2015-05-10
2015-05-10 427
427Скопируем и отформатируем таблицу, как указано в предыдущем задании
Выберем инструмент
СТАТИСТИКА \ множественная регрессия
Зададим переменные:
В левой части зависимую, в правой определяющие.
Протокол результатов.
Клавиша Quick- протокол регрессионного анализа
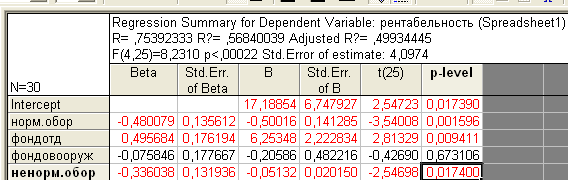
В верхней части протокола приведен общий протокол регрессионного анализа.
В-коэффициенты регрессии (красным отмечены значимые)
Т-статистика и и Р –level определяют уровни значимости по Р критерию и критерию Стьюдента.
Вета –нормализованные коэффициенты регрессии, Std Beta определяют стандартные ошибки вычислений.
Клавиша Advanced определяет полный регрессионный анализ.
ANOVA –дискриминационный анализ остатков (сумму квадратов, степени свободы, средние, уровень вероятности)
Covariance-матрицу парных ковариаций
Partial correlations-матрицу парных корреляций
Клавиша Residual \ assumptions
Отображает графики регрессионного анализа.
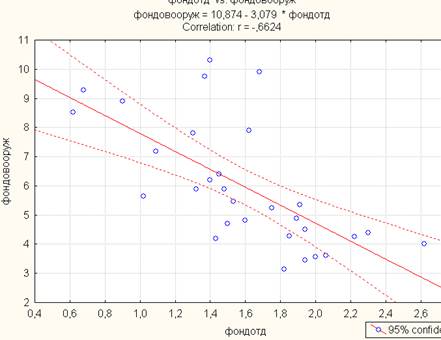
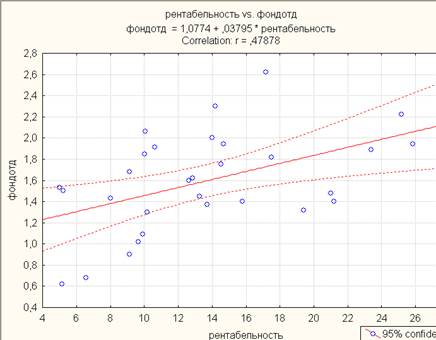
Самостоятельно выполните решения задач 1-3. Приложения 2.
Занятие 2. Кластерный анализ в системе Statistica.
В экономическом анализе группировка первичных данных является основным приемом решения задачи классификации, а поэтому и основой всей дальнейшей работы с собранной информацией. На основе группировок можно определить сходства и различия, в рассматриваемых явлениях. Иными словами процедуры кластерного анализа определяют сходство и различие между анализируемыми объектами.
Рассмотрим следующую задачу. Пусть исследуется совокупность n объектов, каждый из которых, характеризуется по k,замеренным на нем, признакам Х. Требуется разбить эту совокупность на однородные в некотором смысле группы (классы).
При этом практически отсутствует априорная информация о характере распределения измерений Х внутри классов. Полученные в результате разбиения группы обычно называются кластерами¦ (таксонам覦, образами), методы их нахождения - кластер- анализом (соответственно численной таксономией или распознаванием образов с самообучением).
Кластерный анализ позволяет разбить все исследуемые объекты на несколько классов, которые слабо взаимодействуют друг с другом, но внутри классов связи между объектами достаточно сильные. В основе кластерного анализа лежит понятие матрицы расстояний.
Каждый из объектов выборки Х оценивается значениями критериев
[xi1 xi2 ….xin ],
Эвклидово расстояние между объектами
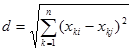
Основной алгоритм простейшего кластерного анализа
- Вычисляются все расстояния между объектами выборки
- Формируется матрица расстояний между всеми объектами
- Выбираются 2 объекта, расстояние между которыми наибольшее. Эти объекты определяют центры группировки.
- В зависимости от значений расстояния объекты относятся к тому или иному классу.
- В каждом классе вычисляются координаты среднего значения, относительно которого затем вычисляются расстояния до оставшихся не сгруппированных объектов.
- Алгоритм заканчивается полным разделением всех объектов.
Вместо формулы эвклидова расстояния используются и другие, например расстояние Маханолобиса 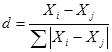
Вместо 2 классов используют иные классификации, например Колмогорова., группировка по нескольким классам.
Практическое задание.
Для вычислений используем таблицу приложения 1.
Загрузим ППП Статистика. и занесем переменные, определим заголовки переменных.
Войдем в меню Статистика \Многомерные исследовательские методы \ Анализ кластера.
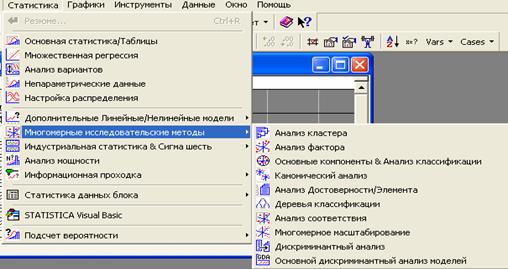
Выберем метод
Иерархическая (древовидная) кластеризация или метод К средних
Выберем иерархическую
Определим переменные, если участвуют все, то select all, если часть, то щелкаем по указанным при нажатой клавише shift, если пропускаем. то Ctrl
Укажите тип данных, панель Input («сырые» -Raw, или матрица расстояний)
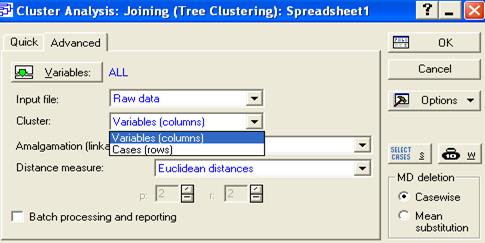
Укажем тип классификации: по признакам Cases (Rоws) или по объектам Variable(columns).
Укажем формулу для вычисления расстояния
Раздел MD deletion устанавливает режим работы с пропущенными данными.
Caserwise (пропустить), Mean substitution (заменить средними)
Установив данные щелкнем ОК
Следующее окно определяет протокол и параметры кластеризации
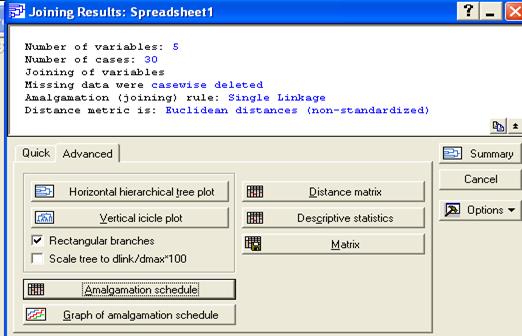
Окно состоит из двух частей: в верхней части, находится протокол исходных данных для анализа, в нижней протокол результатов.
Число переменных, число наблюдений, метод, тип матрицы расстояний, правило объединение кластеров.
В нижней части окна клавиши для протоколирования результатов.
Quick краткий, Advanced –полный.
Quick отображает только графики разделения на кластеры (вертикальный и горизонтальный).
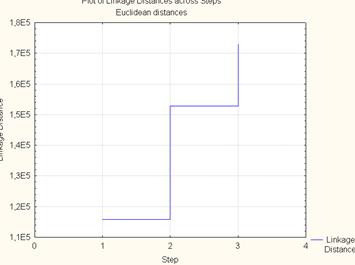
В «шапке» графика указывается каким методом производилось объединение и по какой формуле рассчитывалось расстояние.
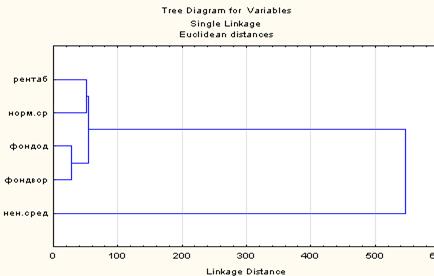
По оси ОХ откладываются расстояния при которых произошло слияния в кластер, а по оси ОУ названия объектов. На первом нулевом шаге все объекты рассматриваются как разные кластеры, на втором произошло объединение двух объектов (фондоворуженность и фондоотдача) на третьем объединились (рентабельность и нормированные обор. средства) и объекты первого кластера. На последнем шаге присоединились ненормированные средства.
Полный анализ Advanced.
Клавиша Amalgamation определяет методы объединения кластеров.
метод одиночной связи (single);
полной связи;
средней связи;
взвешенной связи;
метод Уорда.
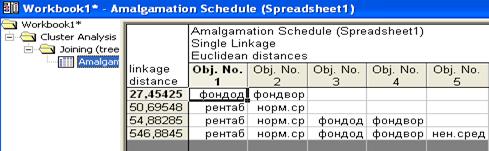
Протокол метода.
В левой части расстояния между кластерами при объединении
В правой части -названия объектов.
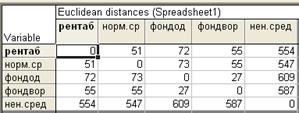
Клавиша Distance matrix –отображает матрицу расстояний между объектами
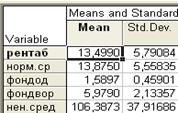
Клавиша Descriptiv statistic -отображает Описательную статистику классов.
Клавиша Graph Amalgamation –отображает ступенчатый график изменения расстояний при объединении кластеров.