 2015-02-27
2015-02-27 2607
26071.1 Совокупность 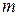 функций, определенных на одном и том же множестве элементарных событий, называется - мерной случайной величиной
функций, определенных на одном и том же множестве элементарных событий, называется - мерной случайной величиной 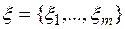 . Многомерная случайная величина полностью определяется ее функцией распределения вероятностей
. Многомерная случайная величина полностью определяется ее функцией распределения вероятностей
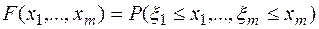
удовлетворяющей следующим условиям:
1. 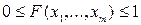 ;
;
2. 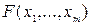 не убывает по каждому аргументу;
не убывает по каждому аргументу;
3. 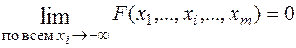 ;
;
4. 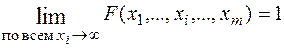 ;
;
5. 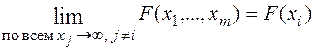 ,
,
где 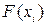 - функция распределения одномерной случайной величины
- функция распределения одномерной случайной величины 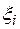 .
.
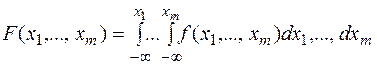
1.2. Рассмотрим непрерывную двумерную случайную величину 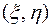 с плотностью
с плотностью 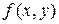 и функцией распределения
и функцией распределения 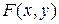 . Одномерные (маргинальные) распределения
. Одномерные (маргинальные) распределения 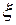 и
и 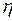 :
:
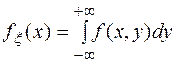 и
и 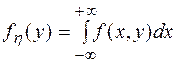
Условные плотности: при заданном значении  и при заданном значении
и при заданном значении  :
:
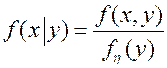 и
и 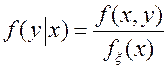
откуда 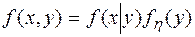 и
и 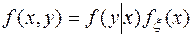 .
.
1.3. Компоненты m -мерной случайной величины 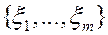 называются независимыми, если их совместная функция распределения равна произведению одномерных функций распределения
называются независимыми, если их совместная функция распределения равна произведению одномерных функций распределения
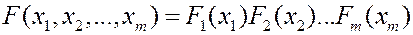 .
.
Компоненты 2-мерной непрерывной случайной величины 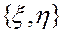 являются независимыми, если
являются независимыми, если
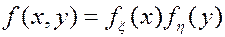 .
.
1.4. Характеристики распределения
- случайный вектор.
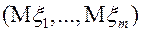 .- вектор математических ожиданий.
.- вектор математических ожиданий.
1.4.1. Если m =2, к этим характеристикам добавляются: ковариация: 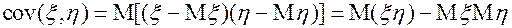 ,
,
разности 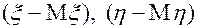 называют центрированными случайными величинами;
называют центрированными случайными величинами;
коэффициент корреляции - характеристика связи случайных величин и 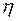 .
.
Определение. Коэффициентом корреляции двух случайных величин и называется
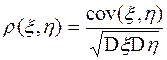
Свойства коэффициента корреляции:
1. Для любых случайных величин и 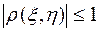 .
.
2. Если и - независимые случайные величины, то 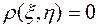 (обратное, вообще говоря, неверно).
(обратное, вообще говоря, неверно).
3. Если , то и называются некоррелированными.
4. 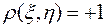 или
или 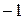 т.и т. т., когда
т.и т. т., когда 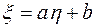 .
.
5. 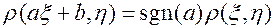
В случае m>2 дисперсии и ковариации удобно записывать в виде ковариационной матрицы
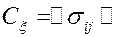 , где
, где 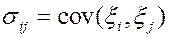 для i≠j;
для i≠j; 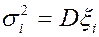 для i=j,, т.е.covariance и variance, что и подчеркивает сходство этих понятий.
для i=j,, т.е.covariance и variance, что и подчеркивает сходство этих понятий.
Для корреляционной матрицы
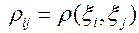 для i≠j;
для i≠j; 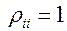 .
.
Ковариационная и корреляционная матрицы являются квадратными и симметричными матрицами.
1.4.2. Точечная оценка параметра ρ двумерного нормального распределения называется выборочным коэффициентом линейной корреляции или коэффициентом корреляции Пирсона. Для этого случая можно построить приближенный доверительный интервал для неизвестного коэффициента корреляции; применить приближенный критерий для проверки гипотезы о равенстве нулю коэффициента корреляции между компонентами двумерной случайной величины. Для этого используется функция, называемая распределением Фишера, которая довольно хорошо аппроксимируется нормальным распределением.
1.4.3. Коэффициент ранговой корреляции Спирмена
Пусть имеется двумерная выборка 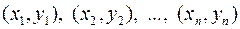 из неизвестного двумерного распределения. Причем наблюдаемые признаки могут быть как количественными, так и порядковыми. Найдем ранги,
из неизвестного двумерного распределения. Причем наблюдаемые признаки могут быть как количественными, так и порядковыми. Найдем ранги, 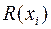 и
и 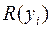 , в последовательностях
, в последовательностях 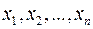 и
и 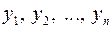 , упорядоченных по отдельности. Мерой зависимости двух случайных величин является коэффициент ранговой корреляции Спирмена, определяемый формулой
, упорядоченных по отдельности. Мерой зависимости двух случайных величин является коэффициент ранговой корреляции Спирмена, определяемый формулой
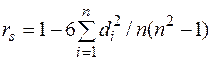
где 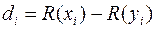 . Коэффициент используется для проверки гипотезы о независимости признаков
. Коэффициент используется для проверки гипотезы о независимости признаков  (как статистика критерия).
(как статистика критерия).
1.5. Пусть 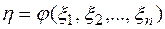 , где
, где 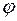 - некоторая функция от п случайных величин
- некоторая функция от п случайных величин 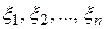 . Тогда функция распределения случайной величины задается (в случае, когда - непрерывные случайные величины) формулой
. Тогда функция распределения случайной величины задается (в случае, когда - непрерывные случайные величины) формулой
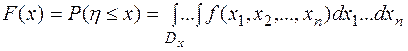
где 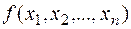 - функция плотности n – мерной случайной величины
- функция плотности n – мерной случайной величины 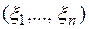 , а
, а 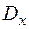 - область
- область 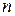 – мерного пространства такая, что
– мерного пространства такая, что 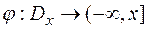 .
.
Математическое ожидание равно
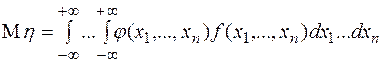
1.5.1. Если 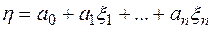 , то,воспользовавшись свойствами математического ожидания и дисперсии, получим:
, то,воспользовавшись свойствами математического ожидания и дисперсии, получим:
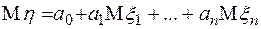
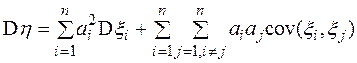
1.5.2. Пусть теперь 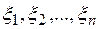 независимы и одинаково распределены. Обозначим
независимы и одинаково распределены. Обозначим 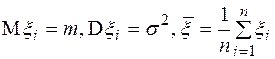 , тогда
, тогда 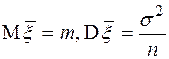 .
.
1.5.3. Если каждая случайная величина 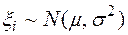 , то, можно доказать, случайная величина нормально распределена и, следовательно,
, то, можно доказать, случайная величина нормально распределена и, следовательно, 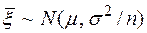 .
.
1.5.4. Отметим:
1. 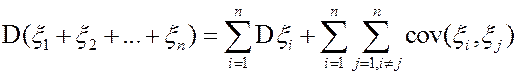 ;
;
2. При линейной замене 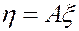 ковариационная матрица преобразуется так же, как матрица квадратичной формы:
ковариационная матрица преобразуется так же, как матрица квадратичной формы:
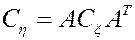 .
.
Эти свойства открывают путь к ряду интересных приложений. Например, как известно, квадратичную форму можно привести (ортогональным преобразованием) к главным осям (т.е. матрица квадратичной формы сделается диагональной). Применив такое же преобразование к случайному вектору, получим, что он переходит в вектор с некоррелированными компонентами. В ТВ они называются главными компонентами. На этом основан метод главных компонент.
2. Классификация методов анализа многомерных данных
Данные представляются в виде прямоугольной таблицы (матрицы), строки которой соответствуют различным ситуациям (наблюдениям), а столбцы - переменным, наблюдаемым в этих ситуациях. Результаты же представляются в виде функций, выражающих одни переменные (называемые зависимыми переменными, или откликами) через другие переменные (называемые независимыми переменными, или факторами).
Предлагаемая ниже классификация методов анализа данных проведена по двум основаниям: отсутствию или наличию независимых переменных, а также по типу зависимых и независимых переменных, которые могут быть качественными или количественными. Независимые переменные также называют факторами, а зависимые – откликами.
В случае априорного разделения переменных на зависимые и независимые (см. левую часть рис. 1) задача анализа состоит в получении описания зависимости Y от X. Выбор метода решения зависит прежде всего от того, являются ли качественными или количественными зависимые переменные Y. Окончательное решение о выборе метода анализа данных принимается в зависимости от типа независимых переменных X.
Наиболее часто для установления связи между независимыми и зависимыми переменными применяют регрессионный анализ и дисперсионный анализ. В обоих случаях откликами служат количественные переменные. Однако факторы в регрессионном анализе количественные, а в дисперсионном - качественные.
В регрессионном анализе наиболее явно виден функциональный характер модели анализа данных. Задача регрессионного анализа прямо формулируется как задача поиска функциональной зависимости Y от X, причем задача поиска формы связи не менее важна, чем вопросы статистической значимости полученных результатов. Наиболее широко применяется модель множественного линейного регрессионного анализа, позволяющая получать аналитически все стандартные статистические оценки. В более сложных ситуациях (например, при использовании пошаговых процедур) для получения статистических выводов приходится применять методы, основанные на стохастическом моделировании, такие как случайная пермутация или бут-стрэп.
Задачей дисперсионного анализа является установление связи между независимыми качественными переменными и зависимыми количественными. Однако поскольку функциональная структура связи очень проста - отклики представляются как линейные комбинации бинарных переменных - уровней факторов, то основное внимание в дисперсионном анализе уделяется вопросам статистической значимости влияния отдельных факторов.
Если отклики Y качественные, то для анализа используется группа методов, известная под общим названием распознавания образов. Наиболее используемым методом распознавания в случае количественных факторов является дискриминантный анализ. Целью дискриминантного анализа является получение правила, позволяющего на основе наблюденных значений количественных независимых переменных X предсказывать значение качественной переменной Y, указывающей на принадлежность наблюдения к одному из заданных классов.
Примерами методов распознавания в случае качественных факторов, могут служить сегментационный анализ и метод обобщенного портрета. Сегментационный анализ состоит в последовательном разбиении совокупности наблюдений с целью получения, в конечном итоге, групп, максимально однородных по классовому составу.
Случай отсутствия зависимых переменных (правая часть рис. 1) предполагает, что все анализируемые переменные в некотором смысле равноправны, и мы принимаем их за отклики (для простоты будем считать их количественными), значения которых определяются какими-то нам неизвестными факторами. Примерами могут служить морфологические или генетические характеристики растений, животных или людей, принадлежащих определенному таксону или обитающих на определенной территории. Задача анализа состоит в поиске этих неизвестных факторов. Выбор метода решения зависит от того, считаем ли мы искомые факторы качественными или количественными (методы анализа структуры данных)
Для поиска качественных факторов используется группа методов, известная под названием кластерный анализ, среди которых наиболее часто используется так называемый агломеративно-иерархический метод, основанный на последовательном объединении многомерных наблюдений сначала в мелкие, а затем во все более и более крупные группы. Результатом кластерного анализа является разбиение всей совокупности наблюдений на классы. Полученной классификации соответствует качественная переменная (или несколько переменных, если используются несколько классификаций разной степени дробности или пересекающиеся классификации), категориями которой служат номера классов. Именно эта переменная (или переменные) и будет искомым качественным фактором. Найдя такой фактор (классифицирующую переменную), мы получаем возможность объяснять сходство или различие в значениях откликов для разных наблюдений принадлежностью их к одному или к разным классам.
Если же неизвестные факторы ищутся в форме количественных переменных, то используются методы факторного анализа. В этом случае задача состоит в представлении имеющихся откликов, Y, в виде линейных комбинаций неизвестных количественных факторов, X. С практической точки зрения применение этого метода оправдано, если удается с достаточной степенью приближения выразить большое количество откликов через малое число факторов.
Одним из наиболее часто используемых методов этого класса является метод главных компонент, основанный на ортогональном проектировании исходного многомерного пространства в пространство меньшей размерности, в котором точки-наблюдения имеют наибольший разброс. Этот метод позволяет записать исходные данные в более компактном виде с сохранением максимума содержащейся в них информации и даже представить их графически на плоскости для случая двух факторов.
Следует еще раз подчеркнуть, что методы анализа многомерных данных делятся на методы анализа связи (в случае выделения зависимых и независимых переменных) и методы анализа факторов (или анализа структуры данных), когда такого деления нет.
Необходимо отметить, что уровни качественных факторов можно рассматривать как бинарные переменные, которые, в свою очередь, можно считать количественными переменными со значениями 0 и 1. С другой стороны, непрерывную шкалу значений количественной переменной можно категоризовать и рассматривать эту переменную как качественную. Во всяком случае, такого рода преобразования приходится делать вынужденно, когда по типу различаются не только факторы и отклики, но и разные переменные среди факторов или среди откликов.
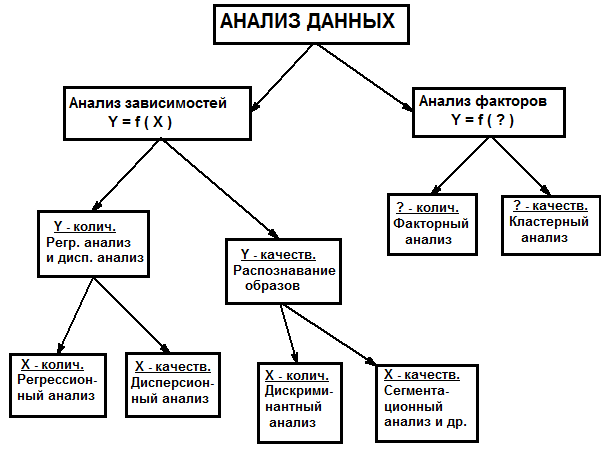
Рис 1. Классификация методов анализа данных

