 2015-05-10
2015-05-10 1357
1357При использование метода экспоненциального сглаживания влияние прошлых наблюдений должно затухать по мере удаления от момента времени, для которого определяется средняя, в отличие от метода скользящей средней, где оно высчитывалось с одинаковыми весовыми коэффициентами. Простая форма модели Брауна записывается следующим образом:
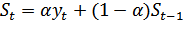
где:
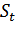 - текущее значение экспоненциальной средней в момент t;
- текущее значение экспоненциальной средней в момент t;
α- коэффициент, характеризующий вес текущего наблюдения при расчёте экспоненциальной средней 0 < α< 1. Еще называют сглаживающим фильтром, через него устанавливается баланс между влиянием на значение текущей модельной оценки уровня ряда и предшествующих модельных оценок.
Также как и в прошлом пункте проведём серию экспериментов, анализируя зависимость точности прогнозирования от 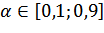 (с шагом 0,2) и применим оптимизация для модели с наилучшими показателями.
(с шагом 0,2) и применим оптимизация для модели с наилучшими показателями.
Для оценки точности прогнозирования используем те же показатели, что и в прошлом пункте, а именно:
1. Коэффициент несоответствия Тейла (KT).
2. Стандартная ошибка модели (RMSE).
Результаты представим в виде таблицы 5:
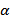 | RMSE | КT |
| 0,1 | 80,0525 | 0,0528 |
| 0,3 | 48,8842 | 0,0197 |
| 0,5 | 39,6979 | 0,0130 |
| 0,7 | 38,8135 | 0,0124 |
| 0,9 | 42,0973 | 0,0146 |
Таблица 5. Сравнение моделей экспоненциального сглаживания Брауна.
При сравнении полученных характеристик, можно сделать вывод, что наилучшим вариантом прогнозирования на основе модели Брауна первого порядка является модель, для которой коэффициент α = 0,7. Применив для нее оптимизацию в Statgraphics получим α = 0,639
Построим для модели с коэффициентом α = 0,639 доверительный интервал прогноза на 30.11.2012 (95-ый месяц):
| Lower 95,0% | Upper 95,0% | ||
| Period | Forecast | Limit | Limit |
| 30.11.2012 | 260,123 | 184,582 | 335,664 |
Таблица 6. Результат прогноза по наилучшей модели Брауна.
который рассчитывается по формуле:
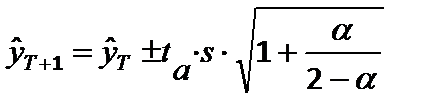
Далее проверим остатки модели на их соответствие процессу белый шум:








