 2015-02-18
2015-02-18 2324
2324Как мы уже отмечали, характер распределения результатов после воздействия изучаемого фактора в опытной группе дает существенную информацию о том, как испытуемые выполняли задание. Сказанное относится и к обоим распределениям в контрольной группе:
Контрольная группа Мода (Мо) Медиана (Me) Средняя М\)
Ф°":....................................
После воздействия:....................................
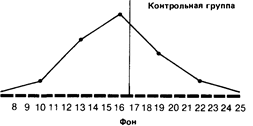
8 9 10 11 12 1314 1516 171819 2021 22232425 После воздействия
Сразу бросается в глаза, что если средняя в обоих случаях почти одинакова, то во втором распределении результаты больше разбросаны, чем в первом. В таких случаях говорят, что у второго распределения больше диапазон, или размах вариаций, т. е. разница между максимальным и минимальным значениями.
Так, если взять контрольную группу, то диапазон распределения для фона составит 22 — 10 = 12, а после воздействия 25 — 8 = 17. Это позволяет предположить, что повторное выполнение задачи на глазодвига-тельную координацию оказало на испытуемых из контрольной группы определенное влияние: у одних показатели улучшились, у других ухудшились1. Однако для количественной оценки разброса результатов
' Здесь мог проявиться зффект п.шцебо, связанный с тем. что запах дыма травы вызвал у испытуемых уверенность в том, что они находятся под воздействием наркотика. Для проверки этого предположения следовало бы повторить эксперимент со второй контрольной группой, в которой испытуемым будуг 1;|вать только обычную сигарету.
относительно средней в том или ином распределении существуют более точные методы, чем измерение диапазона.
Чаще всего для оценки разброса определяют отклонение каждого из полученных значений от средней (М-М), обозначаемое буквой d, а затем вычисляют среднюю арифметическую всех этих отклонений. Чем она больше, тем больше разброс данных и тем более разнородна выборка. Напротив, если эта средняя невелика, то данные больше сконцентрированы относительно их среднего значения и выборка более однородна.
Итак, первый показатель, используемый для оценки разброса,-это среднее отклонение. Его вычисляют следующим образом (пример, который мы здесь приведем, не имеет ничего общего с нашим гипотетическим экспериментом). Собрав все данные и расположив их в ряд
356911 14, находят среднюю арифметическую для выборки:
3+5+6+9+11+14 48
__————^———————=^=8.
Затем вычисляют отклонения каждого значения от средней и суммируют их:
-5 -3 -2 +1 +3 +6 (3 - 8) + (5 - 8) + (6 - 8) + (9 - 8) + (11 - 8) + (14 - 8).
Однако при таком сложении отрицательные и положительные отклонения будут уничтожать друг друга, иногда даже полностью, так что результат (как в данном примере) может оказаться равным нулю. Из этого ясно, что нужно находить сумму абсолютных значений индивидуальных отклонений и уже эту сумму делить на их общее число. При этом получится следующий результат:
| среднее отклонение равно 53213 |3-8|+|5-8[+|6-8|+|9-8|+|11 -8|+ | 14^8! 20 ззз |
| б 33'3- |
Общая формула:
2^| п
Среднее отклонение =
где Т. (сигма) означает сумму; | d\ - абсолютное значение каждого индивидуального отклонения от средней; и-число данных.
Однако абсолютными значениями довольно трудно оперировать в алгебраических формулах, используемых в более сложном статистическом анализе. Поэтому статистики решили пойти по «обходному пути», позволяющему отказаться от значений с отрицательным знаком, а именно возводить все значения в квадрат, а затем делить сумму квадратов на
Приложение Б
число данных. В нашем примере это выглядит следующим образом:
(_5)2 + (-З)2 + (-2)2 + (+1)2 + (+3)2 + (+6)2 _
6 _25+9+4+1+9+36_84_
6 - 6 ~ '
В результате такого расчета получают так называемую вариансу1 Формула для вычисления вариансы, таким образом, следующая:
Варианса -=•
Наконец, чтобы получить показатель, сопоставимый по величине со средним отклонением, статистики решили извлекать из вариансы квадратный корень. При этом получается так называемое стандартное отклонение:
В нашем примере стандартное отклонение равно ^14 = 3,74.
Следует еще добавить, что для того, чтобы более точно оценить стандартное отклонение для малых выборок (с числом элементов менее 30), в знаменателе выражения под корнем надо использовать не п, an—I:
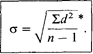
Вернемся теперь к нашему эксперименту и посмотрим, насколько полезен оказывается этот показатель для описания выборок.
На первом этапе, разумеется, необходимо вычислить стандартное
* Варианса представляет собой один из показателей разброса, используемых в гекоторых статистических методиках (например, при вычислении критерия F, <.м. следующий раздел). Следует отметить, что в отечественной литературе вариансу часто называют дисперсией. -Прим. перед.
* Стандартное отклонение для популяции обозначается маленькой греческой буквой сигм! (ст), а для выборки - буквой s. Это касается и вариансы, т.е кзадрага стандартного отклонения, для популяции она обозначается ет2, а для выборки s2.
Статистика и обработка данных
отклонение для всех четырех распределений. Сделаем это сначала для фона опытной группы:
Расчет стандартного отклонения ^ для фона контрольной группы
Испытуемые Число пора- Средняя Отклоне- Квадрат от-женных мише- ние от клонения от ней в серии средней (d) средней (d2)
19 10
15,8 15,8 15,8
-3,2 +5.8 +3,8
10.24 33,64 14,44
15 22 15,8 -6,2 38,44
Сумма (^)d2 = 131,94
131,94
Варианса (s2} = • = 9,42.
Н-1 14 Стандартное отклонение (?) = ^'варианса = л/9,42 == 3,07.
' Формула для расчетов и сами расчеты приведены здесь лишь в качестве иллюстрации В наше время гораздо проще приобрести гакой карманный микрокалькулятор, в котором подобные расчеты уже заранее запрограммированы, и для расчета стандартного отклонения достаточно лишь ввести данные, а затем нажать клавишу s.
О чем же свидетельствует стандартное отклонение, равное 3,07? Оказывается, оно позволяет сказать, что большая часть результатов (выраженных здесь числом пораженных мишеней) располагается в пределах 3,07 от средней, т.е. между 12,73 (15,8 - 3,07) и 18,87 (15,8 + 3,07).
Для того чтобы лучше понять, что подразумевается под «большей частью результатов», нужно сначала рассмотреть те свойсгва стандартного отклонения, которые проявляются при изучении популяции с нормальным распределением.
Статистики показали, что при нормальном распределении «большая часть» результатов, располагающаяся в пределах одного стандартного отклонения по обе стороны от средней, в процентном отношении всегда одна и та же и не зависит от величины стандартного отклонения: она соответствует 68% популяции (т.е. 34% ее элементов располагается слева и 34%-справа от средней):
Приложение Б 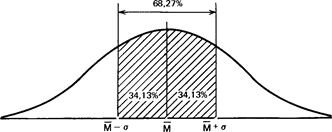
Точно так же рассчитали, что 94,45% элементов популяции при нормальном распределении не выходит за пределы двух стандартных отклонений от средней:
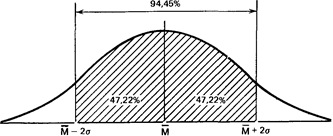
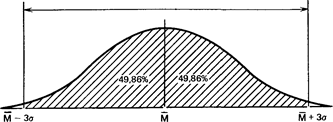
и что в пределах трех стандартных отклонений умещается почти вся популяция - 99,73 %.
99.73%
Учитывая, что распределение частот фона контрольной группы довольно близко к нормальному, можно полагать, что 68% членов всей популяции, из которой взята выборка, тоже будет получать сходные результаты, т.е. попадать примерно в 13-19 мишеней из 25. Распределение результатов остальных членов популяции должно выглядеть следующим образом:
Статистика и обработка данных
99,7%
95,4%
68,3%
34,1 % 34,1 % 2,2%
0,13%
13,6%
13,6%
0,13%
6,59 9,66 12,73 15,8 18,87 21,94 25,01
-Id +1(7
-2а +2о
-За +3а








