язык | е- 17,75 | а - 8,25 | s-8,25 | i - 7,25 | n - 7,25 | r-7,25 |
| Немецкий язык | е- 18,50 | п - 1 1.,50 | i - 8,00 | г - 7,50 | s - 7,00 | a - 5,00 |
| Арабский язык | а -17,75 | |||||
| Греческий язык | а -14,25 | |||||
| Японский язык | р- 15,75 | |||||
| Латинский язык | а -11,00 | |||||
| Малайский язык | а -20,25 | |||||
| Санскрит | а -31,25 |
Частоты знаков алфавита зависят не только от языка, но и от характера текста. Так в тексте по криптографии будет повышена вероятность букв Ф, Ш (из-за часто встречающихся слов «шифр», «криптография»). В математическом тексте скорее всего будет завышена частота буквы Ф (из-за слов «функция», «функционал» и т. п.).
В стандартных текстовых файлах наиболее частым был символ «пробел», в ехе-файлах наиболее часто встречается символ 0, в текстах, написанных в текстовом процессоре ChiWriter, удобном для оформления математических текстов, на первое место вышел символ "\" - backslash.
Частотная диаграмма является устойчивой характеристикой текста. Из теории вероятностей следует, что при достаточно слабых ограничениях на вероятностные свойства случайного процесса справедлив закон больших чисел, т. е. относительные частоты у знаков сходятся по вероятности к значениям их вероятностей Pk:
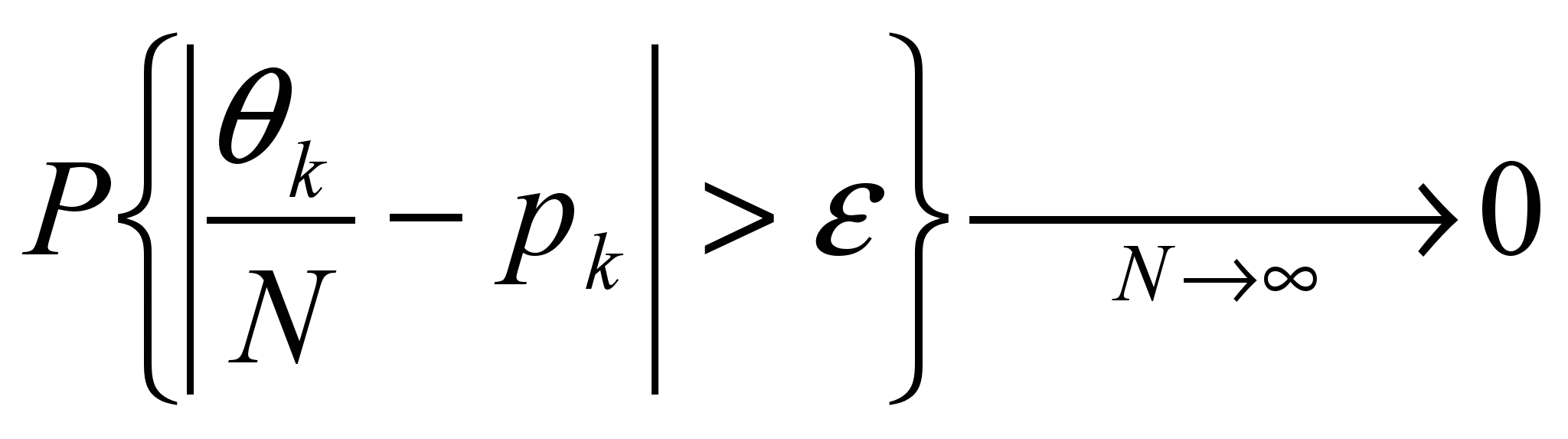 .
.
Это верно для последовательности независимых испытаний, для конечной регулярной однородной цепи Маркова. Эксперименты показывают, что это верно и для открытых текстов.
С позиций современной криптографии шифры перестановки и простой замены обладают существенным недостатком - они не полностью разрушают вероятностно-статистические свойства, имеющиеся в открытом сообщении.
При дешифровании текста, зашифрованного шифром простой замены, используют частотные характеристики открытого текста. Именно, если подсчитать частоты встречаемости знаков в шифрованном тексте, упорядочить их по убыванию и сравнить с вариационным рядом вероятностей открытого текста, то эти две последовательности будут близки. Скорее всего на первом месте окажется пробел, далее будут следовать буквы О, Е, А, И.
Конечно, если текст не очень длинный, то не обязательно полное совпадение. Может оказаться на втором месте О, а на третьем Е, но в любом случае в первых и вторых рядах одинаковые буквы будут располагаться недалеко друг от друга, и чем ближе к началу (чем больше вероятность знаков), тем меньше будет расстояние между знаками.
Аналогичная картина наблюдается и для пар соседних букв (биграмм) открытого текста (наиболее частая биграмма русского открытого текста - СТ). Однако для получения устойчивой картины длина последовательности должна быть существенно больше. На сравнительно небольших отрезках открытого текста эта картина как-то смазана. Более устойчивой характеристикой биграмм является отсутствие в осмысленном тексте некоторых биграмм, как говорят, наличие запретных биграмм, имеющих вероятность, равную практически 0.
Видели ли Вы когда-нибудь в открытом тексте биграммы ЪЬ, «гласная» Ь, «пробел» Ь? Знание и использование указанных особенностей открытого текста значительно облегчает дешифрование шифра перестановки и замены.
Дешифрование шифра простой замены! Рассмотрим пример дешифрования шифра простой замены (Учебное пособие «Принципы и методы защиты информации», Проскурин Г.В.). Пусть у нас имеется следующий шифртекст.
ДОЧАЛЬ ИЬЦИО ЛИОЙО ВНЫИЮШ ХЕМВЛНХЕИ ДОСОЛЬ ЧСО ИА ТЬЖАТСР ЬАС АКЕИОЙО ДОКЩОКЗЖАЙО КПЗ РТАЩ ТПЬЧНАР ТДО-ТОУН ХЕМВОРНИЕЗ ЕИМОВЛНЯЕЕ РЮУОВ БВЕД СОЙВНМЕЧАТБОГ ТЕТСАЛЮ ЫНРЕТЕС ОС ОТОУ АИИОТСАГ ЕИМОВЛНЯЕЕ АА ЯАИИ-ОТСЕ Е РОЫЛОЦИОТСАГ РПНКАПШЯАР ДО ЫНЖУСА ТРОАГ ЕИМОВЛНЯЕЕ ДВАЦКА РТАЙО ДОКЧАВБЙАЛ УОПШХОА ВНЫИООУ ВНЫЕА РЕКОР ЫНЖЕЖНАЛОГ ЕИМОВЛНЯАА КОБЬЛАИСНПШИНЗ САПАМОИИНЗ САПАРЕЫЕОИИНЗ БОЛДШЭСАВИНЗ БНЦКЮГ РЕК ЕИМОВЛНЯЕЕ УЛААС ТРОЕ ТДАЯЕМЕЧАТБЕА ОТОУАИИОТСЕ Е ФСБ ОТОЧАИИОТСЕ ТЕПШИО РПЕЗЭС ИН РЮУОВ ЛАСОКОР ХЕМВОРНИЕЗ ЕИМОВЛНЯЕЕ УОПШХОА ЫИНЧАИЕА ЕЛАЭС ОУЪАЛЮ Е СВАУЬАЛНЗ ТБОВОТСШ ДАВАКНЧЕ ХЕМВОРНИИОГ
Работу следует начать с подсчета частот символов в шифрованном тексте.
После того как проведен подсчет, упорядочим символы по убыванию частот.
Под ним стоит подписать вариационный ряд вероятностей знаков в открытом тексте.
^ О Е А И НТСРВЛКМДПУЯЗЫБЬГЧЙХЖЮШЦЩЭФ
При достаточно большой длине шифртекста, для того чтобы из шифрованного текста получить открытый, достаточно заменить bt на О, Ь2 на Е, Ь3 на А и т. д.
По крайней мере такая ситуация будет иметь место для наиболее вероятных букв. У нас материала недостаточно. Посмотрев на шифртекст после такой замены, Вы видите, что он не читается, - значит, материала действительно мало.
Что нам остается - угадывать замену. При этом мы должны все-таки учитывать статистические особенности открытого текста. В шифртексте через пробел скорее всего обозначается пробел, через букву О скорее всего обозначена О или А, через Е - О, Е, А, через А - Е, А или И и т.д.
Можно рекомендовать выписать шифртекст, а под ним в колонку наиболее вероятные замены для этих букв. В нашем примере замена подобрана таким образом, что буква алфавита заменена как раз на наиболее вероятное для нее обозначение. Поэтому сам шифртекст в данном примере выписывать нет необходимости. Он совпадает со средней строкой последовательности колонок наиболее вероятных замен.
Чем реже встречается буква - тем большей глубины надо брать колонку, чтобы была уверенность, что в колонке содержится знак открытого текста. В нашем случае колонки взяты одинаковой глубиной в 5 символов, но выписаны они только для наиболее частых букв.
Таблица не приводится из-за своей громоздкости, она приведена в Приложении 3.
При дешифровании без использования средств автоматизации дальше надо угадывать замену. Если присмотреться к тексту, то сделать это не очень трудно. В тексте есть слово А А из двух часто встречающихся букв. Что это может быть за слово? В русском языке нет слов ОО, ИИ, НН и т. д. Так перебирая возможные слова, мы обнаружим одно слово ЕЕ и прийдем к выводу, что буква Е была заменена на А. Очень часто в шифртексте слова кончаются биграммами ЕЕ. В русском языке типичными окончаниями являются сочетания ЕЕ, ИИ. Учитывая, что замену для буквы Е мы уже угадали, приходим к выводу, что в шифртексте буква И заменена на Е. Теперь всюду в шифртексте можно провести обратную замену. Теперь мы уже можем угадывать отдельные слова. Так, изрядно попотев, мы, как в игре «Поле чудес», в конце концов восстановим весь текст.
В колонках наиболее вероятных замен буквы, отвечающие правильным обратным заменам, должны быть обозначены как заглавные. Прочитавоткрытый текст, Вы убедитесь, что он представляет собой несколько предложений из книги Дориченко С.А. и Ященко В.В. «25 этюдов о шифрах»,М.,1994.
Для дешифрования в автоматизированном режиме прежде всего надо завести в память компьютера словарь русского языка.
Программа дешифрования должна, просматривая шифртекст, осуществлять пробные обратные замены, предполагая, что на данном фиксированнрм месте в открытом тексте находилось проверяемое слово. После каждой замены программа частично восстанавливает ключевую подстановку, частично расшифровывает текст и отсеивает вариант подстановки, если в каком-то месте восстановленного текста оказывается буквосочетание, которое не может быть в открытом тексте. После восстановления некоторого числа замен в тексте появляются участки, в которых определено значительное число букв. Оставшиеся буквы подбираются путем перебора словаря и подстановки в текст слов, которые не противоречат восстановленным ранее заменам.
Следует отметить, что практические навыки по дешифрованию шифра простой замены можно получить лишь после проведения самостоятельных опытов по дешифрованию.








