 2015-04-01
2015-04-01 644
644Это базовый метод, от которого мы будем отталкиваться в своих исследованиях, и от которого отталкиваются все, занимающиеся проблемой лса. Терм-документная матрица а создается следующим образом. Ключевые слова или термы определяются в ней при помощи:
Составления списка встречаемости всех слов во всех документах;
Удаления стоп-слов – «однако», «для», предлогов, артиклей (см. [3]);
Удаления слов, которые встречаются только в одном документе или только один раз.
Оставшиеся слова и есть термы, которые мы нумеруем от 1 до m.
Пусть количество документов равно n. Создадим матрицу a размерностью m x n и определим ее как произведение трех матриц:
A = uåvt , (1)
Где utu = vtv = in, где in – единичная матрица порядка n (это свидетельство ортогональности транспонированных и не транспонированных матриц) и
å = diag(s1 ... sn); si >0 for 1 £ i £r; sj = 0 for j ³ r + 1,
Причем s1 ³s2³…³sn
Первые r (r= rank(а)) столбцов ортогональных матриц u и v задают собственные ортонормальные вектора, связанные с r ненулевых собственных значений матриц aat и ata соответственно (они являются базисными для u и v).
Столбцы (u1... un) и (v1... vn) матриц u и v являются левыми и правыми сингулярными векторами.
Сингулярные значения матрицы a, определенные как диагональные элементы матрицы å, являются неотрицательными квадратными корнями n собственных значений aat . Они хранят результаты нормализации u и v и расположены в убывающем порядке.
Геометрически это можно истолковать так: в данной матрице а вектору х Î rn сопоставляется вектор y = ax Î rm.
Далее можно выбрать одну ортогональную систему координат для rn (где осями являются столбцы v) и вторую ортогональную систему координат (где осями являются столбцы u) так, что матрица а – диагональная (å), то есть сопоставляет вектору 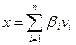 вектор
вектор 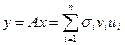 или si: vi ® ui.
или si: vi ® ui.
В общем случае, матрица а получается достаточно большой размерности, поэтому используется так называемая аппроксимация svd, когда из числа всех столбцов матриц оставляются только первые k столбцов, несущих самую важную часть информации о структуре матрицы, и соответственно, о латентной структуре словоупотребления в документах.
Иными словами это k-ранговая аппроксимация матрицы а:
A ≈ Ak ≡ Uk åk VkT . (2)
В результате svd-анализа можно подобрать базис, который наилучшим образом будет представлять данный набор документов.
Этот метод используется как базовый всеми исследователями, работающими с svd. Он несколько статичен, ничего не говорится про обновление информации, что особенно важно в интернет, где содержание страниц меняется весьма часто. С другой стороны, это основа для остальных методов, поэтому не будем на нем останавливаться долго, так как в таком виде он все равно применяется редко. Все исследователи стремятся его улучшить, этим же займемся и мы.








