 2015-04-01
2015-04-01 2008
2008В настоящее время, в эпоху глобальной компьютеризации, возникает потребность в обработке огромных массивов информации, с которыми человеку не справиться именно по причине их объема: информация устаревает и становится неактуальной, невероятно затруднен поиск. Использование ЭВМ позволяет во много раз повысить эффективность такого рода деятельности. Естественно, в чистом виде подобные операции неформализуемы и попытки смоделировать работу мозга пока еще к ошеломляющим результатам не привели.
С развитием Интернет и новых способов представления знаний, таких, как гипертекст, появилось много возможностей для концептуального представления информации. Это очень удобно, так как переводить текстовые документы в формат HTML просто. Как можно видеть, сеть даже в нашей стране развивается стремительно. Растет количество различных сайтов, представляющих информацию по разнообразным тематикам. Но вопрос структуризации так и остался неразрешенным. При наличии большого количества документов, которые нужно разместить на сайте организации, веб-мастер тратит очень много времени на то, чтобы: а) разобраться в имеющейся информации; б) систематизировать ее; в) реализовать структуру в Интернет. Задача, как мы видим, осложняется тем, что человек, занимающийся созданием сайтов не должен в общем случае иметь специальных знаний о сфере деятельности организации.
Информационный поиск (ИП) - это область исследований, которая разрабатывает методы для обработки больших неструктурированных массивов информации, в том числе и текстовых массивов. Существует два основных направления исследований в ИП: улучшение автоматического поиска по запросу и улучшение ручного поиска. Первый применяется тогда, когда пользователь информационно-поисковых систем (ИПС) знает точно, что он хочет найти, второй, – когда он не может четко сформулировать запрос к системе или вообще не имеет представления о содержащихся в ней знаниях. Оба метода дополняют друг друга и показывают наибольшую эффективность при совместном использовании. Например, релевантность результатов автоматического поиска повышается, когда пользователь сужает область поиска до отдельной тематической категории.
Для обеспечения удобного, качественного ручного поиска необходимо наличие у коллекции документов простой и понятной структуры. В рамках этой потребности и второй основной задачи ИП выделяются следующие подзадачи:
Кластеризация документов.
Целью кластеризации документов является автоматическое выявление групп семантически похожих документов среди заданного фиксированного множества документов. Группы формируются только на основе попарной схожести описаний документов, характеристики этих групп заранее не заданы.
В отличие от задачи кластеризации, целью классификации является определение для каждого документа одной или нескольких из заранее заданных категорий, к которым этот документ относится. Особенностью задачи классификации является предположение, что каждый из документов соответствует какой-нибудь из заданных категорий.
Фильтрация документов.
Как и в задаче классификации, целью задачи фильтрации является разбиение множества документов на категории. Однако этих категорий только две – те документы, которые удовлетворяют заданному критерию, и те, которые ему не удовлетворяют.
Методы решения различны для каждого класса задач.
В последние годы интерес к ИП резко возрос, в связи с ростом всемирной глобальной сети Интернет. Ряд важных особенностей отличает Интернет от других массивов информации. Это и огромный объем доступной информации (на февраль 2000 года в Интернет было опубликовано более миллиарда страниц и их число увеличивается экспоненциально), и высокий процент временной информации (согласно некоторым оценкам ежемесячно изменяется около 40% информации), и неконтролируемое качество информации, и, наконец, разнородность информации.
Каждое из направлений исследований ИП находит практическое применение в ИПС, обслуживающих пользователей Интернет. Количество существующих ИПС исчисляется сотнями, причем, существуют как многоцелевые системы, так и специализированные (книги, музыка, погода и т. п.).
Эти ИПС производят индексацию найденных в сети документов и обеспечивают поиск, как по введенному запросу, так и в соответствии с классификатором, большинство современных систем поиска в Internet классифицируют вновь прибывшие документы по тематикам. Тем не менее, практически любые ссылки, найденные с помощью ИПС, лишь позволяют попасть на основную страницу сайта и, далее, процесс поиска необходимой информации происходит самостоятельно, по внутренним ссылкам сайта (как правило, глубина индексирования сайта невелика, в основном первые страницы и те, на которые они ссылаются).
Встречаются сайты с собственной поисковой системой, работающей по запросу. В такой ситуации встает проблема ручного поиска, которая решается с помощью наличия качественной карты сайта, хорошо разработанной структуры документов и перекрестных ссылок в этих документах. Задача создания этих средств не может решаться с помощью современных поисковых систем, поскольку каждый сайт имеет свою особенную структуру, разрабатываемую его создателями.
Поисковые системы не в состоянии обеспечить навигацию по отдельному сайту, поскольку каждая из них производит общую классификацию всех найденных в Internet документов с помощью заранее составленных тематических классификаторов.
Если на сайте расположено около 100 – 200 документов, причем, создатель сайта либо имеет заранее структуру этой коллекции, либо очень хорошо разбирается в предметной области, к которой относятся документы, то задача организации структуры сайта и расстановки ссылок в документах представляется вполне решаемой без привлечения дополнительных средств.
Однако если коллекция документов содержит 500 экземпляров и больше, то для подробной детализации структуры этого набора и определения смысловой близости одного документа, часто требуется привлечение дополнительных специалистов.
Чем сложнее предметная область и разнороднее информация, представленная в документах, тем больше времени и средств требуется для разработки удобной, визуальной структуры собранных на сайте документов. Разумеется, эта задача актуальна не только для баз документов в Internet, она важна для информационных отделов предприятий, для библиотек и для любых специализированных хранилищ информации.
Разработка любого сайта неизбежно начинается с проектирования его будущей структуры, в этом процессе совместно участвуют веб-дизайнер и заказчик. Структура сайта определяется как набором стандартных разделов, характерных для большинства сайтов сети, так и его специфическим контентом. По сравнению с другими, этап создания структуры сайта, является наименее автоматизированным, актуальной является задача облегчить труд разработчиков и избавить их от необходимости детально вникать в содержание всех документов, предназначенных для публикации на сайте. Наша основная идея в том, чтобы на основе машинного анализа текстов, выделить семантически связанные участки контента, ранжировать их по важности и предложить вариант их оптимального размещения, список перекрестных ссылок и переходов, а также граф, отображающий подробную структуру сайта.
Современное состояние дел в разработке веб-приложений таково, что разработчики вооружены мощнейшими технологиями программирования, специальными языками скриптов и баз данных, графическими пакетами и html-редакторами. При этом явно не хватает концептуальных средств проектирования, все целиком опирается на собственный опыт веб-мастера и планы заказчика.
Недостатками подобного подхода является ряд моментов:
- разработчик может быть плохо знаком с предметной областью сайта, для создания структуры придется изучать всю информацию на сайте;
- размеры некоторых сайтов достигают нескольких тысяч страниц, в результате чего создание структуры обычными методами может быть сильно затруднено;
- основой большинства сайтов является древовидная структура.
Те же трудности существуют в файлах помощи, где важность корректного расположения ссылок намного выше. Иногда бывает невозможно отыскать нужную информацию в десятках мегабайт помощи. В результате возникла необходимость создания утилиты вебмастеринга, призванной повысить эффективность работы проектировщика.
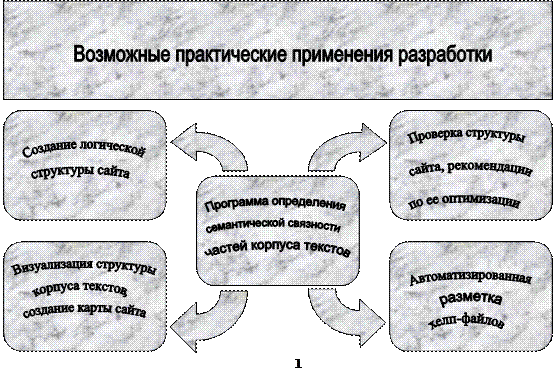
Рисунок 1. Практическое применение разработки
Путем анализа семантики участков будущего контента сайта должна генерироваться его структура, либо должна проводиться оптимизация уже существующей структуры, что позволит сэкономить средства на разработку и поддержку сайта. Таким образом, определился круг проблем положенных в основу разработки, изображенный на рисунке 1.Вы наверняка пользовались какими-либо поисковыми системами в Интернет и знаете, что найти именно то, что вы хотели, порой бывает очень трудно. Иногда мы проводим гораздо больше времени в поисках необходимой информации, нежели собственно в ее получении и интеллектуальной обработке. Как уже было отмечено, эта проблема, в свою очередь, распадается на две составляющие: проблема ИП и проблема неоптимальной логической структуры сайтов и расставленных на них ссылок. Обе эти проблемы можно решить с помощью нескольких методов. Но если проблему ИП – релевантной и точной выдачи информации в ответ на запрос должны решать поисковые сервера, то проблему структуризации информации решают создатели сайтов – в общем случае – мы с вами.
Какими методами решаются подобные задачи? При использовании простого синтаксического анализа мы не можем установить соответствия между синонимами, например, и не можем различать случаи полисемии. К тому же, методы семантического анализа текста, сочетающие морфологический анализ с синтаксическим и устанавливающие на основе этого примерный смысл текста весьма и весьма громоздки (ЭТАП-3). Следовательно, для обработки массивов информации, которая по историческим причинам хранится в текстовом виде, нужно что-то принципиально отличающееся от прямого лексического сравнения (см. Гл.1).
В настоящее время существуют методы обработки текстов, учитывающие семантические связи между элементами языка. Обычно они работают в связке с синтаксическими методами и, так как мы говорим о компьютерной обработке текста, их входной информацией является выходная информация синтаксического блока. Вышеперечисленные методы имеют различные недостатки, в большей или меньшей степени, но главный враг, безусловно, неточность. Существуют и вероятностные семантические методы.
Перспективным направлением можно назвать применение для коллекции документов РСА (principal component analyses, анализ ключевых составляющих) – класса методов кластерного анализа. Он позволяет на основе матрицы встречаемости терм-документ высчитывать направление наибольшего различия и таким образом дробить кластеры. Данный подход весьма эффективен, но его проблемы, и проблемы всех прямых кластерных методов в том же: в своей работе они используют лексику, а не семантику, зато преимущество в том, что синтаксис они не используют.
Исходя из изложенного, можно определить требования к методу семантического анализа корпуса текстов, диктуемые современной ситуацией:
- метод не должен использовать прямое лексическое сравнение;
- синтаксис по возможности должен быть опущен, как загромождающий;
- основной упор должен быть сделан на семантику, смысл текста;
- метод должен справляться с синонимией, полисемией, омонимией;
- эффективность метода должна приближаться к эффективности работы человека.
Сейчас в этой отрасли в связи с развитием численных методов решения задач, даже не решающихся аналитически, и с постоянным увеличением вычислительной мощности компьютеров, наметились подходы, органично синтезирующие классические теоретические исследования в лингвистике, психологии, математике с численными методиками.
В вычислительной лингвистике и вообще, в задачах, связанных с обработкой текстовой информации, сейчас наибольшей популярностью пользуются методы, основанные на моделях многомерных векторных пространств, в которых определяются вектора документов набора.
Эти методы представляют запросы и документы в виде многомерных векторов и рассчитывают их близость на основе их внутреннего произведения или угла между ними. Компонентами таких векторов могут быть веса термов или сами вектора могут быть спроецированы в другое пространство, измерения которого несут другую информацию.
Далее результаты обрабатываются с целью создания нужного представления, используя разнообразные математические методы, как-то: ЛСА (латентно-семантический анализ), кластерный анализ, группировка по степени схожести и другие. Было выяснено, что такие модели наиболее адекватно отражают структуру употребления слов человеком и наиболее близки к идеалу в области объяснения структуры человеческих знаний и моделирования естественного языка.
Зарубежными авторами было произведено множество экспериментов по нахождению оптимального метода для информационного поиска и структуризации информации. Основываясь на проведенных сравнениях, можно с уверенностью сказать, что метод ЛСИ (латентно-семантической индексации) дает наилучшую производительность с учетом больших возможностей, предоставляемых методом. Исходя из вышеизложенной информации, считаем целесообразным построить нашу систему на методе ЛСИ, оптимизировав его соответственно нашим нуждам, тем самым привнеся в работу дополнительную научную новизну.
Рассмотрим вариант системы, позволяющей автоматизировать процесс структуризации документов внутри коллекции и расставить соответствующие гиперссылки.
Два первых блока реализуют латентный семантический анализ, с помощью которого система определяет степень близости между документами. Латентный семантический анализ применяется к векторной модели пространства документов и термов. ЛСА работает, используя концептуальные индексы, которые, в свою очередь, создаются с помощью ЛСИ – латентной семантической индексации. То есть задачей ЛСА является обработка созданного ЛСИ набора индексов и построения на их основе выводов о семантической близости проиндексированных термов.
ЛСИ минимизирует проблему лексических сравнений используя статистически полученные концептуальные индексы, отличающиеся от ключевых слов. ЛСИ полагает, что в наборе документов присутствует латентная структура словоупотребления и использует эту информацию для установления семантического наполнения текста.
В свою очередь латентной семантической индексацией называется проведение SVD-анализа (singular value decomposition) над матрицами, полученными из корпуса документов. Метод SVD используется для установления структуры в употреблении слов для всех рассматриваемых документах.
Парсинг текстов, выделение термов. На этом этапе производится морфологический анализ исходных текстов, выделяются все термы, встречающиеся в документах.
Удаление стоп-слов. На данном этапе из числа термов удаляются так называемые стоп-слова, это часто встречающиеся слова и словосочетания, которые характерны для всех документов и поэтому не нужны для анализа сходства документов.
Взвешивание термов. Блок производит глобальное и локальное взвешивания термов, входящих в матрицу терм-документ. Для взвешивания используются статистические меры и нормирование с помощью энтропии.
Оптимизация матрицы терм-документ для SVD-анализа. Для уменьшения вычислительной сложности и повышения качества анализа созданная матрица терм-документ приводится к наиболее удобной форме.
SVD-анализ матрицы терм-документ. Этот блок производит SVD-разложение матрицы и реализует механизм латентного семантического анализа с заданным значением факторов k. Он декомпозирует матрицу и, на основе полученной информации, сокращает ее размерность, сохраняя при этом латентную структуру словоупотребления. SVD находит полный набор базисных векторов термового пространства матрицы терм-документ. Это делается таким образом, что удаление одного или нескольких векторов из базиса приведет к минимальным из возможных изменениям в ненормализованном внутреннем произведении любой пары векторов из набора. В этом блоке также происходят операции по обновлению содержимого матрицы, его добавлению или удалению. Этот блок – самый ресурсоемкий, поэтому нуждается в тщательной оптимизации.
Кластеризация гипертекста. В этом блоке производится кластеризация документов, то есть выделение иерархии семантически связанных групп документов.
Визуализация структуры гипертекста. Функция данного блока заключается в графическом представлении структуры и обеспечении удобной навигации по гипертексту.
Создание проекции структуры с помощью "пружинной" модели. Данный блок позволяет расположить графическое представление документов на экране таким образом, чтобы узлы графа не перекрывали друг друга, и все связи между ними были легко обозримы. "Пружинная" модель - это алгоритм для представления графов в двухмерном и трехмерном пространствах.
Генерация карты сайта. С помощью этого блока основа структуры сайта выделяется в виде карты сайта и включается конечную структуру гипертекста. Карта сайта используется посетителями сайта для навигации.
Задача данного исследования – поставить в соответствие задачам системы наиболее подходящий теоретический аппарат.
В связи с так называемым "информационным взрывом" новые требования предъявляются к системам поиска и навигации в массивах информации, а следовательно, и к механизмам их построения. Качественно различают две составляющие системы ИП: технологическую и концептуальную. К технологическим составляющим можно отнести средства пользовательского интерфейса, новые алгоритмы обработки текста, индексации и поиска, интеграцию информации из различных источников, сложные языки запросов и др. К концептуальным составляющим, прежде всего, относится система представления знаний об обрабатываемом материале, лежащем в основе механизма информационного поиска. В зависимости от типа системы различают несколько технологий поиска.
1) По-символьный поиск, происходящий без привлечения знаний о лексической, грамматической и семантической структуре обрабатываемого материала.
2) Поиск, в ходе которого используется лексико-грамматическая информация. Значит, привлекаются лингвистические словари, программы морфологического анализа текстов.
3) Семантический поиск, осуществляемый на основании знания об отношениях между понятиями предметной области, выраженными посредством слов естественного языка. Носителями такого рода информации являются тезаурусы, уже более трех десятилетий использующиеся для информационного поиска.
С развитием компьютерной техники появилось значительное количество разнообразных работ по автоматическому извлечению лингвистических и терминологических знаний из источника. При этом важным остается вопрос неадекватности и неоднозначности получаемой информации, которая должна в последствии интерпретироваться экспертами. Поэтому при автоматизации сложных интеллектуальных процессов важным является не только разработка автоматических процедур, но и:
1) обоснованность применения каждой из этих процедур в конкретном случае,
2) последовательность их применения,
3) относительный "вес" результатов применения каждой процедуры, позволяющий выбрать правильный (из ряда неодинаковых) в случае использования нескольких алгоритмов одновременно, а также
4) автоматически контролируемые действия эксперта.
Руководствуясь данными требованиями, мы провели выделение подзадач создания таких систем. Особое внимание при этом уделено результатам применения каждой модели или алгоритма, преимуществам и недостаткам конкретного алгоритма в сравнении с другими.

