 2015-03-20
2015-03-20 881
881Цели анализа:
- оптимизировать размещение товаров на полках,
- формировать персональные рекомендации,
- планировать рекламные кампании (промо-акции),
- более эффективно управлять ценами и ассортиментом.
Значения для параметров минимальная поддержка и минимальная достоверность выбираются таким образом, чтобы ограничить количество найденных правил. Если поддержка имеет большое значение, то алгоритмы будут находить правила, хорошо известные аналитикам или настолько очевидные, что нет никакого смысла проводить такой анализ. С другой стороны, низкое значение поддержки ведет к генерации огромного количества правил, что, конечно, требует существенных вычислительных ресурсов. Тем не менее, большинство интересных правил находится именно при низком значении порога поддержки. Хотя слишком низкое значение поддержки ведет к генерации статистически необоснованных правил.
Поиск ассоциативных правил совсем не тривиальная задача, как может показаться на первый взгляд. Одна из проблем - алгоритмическая сложность при нахождении часто встречающих наборов элементов, т.к. с ростом числа элементов в I (| I |) экспоненциально растет число потенциальных наборов элементов.
|
|
|
Обобщенные ассоциативные правила (Generalized Association Rules)
При поиске ассоциативных правил мы предполагали, что все анализируемые элементы однородны. Возвращаясь к анализу рыночной корзины, это товары, имеющие совершенно одинаковые атрибуты, за исключением названия. Однако не составит большого труда дополнить транзакцию информацией о том, в какую товарную группу входит товар и построить иерархию товаров. Приведем пример такой группировки в виде иерархической модели.
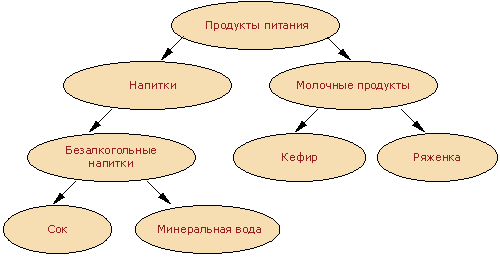
Пусть нам дана база транзакций D и известно в какие группы (таксоны) входят элементы. Тогда можно извлекать из данных правила, связывающие группы с группами, отдельные элементы с группами и т.д.
Например, если Покупатель купил товар из группы "Безалкогольные напитки", то он купит и товар из группы "Молочные продукты" или "Сок" "Молочные продукты". Эти правила носят название обобщенных ассоциативных правил.
Пропуск ->
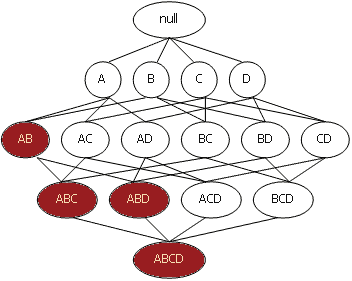
Определение 2. Обобщенным ассоциативным правилом называется импликация X 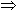 Y, где X Y, где X 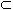 I, Y I и X I, Y I и X 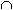 Y= Y= 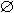 и где ни один из элементов, входящих в набор Y, не является предком ни одного элемента, входящего в X. Поддержка и достоверность подсчитываются так же, как и в случае ассоциативных правил. и где ни один из элементов, входящих в набор Y, не является предком ни одного элемента, входящего в X. Поддержка и достоверность подсчитываются так же, как и в случае ассоциативных правил. |
Введение дополнительной информации о группировке элементов в виде иерархии даст следующие преимущества:
1. Это помогает установить ассоциативные правила не только между отдельными элементами, но и между различными уровнями иерархии (группами).
|
|
|
2. Отдельные элементы могут иметь недостаточную поддержку, но в целом группа может удовлетворять порогу minsupport.
Для нахождения таких правил можно использовать любой из вышеназванных алгоритмов. Для этого каждую транзакцию нужно дополнить всеми предками каждого элемента, входящего в транзакцию. Однако, применение "в лоб" этих алгоритмов неизбежно приведет к следующим проблемам:
1. Элементы на верхних уровнях иерархии стремятся к значительно б о льшим значениям поддержки по сравнению с элементами на нижних уровнях.
2. С добавлением в транзакции групп увеличилось количество атрибутов и соответственно размерность входного пространства. Это усложняет задачу, а также ведет к генерации большего количества правил.
3. Появление избыточных правил, противоречащих определению обобщенного ассоциативного правила, например, "Сок" "Прохладительные напитки". Очевидно, что практическая ценность такого "открытия" нулевая при 100% достоверности. Следовательно, нужны специальные операторы, удаляющие подобные избыточные правила.
Для нахождения обобщенных ассоциативных правил желательно использование специализированного алгоритма, который устраняет вышеописанные проблемы и к тому же работает в 2-5 раз быстрее, чем стандартный APriori.
Группировать элементы можно не только по вхождению в определенную товарную группу, но и по другим характеристикам, например по цене (дешево, дорого), брэнду и т.д.
5 Слайд Дэн
Численные ассоциативные правила (Quantitative Association Rules)
При поиске ассоциативных правил задача была существенно упрощена. По сути все сводилось к тому, присутствует в транзакции элемент или нет. Т.е. если рассматривать случай рыночной корзины, то мы рассматривали два состояния: куплен товар или нет, проигнорировав, например, информацию о том, сколько было куплено, кто купил, характеристики покупателя и т.д. И можно сказать, что рассматривали "булевские" ассоциативные правила. Если взять любую базу данных, каждая транзакция состоит из различных типов данных: числовых, категориальных и т.д. Для обработки таких записей и извлечения численных ассоциативных правил был предложен алгоритм поиска.
Пример численного ассоциативного правила: [Возраст: 30-35] и [Семейное положение: женат] [Месячный доход: 1000-1500 тугриков].
Помимо описанных выше ассоциативных правил существуют косвенные ассоциативные правила, ассоциативные правила c отрицанием, временные ассоциативные правила для событий связанных во времени и другие.
Как было сказано, задача поиска ассоциативных правил впервые была представлена для анализа рыночной корзины. Ассоциативные правила эффективно используются в сегментации покупателей по поведению при покупках, анализе предпочтений клиентов, планировании расположения товаров в супермаркетах, кросс-маркетинге, адресной рассылке. Однако, сфера применения этих алгоритмов не ограничивается лишь одной торговлей. Их также успешно применяют и в других областях: медицине, для анализа посещений веб-страниц (Web Mining), для анализа текста (Text Mining), для анализа данных по переписи населения[7], в анализе и прогнозировании сбоев телекоммуникационного оборудования и т.д.
6 Слайд я
Apriori - масштабируемый алгоритм поиска ассоциативных правил
Предположим необходимо облегчить покупателям поиск товаров в супермаркете и разместить «ассоциированные» товары ближе друг к другу.
Например, покупатель берет томаты и идёт к кассе, стоит ли размещать на его пути соль? Часто ли покупатель берет помидоры и соль за раз (за одну транзакцию)? Ассоциированы ли эти товары?
Необходимо проанализировать рыночную корзину (market basket analysis), не делая никаких предположений (о соленых помидорах)
|
|
|
Для того, чтобы было возможно применить алгоритм, необходимо провести предобработку данных: во-первых, привести все данные к бинарному виду; во-вторых, изменить структуру данных.
Обычный вид базы данных транзакций:
| Номер транзакции | Наименование элемента | Количество |
| А | ||
| D | ||
| E | ||
| А | ||
| F | ||
| B | ||
| A | ||
| C | ||
| … | … | … |
Нормализованный вид:
| TID | A | B | C | D | E | F | G | H | I | K | ... |
| … | |||||||||||
| … | |||||||||||
| … |
Количество столбцов в таблице равно количеству элементов, присутствующих в множестве транзакций D. Каждая запись соответствует транзакции, где в соответствующем столбце стоит 1, если элемент присутствует в транзакции, и 0 в противном случае.Заметим, что исходный вид таблицы может быть отличным от приведенного в таблице 1. Главное, чтобы данные были преобразованы к нормализованному виду, иначе алгоритм не применим.
Более того, как видно из таблицы, все элементы упорядочены в алфавитном порядке (если это числа, они должны быть упорядочены в числовом порядке). Как вы, наверное, уже догадались, это сделано неслучайно. Но, не будем забегать вперед, всему свое время.
Итак, данные преобразованы, теперь можно приступить к описанию самого алгоритма. Как было сказано в предыдущей статье, такие алгоритмы работают в два этапа, не является исключением и рассматриваемый нами алгоритм Apriori. На первом шаге необходимо найти часто встречающиеся наборы элементов, а затем, на втором, извлечь из них правила. Количество элементов в наборе будем называть размером набора, а набор, состоящий из k элементов, – k-элементным набором.
Свойство анти-монотонности
Выявление часто встречающихся наборов элементов – операция, требующая много вычислительных ресурсов и, соответственно, времени. Примитивный подход к решению данной задачи – простой перебор всех возможных наборов элементов. Это потребует O(2|I|) операций, где |I| – количество элементов. Apriori использует одно из свойств поддержки, гласящее: поддержка любого набора элементов не может превышать минимальной поддержки любого из его подмножеств. Например, поддержка 3-элементного набора {Хлеб, Масло, Молоко} будет всегда меньше или равна поддержке 2-элементных наборов {Хлеб, Масло}, {Хлеб, Молоко}, {Масло, Молоко}. Дело в том, что любая транзакция, содержащая {Хлеб, Масло, Молоко}, также должна содержать {Хлеб, Масло}, {Хлеб, Молоко}, {Масло, Молоко}, причем обратное не верно.
|
|
|
Это свойство носит название анти-монотонности и служит для снижения размерности пространства поиска. Не имей мы в наличии такого свойства, нахождение многоэлементных наборов было бы практически невыполнимой задачей в связи с экспоненциальным ростом вычислений.
Свойству анти-монотонности можно дать и другую формулировку: с ростом размера набора элементов поддержка уменьшается, либо остается такой же. Из всего вышесказанного следует, что любой k-элементный набор будет часто встречающимся тогда и только тогда, когда все его (k-1)-элементные подмножества будут часто встречающимися.
Все возможные наборы элементов из I можно представить в виде решетки, начинающейся с пустого множества, затем на 1 уровне 1-элементные наборы, на 2-м – 2-элементные и т.д. На k уровне представлены k-элементные наборы, связанные со всеми своими (k-1)-элементными подмножествами.
Рассмотрим рисунок 1, иллюстрирующий набор элементов I – {A, B, C, D}. Предположим, что набор из элементов {A, B} имеет поддержку ниже заданного порога и, соответственно, не является часто встречающимся. Тогда, согласно свойству анти-монотонности, все его супермножества также не являются часто встречающимися и отбрасываются. Вся эта ветвь, начиная с {A, B}, выделена фоном. Использование этой эвристики позволяет существенно сократить пространство поиска.
Алгоритм Apriori
На первом шаге алгоритма подсчитываются 1-элементные часто встречающиеся наборы. Для этого необходимо пройтись по всему набору данных и подсчитать для них поддержку, т.е. сколько раз встречается в базе.
Следующие шаги будут состоять из двух частей: генерации потенциально часто встречающихся наборов элементов (их называют кандидатами) и подсчета поддержки для кандидатов.
Описанный выше алгоритм можно записать в виде следующего псевдо-кода:
1. F1 = {часто встречающиеся 1-элементные наборы}
2. для (k=2; Fk-1 <> ; k++) {
3. Ck = Apriorigen(Fk-1) // генерация кандидатов
4. для всех транзакций t 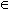 T {
T {
5. Ct = subset(Ck, t) // удаление избыточных правил
6. для всех кандидатов c Ct
7. c.count ++
8. }
9. Fk = { c Ck | c.count >= minsupport} // отбор кандидатов
10. }
11. Результат 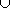 Fk
Fk
Опишем функцию генерации кандидатов. На это раз нет никакой необходимости вновь обращаться к базе данных. Для того, чтобы получить k-элементные наборы, воспользуемся (k-1)-элементными наборами, которые были определены на предыдущем шаге и являются часто встречающимися.
Вспомним, что наш исходный набор хранится в упорядоченном виде. Генерация кандидатов также будет состоять из двух шагов.
1. Объединение. Каждый кандидат Ck будет формироваться путем расширения часто встречающегося набора размера (k-1) добавлением элемента из другого (k-1)- элементного набора.
Приведем алгоритм этой функции Apriorigen в виде небольшого SQL-подобного запроса.
insert into Ck
select p.item1, p.item2, …, p.itemk-1, q.itemk-1
From Fk-1 p, Fk-1 q
where p.item1= q.item1, p.item2 = q.item2, …, p.itemk-2 = q.itemk-2, p.itemk-1 < q.itemk-1
2. Удаление избыточных правил. На основании свойства анти-монотонности, следует удалить все наборы c Ck если хотя бы одно из его (k-1) подмножеств не является часто встречающимся.
После генерации кандидатов следующей задачей является подсчет поддержки для каждого кандидата. Очевидно, что количество кандидатов может быть очень большим и нужен эффективный способ подсчета. Самый тривиальный способ – сравнить каждую транзакцию с каждым кандидатом. Но это далеко не лучшее решение. Гораздо быстрее и эффективнее использовать подход, основанный на хранении кандидатов в хэш-дереве. Внутренние узлы дерева содержат хэш-таблицы с указателями на потомков, а листья – на кандидатов. Это дерево нам пригодится для быстрого подсчета поддержки для кандидатов.
Хэш-дерево строится каждый раз, когда формируются кандидаты. Первоначально дерево состоит только из корня, который является листом, и не содержит никаких кандидатов-наборов. Каждый раз когда формируется новый кандидат, он заносится в корень дерева и так до тех пор, пока количество кандидатов в корне-листе не превысит некоего порога. Как только количество кандидатов становится больше порога, корень преобразуется в хэш-таблицу, т.е. становится внутренним узлом, и для него создаются потомки-листья. И все примеры распределяются по узлам-потомкам согласно хэш-значениям элементов, входящих в набор, и т.д. Каждый новый кандидат хэшируется на внутренних узлах, пока он не достигнет первого узла-листа, где он и будет храниться, пока количество наборов опять же не превысит порога.
Хэш-дерево с кандидатами-наборами построено, теперь, используя хэш-дерево, легко подсчитать поддержку для каждого кандидата. Для этого нужно "пропустить" каждую транзакцию через дерево и увеличить счетчики для тех кандидатов, чьи элементы также содержатся и в транзакции, т.е. Ck Ti = Ck. На корневом уровне хэш-функция применяется к каждому элементу из транзакции. Далее, на втором уровне, хэш-функция применяется ко вторым элементам и т.д. На k-уровне хэшируется k-элемент. И так до тех пор, пока не достигнем листа. Если кандидат, хранящийся в листе, является подмножеством рассматриваемой транзакции, тогда увеличиваем счетчик поддержки этого кандидата на единицу.
После того, как каждая транзакция из исходного набора данных "пропущена" через дерево, можно проверить удовлетворяют ли значения поддержки кандидатов минимальному порогу. Кандидаты, для которых это условие выполняется, переносятся в разряд часто встречающихся. Кроме того, следует запомнить и поддержку набора, она нам пригодится при извлечении правил. Эти же действия применяются для нахождения (k+1)-элементных наборов и т.д.
После того как найдены все часто встречающиеся наборы элементов, можно приступить непосредственно к генерации правил.
Извлечение правил – менее трудоемкая задача. Во-первых, для подсчета достоверности правила достаточно знать поддержку самого набора и множества, лежащего в условии правила. Например, имеется часто встречающийся набор {A, B, C} и требуется подсчитать достоверность для правила AB C. Поддержка самого набора нам известна, но и его множество {A, B}, лежащее в условии правила, также является часто встречающимся в силу свойства анти-монотонности, и значит его поддержка нам известна. Тогда мы легко сможем подсчитать достоверность. Это избавляет нас от нежелательного просмотра базы транзакций, который потребовался в том случае если бы это поддержка была неизвестна.
Чтобы извлечь правило из часто встречающегося набора F, следует найти все его непустые подмножества. И для каждого подмножества s мы сможем сформулировать правило s (F – s), если достоверность правила conf(s (F – s)) = supp(F)/supp(s) не меньше порога minconf.
Заметим, что числитель остается постоянным. Тогда достоверность имеет минимальное значение, если знаменатель имеет максимальное значение, а это происходит в том случае, когда в условии правила имеется набор, состоящий из одного элемента. Все супермножества данного множества имеют меньшую или равную поддержку и, соответственно, большее значение достоверности. Это свойство может быть использовано при извлечении правил. Если мы начнем извлекать правила, рассматривая сначала только один элемент в условии правила, и это правило имеет необходимую поддержку, тогда все правила, где в условии стоят супермножества этого элемента, также имеют значение достоверности выше заданного порога. Например, если правило A BCDE удовлетворяет минимальному порогу достоверности minconf, тогда AB CDE также удовлетворяет. Для того, чтобы извлечь все правила используется рекурсивная процедура. Важное замечание: любое правило, составленное из часто встречающегося набора, должно содержать все элементы набора. Например, если набор состоит из элементов {A, B, C}, то правило A B не должно рассматриваться.
FPG - альтернативный алгоритм поиска ассоциативных правил
Введение
Узким местом в алгоритме a priori является процесс генерации кандидатов в популярные предметные наборы. Например, если база данных(БД) транзакций содержит 100 предметов, то потребуется сгенерировать 2100~1030sup> кандидатов. Таким образом, вычислительные и временные затраты, которые нужны на их обработку, могут быть неприемлемыми. Кроме этого, алгоритм a priori требует многократного сканирования базы данных транзакций, а именно столько раз, сколько предметов содержит самый длинный предметный набор. Поэтому был предложен ряд алгоритмов, которые позволяют избежать генерации кандидатов и сократить требуемое число сканирований набора данных.
Одним из наиболее эффективных процедур поиска ассоциативных правил является алгоритм, получивший название Frequent Pattern-Growth (алгоритм FPG), что можно перевести как «выращивание популярных (часто встречающихся) предметных наборов». Он позволяет не только избежать затратной процедуры генерации кандидатов, но уменьшить необходимое число проходов БД до двух. Рассмотрим его более подробно.
Алгоритм Frequent Pattern-Growth Strategy (FPG)
В основе метода лежит предобработка базы транзакций, в процессе которой эта база данных преобразуется в компактную древовидную структуру, называемую Frequent-Pattern Tree – дерево популярных предметных наборов (откуда и название алгоритма). В дальнейшем для краткости будем называть эту структуру FP-дерево. К основным преимуществам данного метода относятся:
1. Сжатие БД транзакций в компактную структуру, что обеспечивает очень эффективное и полное извлечение частых предметных наборов;
2. При построении FP-дерева используется технология разделения и захвата (англ.: divide and conquer), которая позволяет выполнить декомпозицию одной сложной задачи на множество более простых;
3. Позволяет избежать затратной процедуры генерации кандидатов, характерной для алгоритма a priori.
Рассмотрим работу алгоритма FPG на конкретном примере. Пусть имеется БД транзакций (табл. 1).
Таблица 1
| N | Предметный набор |
| a b c d e | |
| a b c | |
| a c d e | |
| b c d e | |
| b c | |
| b d e | |
| c d e |
Для данной БД требуется обнаружить все популярные предметные наборы с минимальной поддержкой, равной 3, используя алгоритм FPG.
1.
Производится первое сканирование БД транзакций, и отбирается множество часто встречающихся предметов, т.е. предметов, которые встречаются три или более раза. Упорядочим обнаруженные частые предметы в порядке возрастания их поддержки и получим следующий набор: (c, 6), (b, 5), (d, 5), (e, 5), (a, 3).
1. Построим FP-дерево. Сначала упорядочим предметы в транзакциях по убыванию значений их поддержек (табл. 2).
Таблица 2
| N | Исходный предметный набор | Упорядоченный предметный набор |
| a b c d e | c b d e a | |
| a b c | c b a | |
| a c d e | c d e a | |
| b c d e | c b d e | |
| b c | c b | |
| b d e | b d e | |
| c d e | c d e |
Сначала создадим начальный (корневой) узел FP-дерева, который обычно обозначают ROOT (от англ. root – корень).
Начнем построение дерева с транзакции №1 для упорядоченных предметных наборов, т.е. (c b d e a), рис. 1. При построении дерева будем придерживаться следующего правила.
| Правило 1.Если для очередного предмета в дереве встречается узел, имя которого совпадает с именем предмета, то предмет не создает нового узла, а индекс соответствующего узла в дереве увеличивается на 1. В противном случае для этого предмета создается новый узел и ему присваивается индекс 1. |
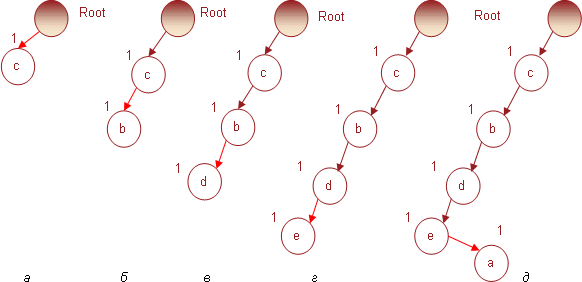
Рис. 1. Построение FP-дерева на транзакции № 1
Сначала берем предмет с из транзакции №1. Поскольку он является первым, то формируем для него узел и соединяем с родительским (корневым) (рис. 1, а). Затем берем следующий предмет b и поскольку других узлов с тем же именем дерево пока не содержит, добавляем его в виде нового узла, потомка узла с (рис 1, б).Таким же образом формируем узлы для предметов d, e и a из транзакции № 1 (случаи в, г, и д на рис 1). На этом использование первой транзакции для построения дерева закончено.
Для транзакции № 2, содержащей предметы c, b и a, выбираем первый предмет, c. Поскольку дочерний узел с таким именем уже существует, то в соответствии с правилом построения дерева новый узел не создается, а добавляется к уже имеющемуся (рис. 2, а). При добавлении следующего предмета b используем то же правило: поскольку узел b является дочерним по отношению к текущему (т.е. c), то мы также не создаем новый узел, а увеличиваем индекс для имеющегося (рис. 2, б). Для следующего предмета из второй транзакции a в соответствии с правилом построения FP-дерева придется создать новый узел, поскольку у узла b дочерние узлы с именем a отсутствуют (рис. 2, в).
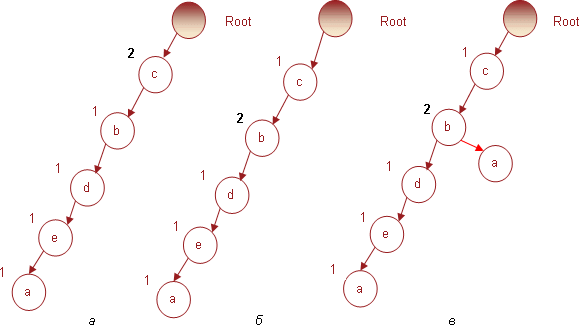
Рис. 2. Построение FP-дерева на транзакции № 2
Транзакция № 3 содержит предметы (c d e a). В соответствии с правилом построения FP-дерева, предмет c не создаст нового узла, а увеличит индекс уже имеющегося узла на 1 (рис. 3, а). Следующий предмет d породит в дереве новый узел, дочерний к c, поскольку тот не содержит потомков с таким именем (рис 3, б). Аналогично предметы e и a создадут новые узлы – потомки d (рис. 3 в, г).
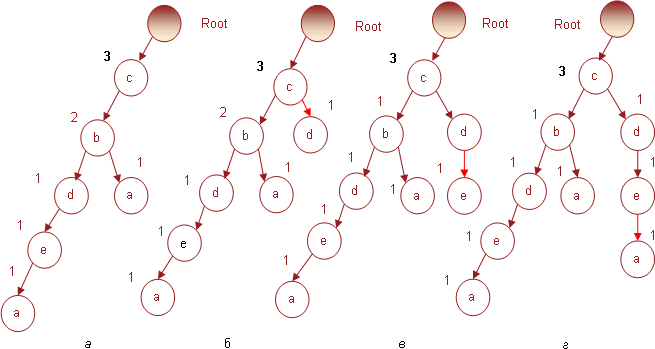
Рис. 3. Использование транзакции № 3 для построения FP-дерева
Использование транзакции № 4, содержащей набор предметов (c b d e), не создаст новых узлов, а увеличит индексы узлов с аналогичной последовательностью имен. Дерево, полученное в результате использования четвертой транзакции, представлено на рис 4.
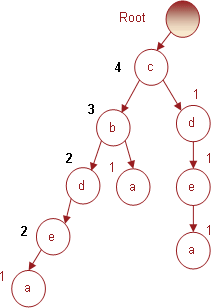
Рис. 4. Дерево, полученное в результате использования четвертой транзакции
Транзакция № 5 содержит набор c b, предметы которого увеличат индексы одноименных узлов в дереве, как показано на рис. 5.
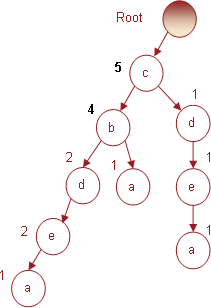
Рис. 5. Дерево, полученное в результате использования пятой транзакции
Транзакция № 6 содержит предметы (b d e). Поскольку корневой узел не содержит непосредственного потомка с именем b, то в соответствии с правилом построения дерева для него будет создан новый узел, который «потянет» за собой два других – d и e. Все узлы будут добавлены с индексами 1. В результате дерево примет вид, представленный на рис. 6.
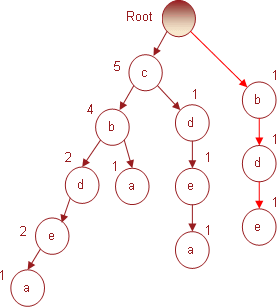
Рис. 6. Дерево, полученное в результате использования 6-й транзакции
И, наконец, последняя транзакция № 7, содержащая предметный набор (c d e), увеличит на 1 индексы соответствующих узлов. Получившееся дерево, которое также является результирующим для всей БД транзакций, представлено на рис. 7.
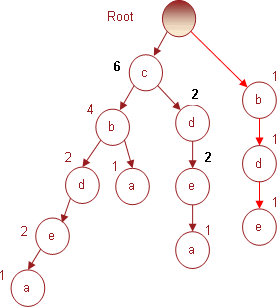
Рис. 7. Результирующее дерево, построенное по всей БД транзакций
Таким образом, после первого прохода базы данных и выполнения соответствующих манипуляций с предметными наборами мы построили FP-дерево, которое в компактном виде представляет информацию о частых предметных наборах и позволяет производить их эффективное извлечение, что и делается на втором сканировании БД.
Представление базы данных транзакций в виде FP-дерева очевидно. Если в исходной базе данных каждый предмет повторяется многократно, то в FP-дереве каждый предмет представляется в виде узла, а его индекс указывает на то, сколько раз данный предмет появляется. Иными словами, если предмет в исходной базе данных транзакций появляется 100 раз, то в дереве для него достаточно создать узел и установить индекс 100.
Извлечение частых предметных наборов из FP-дерева
Для каждого предмета в FP-дереве, а точнее, для связанных с ними узлов, можно указать путь, т.е. последовательность узлов, которую надо пройти от корневого узла до узла, связанного с данным предметом. Если предмет представлен в нескольких ветвях дерева (что чаще всего и происходит), то таких путей будет насколько. Например, для FP-дерева на рис. 7 для предмета a можно указать 3 пути: { cbdea, cba, cdea }. Такой набор путей называется условным базисом предмета (англ.: conditional base). Каждый путь в базисе состоит из двух частей – префикса и суффикса. Префикс – это последовательность узлов, которые проходит путь для того чтобы достичь узла, связанного с предметом. Суффикс – это сам узел, к которому «прокладывается» путь. Таким образом, в условном базисе все пути будут иметь различные префиксы и одинаковый суффикс. Например, в пути cbdea префиксом будет cbde, а суффиксом – a.
Процесс извлечения из FP-дерева частых предметных наборов будет заключаться в следующем.
2.
Выбираем предмет (например, a) и находим в дереве все пути, которые ведут к узлам этого предмета Иными словами, для a это будет набор { cbdea, cba, cdea }. Затем для каждого пути подсчитываем, сколько раз данный предмет встречается в нем, и записываем это в виде (cbdea, 1), (cba, 1) и (cdea, 1).
1. Удалим сам предмет (суффикс набора) из ведущих к нему путей, т.е. { cbdea, cba, cdea }. После это останутся только префиксы: { cbde, cb, cde }.
2. Подсчитаем, сколько раз каждый предмет появляется в префиксах путей, полученных на предыдущем шаге, и упорядочим в порядке убывания этих значений, получив новый набор транзакций.
3. На его основе построим новое FP-дерево, которое назовем условным FP-деревом (conditional FP-tree), поскольку оно связано только с одним объектом (в нашем случае, a).
4. В этом FP-дереве найдем все предметы (узлы), для которых поддержка (количество появлений в дереве) равна 3 и больше, что соответствует заданному уровню минимальной поддержки. Если предмет встречается два или более раза, то его индексы, т.е. частоты появлений в условном базисе, суммируются.
5. Начиная с верхушки дерева, записываем пути, которые ведут к каждому узлу, для которого поддержка/индекс больше или равны 3, возвращаем назад предмет (суффикс шаблона), удаленный на шаге 2, и подсчитываем индекс/поддержку, полученную в результате. Например, если предмет a имеет индекс 3, то можно записать (c b a, 3), что и будет являтьсяпопулярным предметным набором.
Для пояснения методики извлечения шаблонов из FP-дерева продолжим рассмотрение примера для БД транзакций из табл. 1 и построенного для неё FP-дерева.
Начнем с предмета a, который имеет поддержку 3 и соответственно является часто встречающимся предметом. Префиксы путей, ведущих к узлам, связанным с a, будут: (c b d e a, 1), (c b a, 1), (c d e a, 1). На основе полученного условного базиса для суффикса a, построим условное FP-дерево (рис. 8).
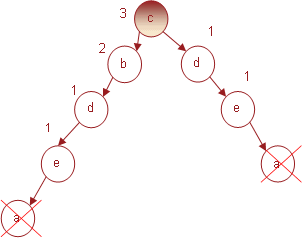
Рис. 8. Условное FP-дерево для предмета a
Поскольку предметы d и e встречаются два раза, то их индексы суммируются, и в итоге мы получим следующий порядок предметов: (c, 3), (b, 2), (d, 2), (e, 2). Таким образом, только узел c удовлетворяет уровню минимальной поддержки 3. Следовательно, для предмета a может быть сгенерирован только один популярный набор (c, a, 3).
Затем переходим к следующему предмету b с поддержкой 5. Условное FP-дерево, построенное для него, будет содержать только один узел c, поскольку в дереве присутствует один путь с => b, а суффикс b исключается. Это проиллюстрировано на рис. 9.
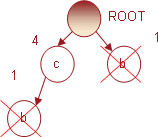
Рис. 9. Условное FP-дерево для суффикса b
Таким образом, префиксы путей будут (c b, 4) и (b, 1), и, следовательно, для предмета b будет иметь место только один популярный набор (c b, 4).
Для предмета c, поскольку он является непосредственным потомком корневого узла, нельзя указать путь (см. рис 7). Значит, префикс путей для него будет пустым, из чего следует, что и популярные предметные наборы отсутствуют.
Следующий предмет, для которого мы произведем поиск популярных предметных наборов, будет d с поддержкой равной 5. Условное FP-дерево, связанное с предметом d представлено на рис. 10.
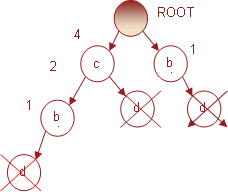
Рис. 10. Условное FP-дерево для предмета d
Префиксы путей для условного дерева, связанного с предметом d, будут: (c b d, 2), (c d, 2) и (b dd, 1). Учитывая, что индексы для узлов b суммируются, то соответствующие популярные предметные наборы будут (c, d, 4) и (b, d, 3).
И, наконец, для последнего предмета е, имеющего поддержку 5, условное FP-дерево представлено на рис. 11.
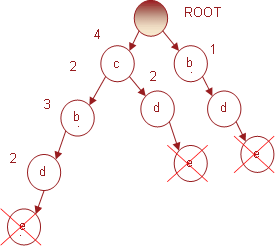
Рис. 11. Условное FP-3 дерево для предмета e
Префиксы путей, ведущих в условном дереве к узлам, связанным с предметом e, будут: (c b d e, 2) (c d e, 2) (b d e, 1). Подсчитав суммарную поддержку каждого предмета в условном дереве и упорядочив предметы по ее убыванию, получим: (d, 5), (c, 4), (b, 3). Следовательно, популярными предметными наборами для предмета e будут: (d, e, 5), (d, c, e, 4), (d, b, e, 3).
Таким образом, мы получили следующие популярные предметные наборы:
(c, a, 3), (c, b, 4), (c, d, 4), (b, d, 3), (d, e, 5), (d, c, e, 4), (d, b, e, 3).
Сравнительные исследования классического алгоритма a priori и FPG показали, что с увеличением числа транзакций в БД временные затраты на поиск частых предметных наборов растут для FPG намного медленнее, чем для a priori (рис. 12).
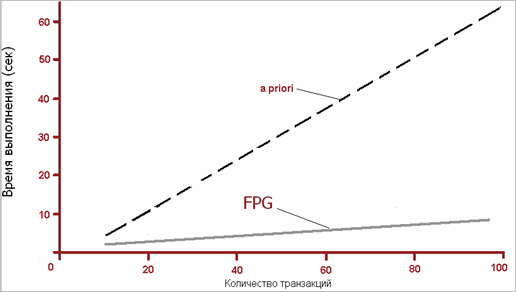
Рис. 12. Сравнение алгоритмов FPG и a priori
Повышение эффективности обработки популярных наборов
Одним из направлений повышения эффективности обработки популярных предметных наборов является сокращение необходимого числа сканирований базы данных транзакций. Алгоритм a priori сканирует базу данных несколько раз, в зависимости от числа элементов в предметных наборах. Существует ряд алгоритмов, позволяющих уменьшить необходимое число сканирований набора данных или количество популярных предметных наборов, генерируемые на каждом сканировании, либо оба этих показателя.
Одним из таких методов является алгоритм разделения (Partition-based Apriori algorithm), который требует всего два прохода по набору данных. Он основан на идее так называемых локальных предметных наборов. При этом весь набор данных разделяется на N непересекающихся подмножеств, каждое из которых достаточно мало, чтобы поместиться в оперативной памяти ПК. На первом сканировании алгоритм считывает каждое подмножество и обнаруживает предметные наборы, которые являются популярными для данного подмножества (локальные предметные наборы). На втором сканировании алгоритм вычисляет поддержку всех локальных популярных предметных наборов относительно всего набора данных. Таким образом, второе сканирование определяет множество всех потенциальных ассоциативных правил. Методика, реализуемая данным алгоритмом, поясняется на рис. 13.
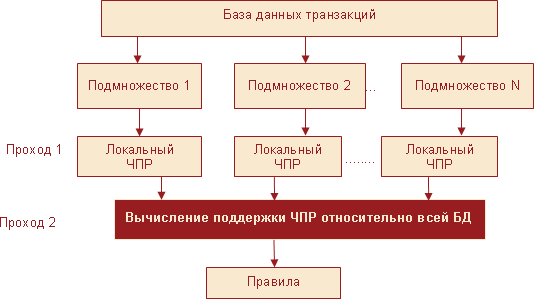
Рис. 13. Метод локальных предметных наборов
Еще одним способом повышения эффективности методики, основанной на популярных наборах, является сэмплинг (рис. 14). С помощью его производится отбор случайной выборки R исходной базы данных транзакций, после чего поиск популярных наборов осуществляется на этой выборке. Здесь ищется компромисс между точностью и эффективностью решения задачи. Размер выборки, полученной в результате сэмплинга, должен быть таким, чтобы обеспечить приемлемые вычислительные затраты. Очевидно, что при этом некоторые популярные наборы могут быть потеряны. Чтобы свести потери к минимуму, используют порог поддержки ниже, чем минимальная поддержка для поиска частых предметных наборов, локальных на R.
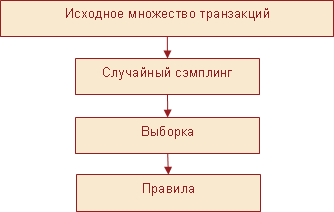
Рис. 14








