 2015-02-27
2015-02-27 394
394Требуется построить классифицирующую функцию 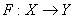 , где X - пространство векторов признаков, Y - пространство меток классов. Пусть в нашем распоряжении имеется обучающая выборка (x1, y1),..., (xN, yN). Где
, где X - пространство векторов признаков, Y - пространство меток классов. Пусть в нашем распоряжении имеется обучающая выборка (x1, y1),..., (xN, yN). Где 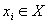 вектор признаков, а
вектор признаков, а 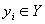 метка класса, к которому принадлежит . Далее в статье мы будем рассматривать задачу с двумя классами, то есть Y = {- 1; + 1 }. Также у нас есть семейство простых классифицирующий функций
метка класса, к которому принадлежит . Далее в статье мы будем рассматривать задачу с двумя классами, то есть Y = {- 1; + 1 }. Также у нас есть семейство простых классифицирующий функций 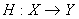 . Мы будем строить финальный классификатор в следующей форме:
. Мы будем строить финальный классификатор в следующей форме:
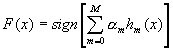 ,
,
где 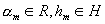 . Построим итеративный процесс, где на каждом шаге будем добавлять новое слагаемое
. Построим итеративный процесс, где на каждом шаге будем добавлять новое слагаемое
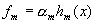 ,
,
вычисляя его с учётом работы уже построенной части классификатора.

На каждом шаге будем для каждого примера (xi, yi) из обучающей выборки вычислять его "вес": положим D0 (i) = 1 / N, тогда
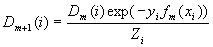 ,
,
где Zi - нормализующий коэффициент, такой что
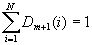
Вес каждого элемента обучающей выборки на текущем шаге задает <важность> этого примера для очередного шага обучения алгоритма. Чем больше вес, тем больше алгоритм будет <стараться> на данном шаге классифицировать этот пример правильно. Как видно из формулы, чем уверенней пример распознаётся предыдущими шагами, тем его вес меньше - таким образом, самые большие веса получают примеры, которые предыдущими шагами были классифицированы неверно. Проще говоря, мы варьируем веса таким образом, чтобы классификатор, включенный в комитет на текущем шаге, <концентрировался> на примерах, с которыми предыдущие шагами <не справились>. Таким образом на каждом шаге мы работаем с какой-то частью данных, плохо классифицируемой предыдущими шагами, а в итоге комбинируем все промежуточные результаты.
Очередной простой классификатор мы будем выбирать исходя из взвешенной с распределением Dm ошибки. Мы выбираем (тренируем) 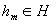 минимизирующий взвешенную ошибку классификации
минимизирующий взвешенную ошибку классификации
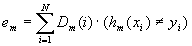
Заметим, что если рассмотреть Dm как распределение вероятности над X, что правомерно т.к.
, то
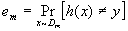
Далее вычисляется вклад текущего слагаемого классифицирующей функции
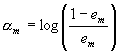
Мы продолжаем процесс до некоторого шага M, номер которого определяется вручную.








