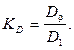2015-05-20
2015-05-20 381
381При расчетах по группированным данным учитывается частота появления каждого варианта (табл. 4). Среднее значение ‑ средняя арифметическая взвешенная:
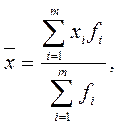
где 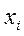 – варианты признака;
– варианты признака; 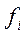 – частоты (частости).
– частоты (частости).
При расчете средней величины интервального ряда в качестве вариантов признака используются значения середины интервалов ‑ 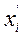 .
.
Таблица 4
Расчет среднего значения
|
|
|
| 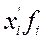
|
| 10.. 20 | |||
| .. | |||
| 50.. 60 | |||
| S | — |
Можно при расчете средней величины в качестве весов использовать частости распределения. Величина средней от этого не меняется.
Мода – значение признака, наиболее часто встречающееся в изучаемой совокупности, т.е. это одна из вариант признака, которая в ряду распределения имеет наибольшую частоту (частость). Для интервального ряда мода - это координата основания самого высокого столбика гистограммы, т.е. модального интервала. В качестве оценки моды используют не середину модального интервала, а скорректированное значение (рис.4).
 |
Рис. 4. Графическое определение моды
Значение моды по сгруппированным данным также можно определить по формуле
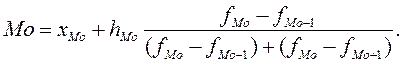
где xMo ‑ нижняя граница модального интервала; hMo – величина модального интервала; fMo, fMo– 1, fMo+ 1 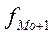 ‑ частоты (частости) соответственно модального, предмодального и послемодального интервалов.
‑ частоты (частости) соответственно модального, предмодального и послемодального интервалов.
Модальный интервал – это интервал, имеющий наибольшую частоту (частость).
Для определения медианного значения признака в интервальном ряду сначала находят номер медианы:
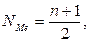
где n – объем совокупности.
После чего определяют медианный интервал, т.е. интервал, в котором находится порядковый номер медианы (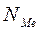 ). Для этого определяют, накопленная частота какого интервала первой превышает номер медианы.
). Для этого определяют, накопленная частота какого интервала первой превышает номер медианы.
Пример. Пусть есть следующий интервальный ряд:
| xi | fi | wi, % | Si (fi) | Si (wi), % |
| 20.. 30 | ||||
| 30.. 40 | ||||
| 40.. 50 | ||||
| 50.. 60 | ||||
| S | — | — |
NMe = 25,5 или NMe = 50%, т.е. медиане соответствует среднее из двух значений, стоящих под номерами 25 и 26 в упорядоченном вариационном ряду, или 50 % совокупности.
Найдем медианный интервал. Накопленная частота первого интервала S 1=10, S 1 < 25,5; значит, в этом интервале лежит 10 единиц упорядоченного вариационного ряда и нет медианного значения. Накопленная частота второго интервала S 2 =26, S 2 >25,5; значит, в первом и втором интервалах находится 26 единиц упорядоченного вариационного ряда, в том числе и медиана. Таким образом, мы определили медианный интервал – [30 - 40].
К такому же результату мы придем, если будем искать медианный интервал по накопленным частостям. Накопленная частость второго интервала S 2=52%, что больше NMe = 50 %, значит, именно в нем находится медиана.
Точное значение медианы для сгруппированных данных рассчитываем по формуле
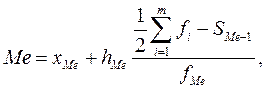
где xMe ‑ нижняя граница медианного интервала; h – величина медианного интервала; SMe –1 ‑ накопленная частота (частость) предмедианного интервала, fMe ‑ частота (частость) медианного интервала.
Медиану также можно найти графически, используя кумуляту распределения (рис. 5).
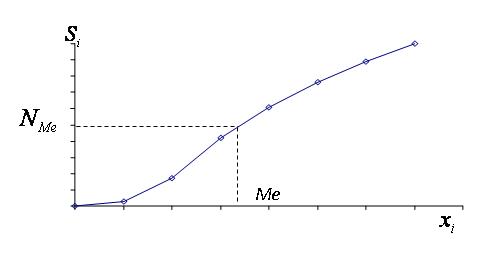
Рис. 5. Графическое определение медианы
Оценки моды и медианы, полученные по результатам группировки, могут отличаться от оценок показателей, полученных без группировки. Группировка данных - это обобщение, укрупнение, при котором могут теряться отдельные мелкие подробности, но зато становится видна «картина в целом».
К структурным характеристикам, кроме моды и медианы, относятся и другие порядковые статистики: квартили (Qi) – делящие ряд на 4 равные части, децили (Di) – делящие ряд на 10 частей и др.
Остановимся на расчете показателей децилей, нашедших широкое применение в анализе дифференциации различных социально-экономических явлений.
Общая схема расчета децилей следующая:
1) поскольку децили отсекают десятые части совокупности, по накопленным частостям определяем интервалы, куда попадают порядковые номера децилей: для первой децили ‑ интервал, где находится вариант, отсекающий 10 % совокупности с наименьшими значениями признака; для второй – 20 % и т. д.; для девятой децили ‑ интервал, содержащий вариант, отсекающий 90 % с наименьшими значениями, или, что то же самое, 10 % с наибольшими значениями признака;
2) рассчитываем величину децилей по формулам, аналогичным формуле для нахождения медианы. Например, первая и девятая децили находятся по формулам:
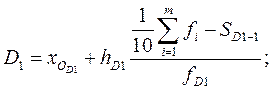
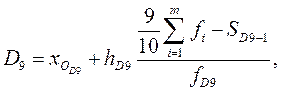
где 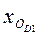 ,
, 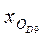 ‑ начала интервалов, где находятся первая и девятая децили;
‑ начала интервалов, где находятся первая и девятая децили; 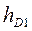 ,
, 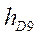 ‑ величины интервалов, где находятся первая и девятая децили;
‑ величины интервалов, где находятся первая и девятая децили; 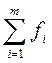 ‑ общая сумма частот (частостей);
‑ общая сумма частот (частостей); 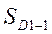 ,
, 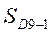 ‑ суммы накопленных частот (частостей) интервалов, предшествующих тем, в которых находятся первая и девятая децили;
‑ суммы накопленных частот (частостей) интервалов, предшествующих тем, в которых находятся первая и девятая децили; 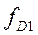 ,
, 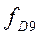 ‑ частоты (частости) интервалов, содержащих первую и девятую децили.
‑ частоты (частости) интервалов, содержащих первую и девятую децили.
Соотношение децильных доходов в социальной статистике получило название коэффициента децильной дифференциации доходов населения (KD):