 2014-02-09
2014-02-09 2802
2802Анализ алгоритмов; время работы в лучшем, худшем случаях и в среднем
Рассматривая различные алгоритмы решения одной и той же задачи, полезно проанализировать, сколько вычислительных ресурсов они требуют (время работы, память), и выбрать наиболее эффективный. Конечно, надо договориться о том, какая модель вычислений используется. В данном учебном пособии в качестве модели по большей части используется обычная однопроцессорная машина с произвольным доступом (random-access machine, RAM), не предусматривающая параллельного выполнения операций.
Под временем работы (running time) алгоритма будем подразумевать число элементарных шагов, которые он выполняет. Положим, что одна строка псевдокода требует не более чем фиксированного числа операций (если только это не словесное описание каких-то сложных действий – типа «отсортировать все точки по x -координате»). Следует также различать вызов (call) процедуры (на который уходит фиксированное число операций) и её исполнение (execution), которое может быть долгим.
Сложность алгоритма – это величина, отражающая порядок величины требуемого ресурса (времени или дополнительной памяти) в зависимости от размерности задачи.
Таким образом, будем различать временную T (n) и пространственную V (n) сложности алгоритма. При рассмотрении оценок сложности, будем использовать только временную сложность. Пространственная сложность оценивается аналогично. Самый простой способ оценки – экспериментальный, то есть запрограммировать алгоритм и выполнить полученную программу на нескольких задачах, оценивая время выполнения программ. Однако, этот способ имеет ряд недостатков. Во-первых, экспериментальное программирование – это, возможно, дорогостоящий процесс. Во-вторых, необходимо учитывать, что на время выполнения программ влияют следующие факторы:
1) Временная сложность алгоритма программы;
2) Качество скомпилированного кода исполняемой программы;
3) Машинные инструкции, используемые для выполнения программы.
Наличие второго и третьего факторов не позволяют применять типовые единицы измерения временной сложности алгоритма (секунды, миллисекунды и т.п.), так как можно получить самые различные оценки для одного и того же алгоритма, если использовать разных программистов (которые программируют алгоритм каждый по-своему), разные компиляторы и разные вычислительные машины.
Часто, временная сложность алгоритма зависит от количества входных данных. Обычно говорят, что временная сложность алгоритма имеет порядок T (n) от входных данных размера n. Точно определить величину T (n) на практике представляется довольно трудно. Поэтому прибегают к асимптотическим отношениям с использованием
O -символики.
Существует метод, позволяющий теоретически оценить время выполнения алгоритма, который будет рассмотрен далее.

Листинг 1.3 – Псевдокод алгоритма сортировки вставками с оценками времени выполнения
Для вычисления суммарного времени выполнения процедуры Insertion-Sort отметим около каждой строки её стоимость (число операций) и число раз, которое эта строка исполняется. Для каждого j от 2 до п (здесь п = length [ A ]– размер массива) требуется подсчитать, сколько раз будет исполнена строка 5, обозначим это число через t j. Строки внутри цикла выполняются на один раз меньше, чем проверка, поскольку последняя проверка выводит из цикла. Строка стоимостью c, повторённая т раз, даёт вклад c× m в общее число операций (однако, это выражение нельзя использовать для оценки количества использованной памяти). Сложив вклады всех строк, получим
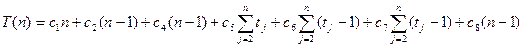
Время работы процедуры зависит не только от п но и от того, какой именно массив размера п подан ей на вход. Для процедуры Insertion-Sort наиболее благоприятен случай, когда массив уже отсортирован. Тогда цикл в строке 5 завершается после первой же проверки (поскольку A [ i ] ≤ key при i = j – 1), так что все tj равны 1, и общее время есть
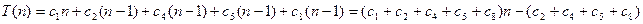
Таким образом, в наиболее благоприятном случае время T (n), необходимое для сортировки массива размера п, является линейной функцией (linear function) от n, т.е. имеет вид Т (п)= a × n + b для некоторых констант a и b. Эти константы определяются выбранными значениями с1,..., с8.
Если же массив расположен в обратном (убывающем) порядке, время работы
процедуры будет максимальным: каждый элемент A [ j ]придётся сравнить со всеми элементами А [1],..., A [ j – 1]. При этом tj = j. Поскольку
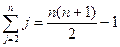
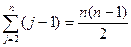
получаем, что в худшем случае время работы процедуры равно
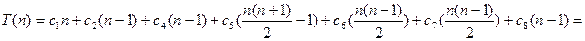
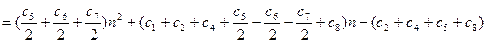
В данном случае T (n) – квадратичная (quadratic function), т.е. имеет вид Т (п) = a × n2 + b × n + с. Константы a, b и с здесь также определяются значениями с 1,..., с 8.
Обычно говорят, что временная сложность алгоритма имеет порядок T (n) от входных данных размера n. Точно определить величину T (n) на практике представляется довольно трудно. Поэтому прибегают к асимптотическим отношениям с использованием O -символики.
Например, если число тактов (действий), необходимое для работы алгоритма, выражается как 16× n2 + 12× n× log n + 2× n + 3, то это алгоритм, для которого T (n) имеет порядок O (n 2). При формировании асимптотической O -оценки из всех слагаемых исходного выражения оставляется одно, вносящее наибольший вклад при больших n (остальными слагаемыми можно пренебречь) и игнорируется коэффициент перед ним (так как все асимптотические оценки даются с точностью до константы).
Когда используют обозначение O (), имеют в виду не точное время исполнения, а только его предел сверху, причем с точностью до постоянного множителя. Когда говорят, например, что алгоритму требуется время порядка O (n 2), имеют в виду, что время исполнения задачи растет не быстрее, чем квадрат количества элементов.
Таблица 1.2 – Сравнительный анализ скорости роста функций
 |  | 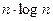 | 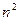 |
| 2 048 | 65 536 | ||
| 4 096 | 49 152 | 16 777 216 | |
| 65 536 | 1 048 565 | 4 294 967 296 | |
| 1 048 476 | 20 969 520 | 1 099 301 922 576 | |
| 16 775 616 | 402 614 784 | 281 421 292 179 456 |
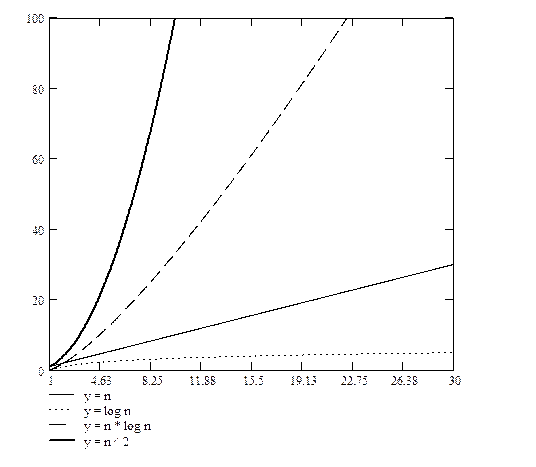
Рисунок 1.1 – Примеры различных функциональных зависимостей
Если считать, что числа, приведенные в таблице 1.2, соответствуют микросекундам, то для задачи с 1048476 элементами алгоритму со временем работы T (log n) потребуется 20 микросекунд, а алгоритму со временем работы T (n 2) – более 12 дней.
Если операция выполняется за фиксированное число шагов, не зависящее от количества данных, то принято писать O (1).
Следует обратить внимание, что основание логарифма в асимптотических оценках не пишется. Причина этого весьма проста. Пусть есть O (log2 n). Но log2 n = log3 n / log3 2, а log3 2, как и любую константу, символ О () не учитывает. Таким образом, O (log2 n) = O (log3 n). К любому основанию можно перейти аналогично, а, значит, и писать его не имеет смысла.
Практически время выполнения алгоритма зависит не только от количества входных данных, но и от их значений, например, время работы некоторых алгоритмов сортировки значительно сокращается, если первоначально данные частично упорядочены, тогда как другие методы оказываются нечувствительными к этому свойству. Чтобы учитывать этот факт, полностью сохраняя при этом возможность анализировать алгоритмы независимо от данных, различают:
- максимальную сложность Tmax (n), или сложность наиболее неблагоприятного случая, когда алгоритм работает дольше всего;
- среднюю сложность Tmid (n) – сложность алгоритма в среднем;
- минимальную сложность Tmin (n) – сложность в наиболее благоприятном случае, когда алгоритм справляется быстрее всего.
Теоретическая оценка временной сложности алгоритма осуществляется с использованием следующих базовых принципов:
1) Время выполнения операций присваивания, чтения, записи обычно имеют порядок O (1). Исключением являются операторы присваивания, в которых операнды представляют собой массивы или вызовы функций;
2) Время выполнения последовательности операций совпадает с наибольшим временем выполнения операции в данной последовательности (правило сумм: если T 1(n) имеет порядок O (f (n)), а T 2(n) – порядок O (g (n)), то T 1(n) + T 2(n) имеет порядок O (max (f (n), g (n)));
3) Время выполнения конструкции ветвления (if-then-else) состоит из времени вычисления логического выражения (обычно имеет порядок O (1)) и наибольшего из времени, необходимого для выполнения операций, исполняемых при истинном значении логического выражения и при ложном значении логического выражения;
4) Время выполнения цикла состоит из времени вычисления условия прекращения цикла (обычно имеет порядок O (1)) и произведения количества выполненных итераций цикла на наибольшее возможное время выполнения операций тела цикла.
5) Время выполнения операции вызова процедур определяется как время выполнения вызываемой процедуры;
6) При наличии в алгоритме операции безусловного перехода, необходимо учитывать изменения последовательности операций, осуществляемых с использованием этих операции безусловного перехода.
Итак, время работы в худшем случае и в лучшем случае могут сильно различаться. При анализе алгоритмов наиболее часто используется время работы в худшем случае (worst-case running time), которое определяется как максимальное время работы для входов данного размера. Почему? Вот несколько причин.
1) Зная время работы в худшем случае можно гарантировать, что выполнение алгоритма закончится за некоторое время при любом входе данного размера;
2) На практике «плохие» входы (для которых время работы близко к максимуму) встречаются наиболее часто. Например, для базы данных плохим запросом может быть поиск отсутствующего элемента (очень распространенная ситуация);
3) Время работы в среднем может быть довольно близко к времени работы в худшем случае. Пусть, например, сортируется массив из п случайных чисел с помощью процедуры Insertion-Sort.Сколько раз придётся выполнить цикл в строках 5-8 (листинг 1.3)? В среднем около половины элементов массива A [1 ..j – 1] больше A [ j ], так что tj в среднем можно считать равным j/ 2, и время Т (п)квадратично зависит от n.
В некоторых случаях требуется также среднее время работы (average-case running time, expected running time) алгоритма на входах данной длины. Конечно, эта величина зависит от выбранного распределения вероятностей, и на практике реальное распределение входов может отличаться от предполагаемого, которое обычно считают равномерным. Иногда можно добиться равномерности распределения, используя датчик случайных чисел.
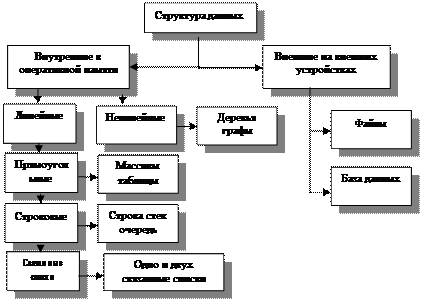
Рисунок 1.2 – Классификация структур данных
По характеру взаимосвязи структуры можно разделить на линейные - все элементы находятся на одном уровне, нелинейные - на нескольких уровнях. Для каждой разновидности типов структур данных характерны свои свойства и особенности в организации. В качестве общей характеристики выбрана запись. Запись - совокупность элементов о каком-то объекте. Они логически объединены в единую конструкцию, содержащую одно или несколько полей. Поле – минимальная единица данных, на которую можно ссылаться при обращении к данным. Одно из полей является ключевым и ключ содержит определенную величину, которую используют при упорядочении и поиске. Основной проблемой является выбор структуры данных и способа отображения в памяти зависящий от процедуры обработки данных.
Практически любую область математики ил других наук можно привлечь к построению определенного круга задач. И когда построена подходящая модель исходной задачи, то решение требуется искать в терминах этой модели. На этом этапе основная цель заключается в построении решения в форме алгоритма, состоящего из конечной последовательности инструкций, каждая из которых имеет четкий смысл и может быть выполнена конечными вычислительными затратами за конечное время. Инструкции могут выполняться в алгоритме любое число раз, при этом они сами определяют число повторений, однако программа, написанная на основе разработанного алгоритма, при любых начальных данных никогда не должна приводить к бесконечным циклическим вычислениям.
Хотя термины тип данных (или просто тип), структура данных и абстрактный тип данных похожи, они имеют различный смысл. В языках программирования низкого уровня (например, ассемблер) тип данных переменной обозначает множество значений, которые может принимать эта переменная (в языках высокого уровня любой встроенный в язык тип данных на самом деле ничем не отличается от создаваемых пользователем типов – классов). Например, переменная булевого (логического) типа может принимать только два значения: значение true (истина) и значение false (ложь). Набор базовых типов данных отличается в различных языках: в языке Pascal это типы целых (integer) и действительных (real) чисел, булев (boolean) тип и символьный (char) тип. Любой пользовательский тип данных может строиться на основе базовых типов.
Абстрактный тип данных – это математическая модель плюс различные операторы, определенные в рамках этой модели. Алгоритм может быть разработан в терминах АТД, но для реализации алгоритма в конкретном языке программирования необходимо найти способ представления АТД в терминах типов данных и операторов, поддерживаемых данным языком программирования. Для представления АТД используются структуры данных, которые представляют собой набор переменных, возможно, различных типов данных, объединенных определенным образом.
Базовым строительным блоком структуры данных является ячейка, которая предназначена для хранения значения определенного базового или составного типа данных. Структуры данных создаются путем задания имен совокупностям (агрегатам) ячеек и (необязательно) интерпретации значения некоторых ячеек как представителей (т.е. указателей) других ячеек.
В качестве простейшего механизма агрегирования ячеек в Pascal и большинстве других языков программирования можно применять (одномерный) массив, т.е. последовательность ячеек определенного типа. Массив также можно рассматривать как отображение множества индексов (таких как целые числа 1, 2,..., п)в множество ячеек. Ссылка на ячейку обычно состоит из имени массива и значения из множества индексов данного массива. В Pascal множество индексов может быть нечислового типа, например (север, восток, юг, запад), или интервального типа (как 1..10). Значения всех ячеек массива должны иметь одинаковый тип данных. Объявление
имя: аrrау [ТипИндекса] оf ТипЯчеек;
задает имя для последовательности ячеек, тип для элементов множества индексов и тип содержимого ячеек.
Многие языки программирования позволяют использовать в качестве индексов только множества последовательных целых чисел. Например, чтобы в языке Fortran в качестве индексов массива можно было использовать буквы, надо все равно использовать целые индексы, заменяя "А" на 1, "В" на 2, и т.д.
Другим общим механизмом агрегирования ячеек в языках программирования является структура записи. Запись (record) можно рассматривать как ячейку, состоящую из нескольких других ячеек (называемых полями), значения в которых могут быть разных типов. Записи часто группируются в массивы; тип данных определяется совокупностью типов полей записи. Например, в Pascal объявление

