 2015-05-30
2015-05-30 2007
2007В случае парной регрессии рассматривается один объясняющий фактор: пусть 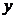 — изучаемый эконометрический показатель;
— изучаемый эконометрический показатель; 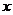 — объясняющий фактор.
— объясняющий фактор.
Примеры зависимостей:
1) — расходы фирмы за месяц, — объем выпущенной продукции за месяц;
2) — спрос на товар, — цена единицы товара.
Эконометрическая модель, приводящая к парной регрессии, имеет следующий вид
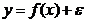 ,
,
где 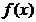 — неизвестная функциональная зависимость;
— неизвестная функциональная зависимость; 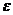 — случайное слагаемое, представляющее собой совокупное действие не включенных в модель факторов, погрешностей.
— случайное слагаемое, представляющее собой совокупное действие не включенных в модель факторов, погрешностей.
Основная задача эконометрического исследования — построение по выборке эмпирической модели — выборочной парной регрессии, являющейся оценкой функции :
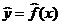 ,
,
где 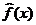 — эмпирическая (выборочная) регрессия, описывающая усредненную по зависимость между изучаемым показателем и объясняющим фактором, а так же последующая верификация модели (проверка статистической значимости построенной парной регрессии).
— эмпирическая (выборочная) регрессия, описывающая усредненную по зависимость между изучаемым показателем и объясняющим фактором, а так же последующая верификация модели (проверка статистической значимости построенной парной регрессии).
Экспериментальная основа построения эмпирической регрессии — двумерная выборка: 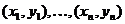 , где
, где 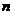 — объем выборки (объем массива экспериментальных данных).
— объем выборки (объем массива экспериментальных данных).
Выбор вида функциональной зависимости — основная задача спецификации модели. Основные методы выбора функциональной зависимости 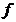 :
:
1) Геометрический;
2) Эмпирический;
3) Аналитический;
Геометрический метод выбора функциональной зависимости сводится к следующему. На координатной плоскости 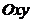 наносятся точки
наносятся точки 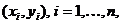 , соответствующие выборке:
, соответствующие выборке:
Полученное графическое изображение называется полем корреляции или диаграммой рассеяния.
Исходя из получившейся конфигурации точек выбирается вид параметрической функциональной зависимости. Обычно рассматриваются функциональные зависимости следующего вида
1) 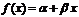 — линейная,
— линейная,
2) 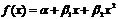 — параболическая,
— параболическая,
3) 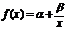 — гиперболическая,
— гиперболическая,
4) 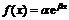 — показательная,
— показательная,
5) 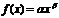 — степенная,
— степенная,
а так же некоторые другие. Функциональные зависимости 1), 2) и 3) линейны по своим параметрам.
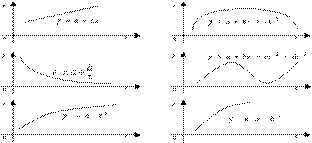 |
Рис 2.1. Основные типы кривых, используемые при количественной оценке связей
между двумя переменными
Для оценки неизвестных параметров чаще всего используется метод наименьших квадратов (МНК), который относится к эмпирическим методам
Аналитический метод сводится к попытке выяснения содержательного смысла зависимости изучаемого показателя от объясняющего фактора и последующего выбора на этой основе соответствующей функциональной зависимости. В примере 1, применяя аналитический метод, нетрудно получить следующую модель:
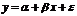 ,
,
где  — условно-постоянные расходы,
— условно-постоянные расходы, 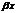 — условно-переменные расходы.
— условно-переменные расходы.
5. Случайный член, причины его существования.
Рассмотрим простейшую линейную модель парной регрессии:
y = a+bx+ε (2.1)
Величина y, рассматриваемая как зависимая переменная, состоит из двух составляющих: неслучайной составляющей, а+bх и случайного члена ε.
Случайная величина ε называется также возмущением. Она включает влияние не учтенных в модели факторов, случайных ошибок и особенностей измерения.
Причин существования случайной составляющей несколько.
1. Не включение объясняющих переменных. Соотношение между y и x является упрощением. В действительности существуют и другие факторы, влияющие на y, которые не учтены в (2.1). Влияние этих факторов приводит к тому, что наблюдаемые точки лежат вне прямой у = а+bх.
Часто встречаются факторы, которых следовало бы включить в регрессионное уравнение, но невозможно этого сделать в силу их количественной неизмеримости. Возможно, что существуют также и другие факторы, которые оказывают такое слабое влияние, что их в отдельности не целесообразно учитывать, а совокупное их влияние может быть уже существенным. Совокупность всех этих составляющих и обозначено в (2.1) через ε.
2. Агрегирование переменных. Рассматриваемая зависимость (2.1) – это попытка объединить вместе некоторое число микроэкономических соотношений. Так как отдельные соотношения, имеют разные параметры, попытка объединить их является аппроксимацией. Аппроксима́ция, или приближе́ние — научный метод, состоящий в замене одних объектов другими, в том или ином смысле близкими к исходным, но более простыми. Наблюдаемое расхождение приписывается наличию случайного члена ε.
3. Выборочный характер исходных данных. Поскольку исследователи чаще всего имеет дело с выборочными данными при установлении связи между у и х, то возможны ошибки и в силу неоднородности данных в исходной статистической совокупности. Для получения хорошего результата обычно исключают из совокупности наблюдения с аномальными значениями исследуемых признаков.
4. Неправильная функциональная спецификация. Функциональное соотношение между у и х математически может быть определено неправильно. Например, истинная зависимость может не являться линейной, а быть более сложной. Следует стремиться избегать возникновения этой проблемы, используя подходящую математическую формулу, но любая формула является лишь приближением истинной связи у и х и существующее расхождение вносит вклад в остаточный член.
5. Возможные ошибки измерения.
6. Условия нормальной линейной регрессии (Гаусса-Маркова)
Доказано, что для получения по МНК наилучших результатов (при этом оценки bi обладают свойствами состоятельности, несмещенности и эффективности) необходимо выполнение ряда предпосылок относительно случайного отклонения

