 2015-05-13
2015-05-13 808
808Для таких приложений, как ведение операций на фондовой бирже или резервирование билетов, требуется знание текущей информации. Эти приложения не могут использовать вчерашнюю информацию, обеспечиваемую системами пакетной обработки транзакций, - им нужен немедленный доступ к текущим данным. С конца 1950-х годов лидирующие компании из нескольких областей индустрии начали вводить в использование системы баз данных с оперативными транзакциями; транзакции над оперативными базами данных обрабатывались в интерактивном режиме. Аппаратура для подключения к компьютеру интерактивных компьютерных терминалов прошла путь развития от телетайпов к простым алфавитно-цифровым дисплеям и, наконец, к сегодняшним интеллектуальным терминалам, основанным на технологии персональных компьютеров. Мониторы телеобработки представляли собой специализированное программное обеспечение для мультиплексирования тысяч терминалов со скромными серверными компьютерами того времени. Эти мониторы собирали сообщения-запросы, поступающие с терминалов, быстро назначали программы сервера для обработки каждого сообщения и затем направляли ответ на соответствующий терминал. Оперативная обработка транзакций дополняла возможности пакетной обработки транзакций, за которой оставались задачи фонового формирования отчетов.
Оперативные базы данных хранились на магнитных дисках или барабанах, которые обеспечивали доступ к любому элементу данных за доли секунды. Эти устройства и программное обеспечение управления базами данных давали возможность программам считывать несколько записей, изменять их и затем возвращать новые значения оперативному пользователю.
2.3.1. Иерархические СУБД.
Одной из наиболее важных сфер применения первых СУБД было планирование производства для компаний, занимающихся выпуском продукции. Например, если автомобильная компания хотела выпустить 10000 машин одной модели и 5000 машин другой модели, ей необходимо было знать, сколько деталей следует заказать у своих поставщиков. Чтобы ответить на этот вопрос, необходимо определить, из каких деталей состоят эти части и т.д. Например, машина состоит из двигателя, корпуса и ходовой части; двигатель состоит из клапанов, цилиндров, свеч и т.д. Работа со списками составных частей была как будто специально предназначена для компьютеров.
Список составных частей изделия по своей природе является иерархической структурой. Для хранения данных, имеющих такую структуру, была разработана иерархическая модель данных, которую иллюстрирует рис.5.3.
В этой модели каждая запись базы данных представляла конкретную деталь. Между записями существовали отношения предок/потомок, связывающие каждую часть с деталями, входящими в нее.
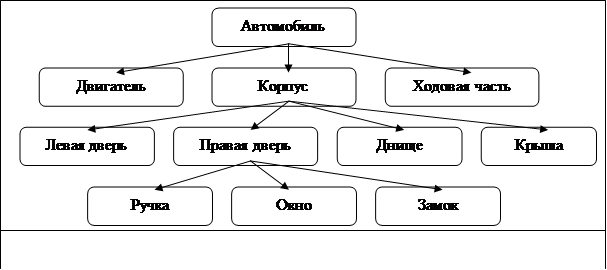 |
Рис.5.3. Иерархическая база данных, содержащая информацию о составных частях.
 |
Чтобы получить доступ к данным, содержащимся в базе данных, программа могла: - найти конкретную деталь (правую дверку) по ее номеру;
- перейти “вниз” к первому потомку (ручка двери);
- перейти “вверх” к предку (корпус);
- перейти “в сторону” к другому потомку (левая дверь).
Таким образом, для чтения данных из иерархической базы данных требовалось перемещаться по записям, за один раз переходя на одну запись вверх, вниз или в сторону.
2.3.2. Сетевые базы данных.
Если структура данных оказывалась сложнее, чем обычная иерархия, простота структуры иерархической базы данных становилась ее недостатком. Например, в базе данных для хранения заказов один заказ мог участвовать в трех различных отношениях предок/потомок, связывающих заказ с клиентом, разместившим его, со служащим, принявшим его, и с заказанным товаром, что иллюстрирует рис.5.4, такие структуры данных не соответствовали строгой иерархии IMS.
 |
Клиенты Служащие Товары
 |
Заказы
 |
Рис.5.4. Множественные отношения предок/потомок.
В связи с этим для таких приложений, как обработка заказов, была разработана новая сетевая модель данных. Она являлась улучшенной иерархической моделью, в которой одна запись могла участвовать в нескольких отношениях предок/потомок, как показано на рис.5.5. В сетевой модели такие отношения назывались множествами.

Клиенты Товары

Множество
 Записи
Записи
 |  |  |  |  | |||||||||
 | |||||||||||||
 | |||||||||||||
 Заказы
Заказы

Рис.5.5. Сетевая база данных, содержащая информацию о заказах.

Сетевые базы данных обладали рядом преимуществ:
- Гибкость. Множественные отношения предок/потомок позволяли сетевой базе данных хранить данные, структура которых была сложнее простой иерархии;
- Стандартизация. Появление стандарта CODASYL – популярность сетевой модели, а такие поставщики мини-компьютеров, как Digital Equipment Corporation и Data General, реализовали сетевые СУБД;
- Быстродействие. Вопреки своей большой сложности, сетевые базы данных достигали быстродействия, сравнимого с быстродействием иерархических баз данных. Множества были представлены указателями на физические записи данных, и в некоторых системах администратор мог задавать кластеризацию данных на основе множества отношений.
Конечно, у сетевых баз данных были недостатки. Как и иерархические базы данных, сетевые базы данных были очень жесткими. Наборы отношений и структур записей приходилось задавать наперед. Изменение структуры базы данных обычно означало перестройку всей базы данных.
Как иерархическая, так и сетевая база данных были инструментами программистов. Чтобы получить ответ на вопрос типа “Какой товар наиболее часто заказывает компания Acme Manufacturing?Э, программисту приходилось писать программу для навигации по базе данных. Реализация пользовательских запросов часто затягивалось на недели и месяцы, и к моменту появления программы информация, которую она предоставляла, часто оказывалась бесполезной.








