 2015-02-27
2015-02-27 1619
1619Последовательность входящих информационных символов 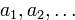 разбивается на отрезки (блоки), каждый содержащий
разбивается на отрезки (блоки), каждый содержащий 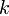 символов:
символов:
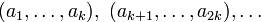
В кодере производится преобразование каждого отдельного блока в новый блок:
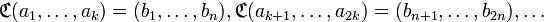
Правило преобразования (функциональная зависимость, обозначенная здесь буквой 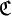 ) каждого входящего блока не зависит от содержания других входящих блоков; получающиеся в ходе преобразваний блоки
) каждого входящего блока не зависит от содержания других входящих блоков; получающиеся в ходе преобразваний блоки 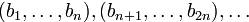 называются кодовыми словами. Число
называются кодовыми словами. Число 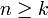 называется длиной кода (длиной блока).
называется длиной кода (длиной блока).
Пример. Пусть алфавит языка состоит из пяти букв: а, в, л, о, с. Их кодирование в цифровую последовательность возможно по правилу:
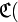 а) =0,
а) =0, 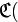 в)=1; л)=2;
в)=1; л)=2; 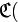 о)=3, с)=4.
о)=3, с)=4.
В этом случае длина кода 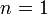 . Получатель, которому по телефону диктуют цифровые последовательности
. Получатель, которому по телефону диктуют цифровые последовательности
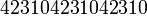 или
или 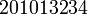
однозначно декодирует их — если знает правило кодирования. Понятно, что для кодирования всего русского алфавита потребуются уже двузначные десятичные числа, т.е. 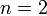 (и отметим, на всякий случай, что кодирование по правилу
(и отметим, на всякий случай, что кодирование по правилу
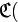 а)=0,
а)=0, 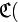 б)=1
б)=1 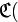 я)=32 уже не будет правильным…). Пока остановимся на примере пятибуквенного алфавита чтобы показать две проблемы. Предположим, что телефонная линия подвержена помехам и какие-то сообщения могут теряться:
я)=32 уже не будет правильным…). Пока остановимся на примере пятибуквенного алфавита чтобы показать две проблемы. Предположим, что телефонная линия подвержена помехам и какие-то сообщения могут теряться:
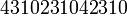 или же искажаться
или же искажаться 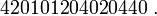
Можно ли восстановить утраченную информацию? — Понятно, что ответ на этот вопрос зависит, в первую очередь, от передающих характеристик самого канала связи.
Переходим к кодированию букв в двоичной системе: а)=00, в)=01, о)=10,
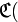 с)=11, забывая пока о пятой букве. Таким образом длина кода
с)=11, забывая пока о пятой букве. Таким образом длина кода 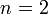 . Предположим, что на каждое передаваемое кодовое слово канал связи дает не более одной ошибки: в каждом блоке длины 2 может менять 0 на 1 или 1 на 0 — но не сразу оба бита (и не «затирает» бит полностью). Что может произойти при передаче закодированного сообщения
. Предположим, что на каждое передаваемое кодовое слово канал связи дает не более одной ошибки: в каждом блоке длины 2 может менять 0 на 1 или 1 на 0 — но не сразу оба бита (и не «затирает» бит полностью). Что может произойти при передаче закодированного сообщения 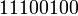
по такому каналу? Получатель может увидеть следующие варианты:
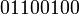 или
или 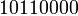 или
или 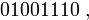
но не получит следующие: 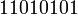 или
или 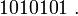
Итак, выбор самого экономичного способа кодирования — когда четырем символам алфавита соответствуют четыре двоичных блока — не решает задачу надежной коммуникации. Увеличим длину кода, пусть
а)=11000, в)=00110, о)=10011, с)=01101.
Что может произойти с этими кодовыми словами при внесении в них ровно одной ошибки? Составим таблицу всех возможных ситуаций:
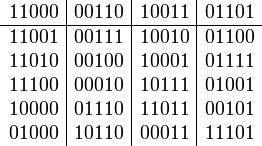
Обратим внимание на то, что столбцы не содержат одинаковых блоков. Таким образом, если условие зашумляемости блока не более чем одной ошибкой выполняется, декодер сможет однозначно восстановить передаваемую букву — достаточно будет найти в таблице столбец, содержащий полученный блок.
Этот пример служит примером кода, исправляющего ошибки — в данном случае одну ошибку. Что произойдет если зашумленность канала оказывается более высокой, чем предполагалось? Возможны ситуации, когда полученный в результате передачи блок будет содержаться в таблице. Например, если на вход подается блок 11000, а канал портит два бита, то получатель может увидеть блок10100, который хоть и содержится в таблице, но декодируется совсем не в ту букву, которая передавалась. А может случиться и так, что на выходе из канала получится блок11110, который совсем не содержится в таблице. Эта ситуация иногда более выгодна, чем предыдущая: декодер можно заставить извещать пользователя об обнаружении ошибки в случае когда полученный блок не содержится в таблице. Можно заложить в декодере одновременно обе возможности — сигнализации об ошибке и ее исправления. На примере полученного блока 11110 посмотрим, что можно предпринять. Обратим внимание, что этот блок отличается от отправленного11000= а) в двух битах, от блока00110= в) — также в двух битах, а от каждого из блоков 10011= о) или 01101= с) — в трех битах. Поэтому, ввиду гипотезы о не более чем двух зашумленных битах, можно при декодировании отбросить два последних варианта, как невозможные.








