 2015-05-18
2015-05-18 20904
209045.1. Основные понятия
Многопроцессорная система (МПС) – система, в которой команды на шине могут быть восприняты более чем от одного микропроцессора. Шиной управляют поочередно много процессоров.
Многопроцессорная система содержит несколько процессоров, работающих с общей оперативной памятью (общее поле оперативной памяти), и управляется одной общей операционной системой (рис. 16). Часто в микропроцессорной системе организуется общее поле внешних запоминающих устройств (ВЗУ).
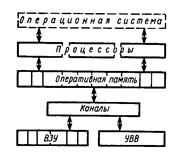
Рис. 16. Структура одноуровневой многопроцессорной системы
Под общим полем понимается равнодоступность устройств. Общее поле памяти означает, что все модули оперативной памяти доступны всем процессорам и периферийным устройствам (ВЗУ, УВВ), общее поле ВЗУ означает, что образующие его устройства доступны любому процессору и каналу.
Появление многопроцессорных систем обусловлено рядом причин. Главная из них – стремление к дальнейшему повышению производительности вычислительных средств. Из-за недостаточной мощности микропроцессора во многих практических задачах (например, спектрального и корреляционного анализа), требующих необходимой обработки данных в реальном масштабе времени, выполнять на одном микропроцессоре необходимую работу неэффективно или даже невозможно, и тогда с микропроцессором используют другие средства вычислительной системы. При этом несколько микропроцессоров осуществляют параллельную (одновременную) обработку данных. Такое распараллеливание вычислений на нескольких процессорах существенно уменьшает время решения задач.
Кроме того, появление многопроцессорных систем вызвано необходимостью приближения вычислительных средств к территориально распределенным источникам и приемникам информации управляемых объектов и процессов. Такой путь снижает стоимость, повышает надежность и производительность указанных систем.
Наконец, еще одной причиной появления многопроцессорных систем является противоречие между низкой стоимостью микропроцессора и высокой стоимостью различных накопителей информации (на магнитном диске, магнитной ленте и т. д.), устройств ввода-вывода, средств отображения информации (дисплеев) и т. д. Данное противоречие можно разрешить, если много микропроцессоров совместно используют дорогостоящее периферийное оборудование.
Многопроцессорные системы представляют собой основной путь построения вычислительных систем сверхвысокой производительности. При создании таких систем возникает много сложных проблем, к которым в первую очередь следует отнести: распараллеливание вычислительного процесса (программ) для эффективной загрузки процессоров системы, преодоление конфликтов при попытках нескольких процессоров использовать один и тот же ресурс системы (например, некоторый модуль памяти), уменьшение влияния конфликтов на производительность системы, осуществление быстродействующих экономичных по аппаратурным затратам межмодульных связей.
Многопроцессорные системы могут быть однородными и неоднородными.
Однородные многопроцессорные системы – системы, содержащие однотипные процессоры.
Неоднородные многопроцессорные системы состоят из различных специализированных процессоров, реализующих, например, функции операционной системы, процессоров для матричных задач.
Многопроцессорные системы могут иметь одноуровневую или иерархическую (многоуровневую) структуру. В первом случае процессоры системы образуют один общий уровень обработки данных (рис. 16), во втором (рис. 17) система обычно содержит один главный и один или несколько подчиненных (вспомогательных) процессоров.
Подчиненный микропроцессор – микропроцессор, который находится под управлением главного микропроцессора компьютера.
Вспомогательные процессоры используются для выполнения различных уровней обработки информации. Обычно менее мощный вспомогательный процессор выполняет ввод информации с различных терминалов и ее предварительную обработку.
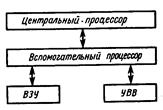
Рис. 17. Иерархическая многопроцессорная система
5.2. Разделение и распределение памяти
Одной из отличительных особенностей многопроцессорной вычислительной системы является сеть обмена, с помощью которой процессоры соединяются с памятью.
Рассмотрим структурную организацию однородных одноуровневых микропроцессорных систем, архитектура которых определяется организацией связи процессоров с оперативной памятью данных и организацией межпроцессорного обмена.
По способу организации связи процессоров с оперативной памятью данных все системы относятся к одному из трех типов: с общей (равнодоступной), индивидуальной (раздельной), индивидуальной основной и общей вспомогательной оперативной памятью данных.
Многопроцессорные системы с общей модульной оперативной памятью данных эффективны при решении такого класса задач, данные в которых могут быть размещены в различных модулях общей оперативной памяти. Тогда процессоры системы смогут работать с этими модулями с малыми взаимными помехами.
Система обладает наибольшей универсальностью, если информация, хранимая в любом модуле памяти, доступна любому процессору и устройству ввода-вывода. Эта универсальность достигается за счет аппаратурных затрат на организацию коммутации между любыми модулями памяти, процессорами и устройствами ввода-вывода. Затраты на такой матричный коммутатор растут пропорционально произведению числа модулей памяти на число процессоров и устройств ввода-вывода.
Структурная схема многопроцессорной системы с общей модульной памятью и матричным коммутатором приведена на рис. 18.
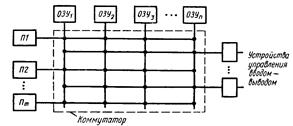
Рис. 18. Многопроцессорная система с матричной архитектурой
Каждый из процессоров П1,...,Пm имеет доступ к любому модулю оперативной памяти ОЗУ1,...,ОЗУn. Последние работают параллельно и допускают n одновременных обращений со стороны процессоров или устройств ввода-вывода. При обращении нескольких процессоров или устройств ввода-вывода к одному и тому же модулю памяти возникает конфликтная ситуация и коммутатор обслуживает первым устройство с наивысшим приоритетом.
Многопроцессорные системы с индивидуальной (раздельной) памятью данных эффективны для решения класса задач, где имеются четко разделимые подмножества данных, размещаемых в соответствующих модулях памяти. Структурная схема многопроцессорной системы с индивидуальной памятью приведена на рис. 19.
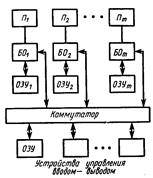
Рис. 19. Многопроцессорная система с индивидуальной памятью
Каждый процессор П1,...,Пm обращается к своему модулю оперативной памяти ОЗУ1,...,ОЗУm. Однако для редкого обмена данными между процессорами предусмотрены блоки обмена БО и вспомогательная общая оперативная память ОЗУ. Операции обмена инициируются процессорами.
На рис. 20 приведена схема многопроцессорной системы с индивидуальной памятью и одномодульной общей памятью данных. Такая система особенно эффективна для многопрограммной работы с коллективным использованием большого архива базовых данных. Устройство управления памятью регулирует возможные конфликты при одновременном обращении нескольких процессоров к общей одномодульной памяти данных.
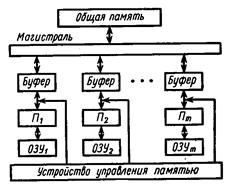
Рис. 20. Многопроцессорная система с общей памятью данных
5.3. Способы коммутации
На быстроту обмена информацией между модулями, а следовательно, и на производительность системы большое влияние оказывает способ коммутации процессоров. По способу коммутации все конкретные многопроцессорные системы относятся к одному из типов: структура с матричным коммутатором, общая магистральная структура (общая шина), матричная структура, последовательная конвейерная структура.
Многопроцессорные системы с матричным коммутатором (рис. 18) обладают наибольшей универсальностью. Широко распространены многопроцессорные системы, содержащие программируемый (универсальный) коммутатор, к которому подключаются входы и выходы всех процессоров и запоминающих устройств. В такой системе путем программирования может быть реализована практически любая из многочисленных структур многопроцессорных систем, однако она требует мощной системы коммутации, что связано со значительными аппаратными затратами.
Общая магистральная структура (рис. 21) отличается тем, что несколько процессоров подключаются к одной магистрали, которая осуществляет связь между любыми процессорами. Организация межпроцессорных связей на основе общей магистрали является одним из распространенных способов построения многопроцессорных систем. Такая система является наиболее простой, дешевой и легко наращиваемой.
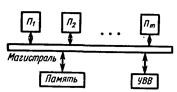
Рис. 21. Магистральная многопроцессорная система
Одновременно через общую магистраль информация передается между двумя устройствами, т. е. магистраль используется подключенными к ней устройствами в режиме разделения времени. Это является причиной возникновения конфликтов, при которых несколько устройств одновременно претендуют на занятие магистрали, что вызывает простой оборудования и уменьшает производительность системы. Для повышения пропускной способности магистрали иногда создают систему с несколькими параллельными магистралями.
Многопроцессорная система с матричной структурой представлена на рис. 22. Каналы связи организованы по принципу близкодействия: жесткие связи между собой имеют только соседние процессоры, а между отдаленными процессорами каналы связи отсутствуют. Обмен информацией между ними возможен только через цепочку процессоров.
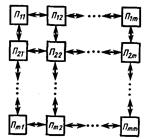
Рис. 22. Матричная многопроцессорная система
Последовательная конвейерная структура многопроцессорной системы (рис. 23) содержит цепочку последовательно соединенных процессоров, так что информация на выходе одного является входной информацией для другого. Процессоры образуют процессорный конвейер (трубопровод). На вход конвейера доставляется поток данных (операнды из памяти). Каждый процессор обрабатывает соответствующую часть задачи, передавая результаты соседнему процессору, который использует их в качестве исходных данных. Таким образом, решение задач для некоторых исходных данных развертывается последовательно в конвейерной цепочке. Это обеспечивается подведением к каждому процессору своего потока команд, т. е. имеется множественный поток команд.
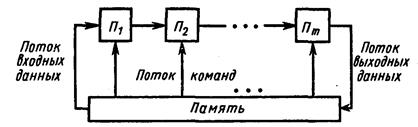
Рис. 23. Конвейерная многопроцессорная система
Если трубопровод заполнен, выходной процессор (Пm) выдает результаты для последовательности входных данных через очень короткие интервалы времени, хотя действительное время прохождения задачи через конвейер может быть существенно большим.
Кроме рассмотренной классификации многопроцессорных систем, широко используется классификация по признаку одинарности или множественности потоков команд и данных. Так, в соответствии с этой классификацией рассмотренную конвейерную систему (см. рис. 23) можно отнести к системам с одинарным потоком данных и множественным потоком команд.
В матричной структуре (см. рис. 22) имеется несколько потоков данных и один общий поток команд, т. е. все процессоры выполняют одновременно одну и ту же команду, но над разными операндами, доставляемыми процессорам из памяти несколькими потоками данных (рис. 24).
Имеются структуры многопроцессорных систем, в которых существует несколько потоков данных и несколько потоков команд.
Отметим, что однопроцессорная система в соответствии с рассматриваемым признаком классификации содержит одинарный поток данных.
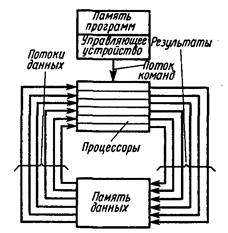
Рис. 24. Организация обработки данных в матричной системе
5.4. Организация вычислительного процесса
Организацию вычислений рассмотрим на примере вычисления быстрого преобразования Фурье (БПФ).
При спектральном анализе сигналов с широкой полосой частот (до десятков и сотен мегагерц) даже при использовании БПФ требования, предъявляемые к быстродействию вычислительной системы, оказываются весьма жесткими. Данная задача может быть решена только в рамках многопроцессорной организации вычислительной системы.
На рис. 25 показан граф, иллюстрирующий необходимую последовательность преобразований переменной х (в точках отсчета х0,...,х7) в коэффициенты дискретного ряда Фурье A0,…,A7.
Каждая вершина изображает переменную, а дуги исходят из тех вершин, которые вносят вклад в вершину, к которой направлена дуга. Все вклады аддитивны, и вес каждого вклада W j = exp(-2 jр/N) (где N – число точек отсчета анализируемой переменной) указан рядом с соответствующей дугой.
Из графа видно, что вычисление A 7 = B 3 + C 3 W 7 можно одновременно выполнить на N процессорах (в данном случае на восьми). Процессор Р i в исходном состоянии получает на вход одно из значений х (в порядке, указанном на рис. 25) и в конце вычисления выдает значение А i. Таким образом, горизонтальные пути на графе соответствуют обработке внутри процессора, а промежуточные вершины — промежуточным этапам вычисления. Остальные дуги графа определяют межпроцессорные обмены. На каждом этапе вычисления число обменов равно N. Результаты, полученные на любом этапе, нужны только для следующего этапа.
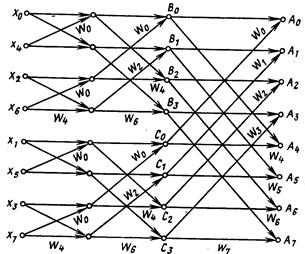
Рис. 25. Граф преобразования переменных хi в коэффициенты дискретного преобразования Фурье
Если на одном процессоре решение может быть получено за N·log2N шагов, то на N процессорах требуется в N раз меньше шагов.
Отметим, что в рассмотренном примере все обмены между процессорами предопределены, и управление ими сводится к осуществлению коммутации по заранее составленной программе. Поэтому требования к системе коммутации здесь значительно упрощены по сравнению с общим случаем, когда решение о коммутации надо принимать, исходя из результатов вычислений.
В данном случае все процессоры, начавшие вычисления, заняты их выполнением до получения результата. На практике процессоры освобождаются постепенно, причем, как правило, в неизвестные заранее моменты времени. Если освобождающийся ресурс не используется (он выделен только для данной работы), это приводит к снижению параллелизма и соответственно к снижению эффективности использования ресурсов системы.
Как следует из рассмотренного примера, обмены информацией между процессорами достигают большого значения, что может привести к малой эффективности многопроцессорной обработки. Поэтому выгоднее распараллеливать обработку данных более крупными блоками. За счет наличия в блоках операций самого различного характера появляется возможность наиболее полного использования процессоров.
В рассматриваемом примере процессоры работают таким образом, что данные, полученные на предыдущем этапе, необходимы для выполнения последующих операций. При отказе одного из процессоров общее решение оказывается неверным. Во избежание этого вычисления, ранее проводившиеся на отказавшем процессоре, необходимо продолжить на другом (исправном).
5.5. Способы взаимодействия процессоров в системах
Существует два основных способа взаимодействия процессоров в системах: один основан на использовании общей памяти, другой – на передаче сообщений.
В многопроцессорной системе с общей памятью один процессор осуществляет запись в конкретную ячейку, а другой – производит считывание из этой ячейки памяти. Чтобы обеспечить согласованность данных и синхронизацию процессов, обмен часто реализуется по принципу взаимно исключающего доступа к общей памяти.
Часто в машинах с общей памятью затраты на обмен не учитываются, так как проблемы обмена в значительной степени скрыты от программиста. Однако накладные расходы на обмен в этих машинах имеются и определяются конфликтами шин, памяти и процессоров. Чем больше процессоров добавляется в систему, тем больше процессов соперничают при использовании одних и тех же данных и шины, что приводит к состоянию насыщения. Модель системы с общей памятью очень удобна для программирования и иногда рассматривается как высокоуровневое средство оценки влияния обмена на работу системы, даже если основная система в действительности реализована с применением локальной памяти и принципа передачи сообщений.
В архитектурах с локальной памятью непосредственное разделение памяти невозможно. Вместо этого процессоры получают доступ к совместно используемым данным посредством передачи сообщений по сети обмена. Эффективность схемы коммуникаций зависит от протоколов обмена, основных сетей обмена и пропускной способности памяти и каналов обмена.
5.6. Применение сопроцессора х87 в машинах типа IBM PC
Примером многопроцессорной системы является использование сопроцессора.
Сопроцессор 8087 для 8086/8088 подключается параллельно практически ко всем интерфейсным сигналам центрального процессора. Отслеживая сигналы состояния процессора, сопроцессор вместе с ним просматривает и декодирует инструкции, “вылавливая” из них свои (по коду “Escape”). Если команда подразумевает обмен данными с памятью, процессор “помогает” сопроцессору в вычислении адреса, освобождая его от всех “хитростей” формирования физического адреса, принятых в 8086. После отработки всех циклов передачи процессор переходит к выполнению следующей инструкции, а сопроцессор начинает вычисления. Для сигнализации об исключительных ситуациях используется сигнал прерывания от сопроцессора INT. В IBM PC сигнал прерывания от сопроцессора через логическую схему поступает на вход NMI процессора и вызывает немаскируемое прерывание (вектор 2).
Сопроцессоры 80287 и 80387 с процессорами 80286 и 80386 обмениваются данными через шинные циклы ввода/вывода, автоматически генерируемые процессором.
Процессоры 486 и выше могут иметь лишь встроенный сопроцессор, интерфейс с внешним сопроцессором у них не предусмотрен.

