 2015-04-08
2015-04-08 1293
12932 Можно указать два варианта рассмотрения взаимосвязей между двумя переменными 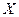 и
и 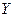 . В первом случае обе переменные считаются равноценными в том смысле, что они не подразделяются на первичную и вторичную (независимую и зависимую) переменные. Основным в этом случае является вопрос о наличии и силе взаимосвязи между этими переменными. Например, между ценой и объемом спроса на него, между урожаем картофеля и урожаем зерна, между интенсивностью движения транспорта и числом аварий. При исследовании силы линейной зависимости между такими переменными обращаются к корреляционному анализу, основной мерой которого является коэффициент корреляции. Вполне вероятно, что связь в этом случае вообще не носит направленного характера. Например, урожайность картофеля и зерновых обычно изменяются в одном и том же направлении, однако очевидно, что ни одна из этих переменных не является определяющей.
. В первом случае обе переменные считаются равноценными в том смысле, что они не подразделяются на первичную и вторичную (независимую и зависимую) переменные. Основным в этом случае является вопрос о наличии и силе взаимосвязи между этими переменными. Например, между ценой и объемом спроса на него, между урожаем картофеля и урожаем зерна, между интенсивностью движения транспорта и числом аварий. При исследовании силы линейной зависимости между такими переменными обращаются к корреляционному анализу, основной мерой которого является коэффициент корреляции. Вполне вероятно, что связь в этом случае вообще не носит направленного характера. Например, урожайность картофеля и зерновых обычно изменяются в одном и том же направлении, однако очевидно, что ни одна из этих переменных не является определяющей.
3 Другой вариант рассмотрения взаимосвязей выделяет одну из величин как независимую (объясняющую), а другую как зависимую (объясняемую). В этом случае изменение первой из них может служить причиной для изменения другой. Например, рост дохода ведет к увеличению потребления; рост цены — к снижению спроса; снижение процентной ставки увеличивает инвестиции; увеличение обменного курса валюты сокращает объем чистого экспорта и т.д. Однако такая зависимость не является однозначной в том, смысле, что каждому конкретному значению объясняющей переменной (набору объясняющих переменных) может соответствовать не одно, а множество значений из некоторой области. Другими словами, каждому конкретному значению объясняющей переменной (набору объясняющих переменных) соответствует некоторое вероятностное распределение зависимой переменной (рассматриваем как СВ). Поэтому анализируют, как объясняющая переменная(ые) влияет(ют) на зависимую переменную «в средним». Зависимость такого типа, выражаемая соотношением
4 М(Y|x)=f(x), (1.1)
5 называется функцией регрессии Y на X. При этом X называется независимой (объясняющей) переменной (регрессором), Y — зависимой (объясняемой) переменной. При рассмотрении зависимости двух СВ говорят о парной регрессии.
6 Зависимость нескольких переменных, выражаемая функцией
7 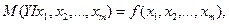 (1.2)
(1.2)
8 называют множественной peгрессией.
10 Термин "регрессия" (движение назад, возвращение в прежнее состояние) был введен Френсисом Галтоном в конце в XIX века при анализе зависимости между ростом родителей и ростом детей. Галтон заметил, то рост детей у очень высоких родителей в среднем меньше, чем средний рост родителей. У очень низких родителей, наоборот, средний рост выше. И в том, и в другом случае средний рост детей стремится (возвращается) к среднему росту людей в данном регионе. Отсюда и выбор термина, отражающего такую зависимость.
В настоящее время под регрессией понимается функциональная зависимость между объясняющими переменными и условными математическим ожиданием (средним значением) зависимой переменной, которая строится с целью предсказания (прогнозирования) этого среднего значения при фиксированных значениях первых.
Для отражения того факта, что реальные значения зависимой переменной не всегда совпадают с ее условными математическими ожиданиями и могут быть различными при одном и том же значении объясняющей переменной (наборе объясняющих переменных), фактическая зависимость должна быть дополнена некоторым слагаемым, которое, по существу, является СВ и указывает на стохастическую суть зависимости. Из этого следует, что связи между зависимой и объясняющей(ими) переменными выражаются соотношениями
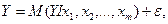
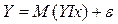 (1.3)
(1.3)
называемыми регрессионными моделями (уравнениями).
Обсуждение регрессионных моделей на следующих лекциях поможет глубже изучить данное понятие.
Возникает вопрос о причинах обязательного присутствия в регрессионных моделях случайного фактора (отклонения). Среди таких причин выделим наиболее существенные.
1. Не включение в модель всех объясняющих переменных. Любая регрессионная (в частности, эконометрическая) модель является упрощением реальной ситуации. Последняя всегда представляет собой сложнейшее переплетение различных факторов из которых в модели не учитываются, что порождает отклонение реальных значений зависимой переменной от ее модельных значений. Например, спрос (Q) за товар определяется его ценой (Р), ценой (Рз) на товары заменитель, ценой (Рд) на дополняющие товары, доходов (I) потребителей их количеством (N), вкусами (N), ожиданиями {W) и т. д. Безусловно перечислить все объясняющие переменные здесь практически невозможно. Например мы не учли такие факторы, как традиций национальные или религиозные оособенности, географическое положение региона, погода и многие другие, влияние которых приведет к некоторым отклонениям реальных наблюдений от модельных, которые можно выразить через случайный член 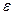 :Q=f(P,Рз,Pд,I,N,T,W, ). Проблема еще и в том что никогда заранее не известно, какие факторы при создавшихся условиях действительно являются определяющими, а какими можно пренебречь. Здесь уместно отметить, что в ряде случаев учесть непосредственно какой-то фактор нельзя в силу невозможности получения по нему статистических данных.. Например, величина сбережений домохозяйств может определяться не только доходами их членов, но и, например, здоровьем последних, информация о котором в цивилизованных странах составляет врачебную тайну и не раскрывается. Кроме того, ряд факторов носит принципиально случайный характер (например, погода), что добавляет неоднозначности при рассмотрении некоторых моделей (например, модель, прогнозирующая объем урожая).
:Q=f(P,Рз,Pд,I,N,T,W, ). Проблема еще и в том что никогда заранее не известно, какие факторы при создавшихся условиях действительно являются определяющими, а какими можно пренебречь. Здесь уместно отметить, что в ряде случаев учесть непосредственно какой-то фактор нельзя в силу невозможности получения по нему статистических данных.. Например, величина сбережений домохозяйств может определяться не только доходами их членов, но и, например, здоровьем последних, информация о котором в цивилизованных странах составляет врачебную тайну и не раскрывается. Кроме того, ряд факторов носит принципиально случайный характер (например, погода), что добавляет неоднозначности при рассмотрении некоторых моделей (например, модель, прогнозирующая объем урожая).
2. Неправильный выбор функциональной формы модели. Из-за слабой изученности исследуемого процесса либо из-за его переменчивости может быть неверно подобрана функция, его моделирующая. Это, безусловно, скажется на отклонении моделиот реальности, что отразится на велечине случайного члена. Например, производственная функция (У) одного фактора (Х) может моделироваться функцией У == а + bХ, хотя должна была исследоваться другая модель: У = аХb (0 <b < 1), учитывающая закон убывающей эффективности. Кроме того, неверным может быть подбор объясняющих переменных.
3. Агрегирование переменных. Во многих моделях рассматриваются зависимости между факторами, которые сами представляют сложную комбинацию других, более простых переменных. Например, при рассмотрении в качестве зависимой переменной совокупного спроса проводится анализ зависимости, в которой объясняемая переменная является сложной композицией индивидуальных спросов, оказывающих на нее определенное влияние помимо факторов, учитываемых в модели. Это может оказаться причиной отклонения реальных значений от модельных.
4. Ошибки измерений. Какой бы качественной ни была модель, ошибки измерений переменных отразятся на несоответствии модельных значений эмпирическим данным, что также отразиться на величине случайногочлена.
5.Ограниченность статистических данных. Зачастую строятся модели, выражаемые непрерывными функциями. Но для этого используется, набор данных, имеющих дискретную структуру. Это несоответствие находит свое выражение в случайном отклонении.
6. Непредсказуемость человеческого фактора. Эта причина может «испортить» самую качественную модель. Действительно, при правильном выборе формы модели, скрупулезном подборе объясняющих переменных все равно невозможно спрогнозировать поведение каждого индивидуума.
Таким образом, случайный член является отражением влияния всех описанных выше причин ине только их. Этот список может быть дополнен.
Решение задачи построения качественного уравнения регрессии, соответствующего его эмпирическим данным и целям исследования, является достаточно сложным и многоступенчатым процессом. Его можно разбить на три этапа:
1) выбор формулы уравнения регрессии;
2) определение параметров выбранного уравнения;
3) анализ качества уравнения и поверка адекватности уравнения эмпирическим данным, совершенствование уравнения.
Выбор формулы связи переменных называется спецификацией уравнения регрессии. В случае парной регрессии выбор формулой обычно осуществляется по графическому изображению реальных статистических данных в виде точек в декартовой системе координат, которое называется корреляционным полем (диаграммой рассеивания) (рис. 1.1).
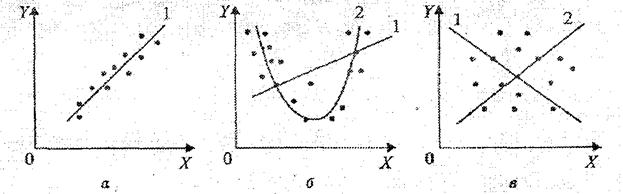
Рис. 1.1
На рис. 1.1 представлены три ситуации. На графике 4.1, а взаимосвязь между Х и Y близка к линейной, и прямая 1 достаточно хорошо соответствует эмпирическим точкам. Поэтому в данном случае в качестве зависимости между X и Y целесообразно выбрать линейную функцию 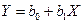 .
.
На графике 1.1, б реальная взаимосвязь между X и У, скорее всего, описывается квадратичной функцией 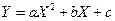 (линия 2). И какую бы мы ни провели прямую (например, линия 1) отклонения точек наблюдений от нее будут существенными и неслучайными.
(линия 2). И какую бы мы ни провели прямую (например, линия 1) отклонения точек наблюдений от нее будут существенными и неслучайными.
На графике 1.1, в явная взаимосвязь между X и У отсутствует. Какую бы мы ни выбрали форму связи, результаты ее спецификации и параметризации (определение коэффициентов уравнения) будут неудачными. В частности, прямые 1 и 2, проведенные через центр "облака" наблюдений и имеющие противоположный наклон, одинаково плохи для того, чтобы делать выводы об ожидаемых значениях переменной У по значениям переменной X.
В случае множественной peгpeccии определение подходящего вида зависимости является более сложной задачей.
Вопросы определения параметров уравнения {параметризации) и проверки качества (верификации) уравнения регрессии будут обсуждены в следующих лекциях.

