 2015-04-01
2015-04-01 9416
9416Семантика (от греч. semantikos – обозначающий) – раздел языкознания и логики, в котором исследуются проблемы, связанные со смыслом, значением и интерпретацией знаков и знаковых выражений. В широком смысле семантика, наряду с синтактикой и прагматикой, является частью семиотики – комплекса философских и научных теорий, предметом которых являются свойства знаковых систем: естественных языков, искусственных языков науки (в том числе частично формализованных языков естественнонаучных теорий, логических и математических исчислений), различных систем знаковой коммуникации в человеческом обществе, животном мире и в технических информационных системах. При определенных допущениях знаковыми системами можно считать средства изобразительного искусства, музыки, архитектуры и говорить о семантике языка искусства.
Ядро семантических исследований составляют разработки семантики ЕЯ и логической семантики. Семантика ЕЯ изучается конкретными методами в лингвистике, в частности математической.
Ключевые проблемы семантики получили точное выражение в связи с построением и изучением формализованных языков, формальных систем (исчислений). Содержательная интерпретация таких языков – предмет логической семантики, раздела логики, в котором изучается смысл и значение понятий и суждений как выражений определенной логической системы и который ориентирован на содержательное обоснование логических правил и процедур, свойств непротиворечивости и полноты такой системы. К задачам логической семантики относится экспликация понятий «смысл», «значение», «истинность», «ложность», «следование» и т.п.
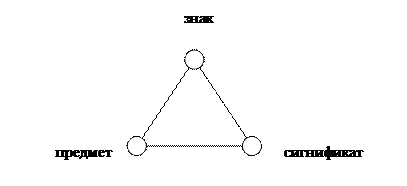 |
Рис. Треугольник Фреге
Часто логическую семантику разделяют на теорию референции (обозначения) и теорию смысла. Первая использует такие категории, как «имя», «определимость», «выполнимость» и др., вторая исследует отношение формализмов к тому, что они выражают. Ее основными понятиями являются понятия смысла, синонимии, аналитической и логической истинности. На уровне понятий и суждений важнейшими в логической семантике являются вопросы, связанные с различением между объемом и содержанием понятия, между истинностным значением и смыслом суждения. Это различение выражено в основном семантическом треугольнике – трехчленном отношении между предметом (событием), содержанием (смыслом) и именем.
Согласно концепции Фердинанда де Соссюра, языковой знак представляет собой двустороннюю сущность, характеризуемую означающим («именем») и означаемым («семантикой»). В логической литературе семантику знака принято рассматривать на двух уровнях – денотативном (референционном) и сигнификативном. Денотатом знака называется класс обозначаемых им фактов, а сигнификатом – общие признаки всех фактов этого класса. Часто сигнификат разделяют на категории понятия, которое отражает все существенные признаки и свойства предмета, и значение, под которым понимается специфически языковое отражение предмета, его краткая характеристика.
На уровне формальной системы центральным семантическим понятием является интерпретация, т.е. отображение формализмов системы на некоторую область реальных или идеальных объектов, в некоторую содержательную теорию или ее часть.
В семантике исследуются непротиворечивость и полнота таких систем при помощи различных семантических моделей; основную роль при этом играют определения понятия истинности. В настоящее время построено множество различных типов семантических моделей.
Для описания семантики используется ряд формальных и не формальных методов. В первую очередь (с точки зрения истории), необходимо выделить формальные методы математики и семиотики, получившие развитие из логики Аристотеля. Это методы дедуктивных рассуждений, основанные на понятии точного вывода из заданных посылок (аксиом), используя формальный язык метаматематики. Данные методы давно используются для построения схем доказательств в математической логике, однако при описании семантики естественного языка они показали свою весьма слабую мощность. Естественный язык отображает такие мыслительные процессы, как выделение существенного в знании, способность к рассуждениям, рефлексию, выдвижение цели и выбор средств ее достижения, познавательную активность, адаптацию к ситуации, формирование обобщений и обучение на примерах, синтез познавательных процедур. Данные процессы находятся в прямой аналогии (с точностью до изоморфизма) с методами проектирования, в частности с начальным этапом проектирования – методами синтеза новых технических решений. Поэтому попытки формализовать данные понятия в проектировании можно рассматривать как испытательный прототип для более широкого класса явлений. Формализация данных процессов пока находится в стадии становления. При этом необходимо выделить работы по моделированию семантики как процессу формализации синтеза познавательных процедур. Сюда можно отнести работы по формализации абдуктивного вывода, немонотонных рассуждений, контекстно-зависимого вывода и квазиаксиоматических теорий.
Рассмотрим основные результаты в области представления квазиаксиоматических теорий. Квазиаксиоматическая теория есть тройка _ = (S,S^,R), где: S - множество принципов (лишь частично формализующих изучаемую предметную область); S^- открытое множество гипотез и фактов, R- есть множество правил вывода, которое содержит как правила достоверного вывода, так и некоторые эвристические правила, т.е. R=R1_R2, где R1 - дедуктивные, а R2 - правдоподобные правила вывода. Аксиомы данной теории делятся на следующие группы: процедурные, аксиомы связи предикатов (характеризующих класс задач), аксиомы структур данных. Данная методология может применяться для построения формализаций, порождающих правдоподобный вывод. Таким образом, возможно ее применение как схемы формализации для построения семантической модели процесса синтеза новых технических и информационных систем.
Этап семантического анализа в лингвистике (и других гуманитарных дисциплинах) недостаточно обеспечен теорией и практикой. Одной из задач лексической семантики является снятие лексической и структурной неоднозначности. Для этого используется аппарат селективных ограничений, который привязан к рамкам предложений, т.е. вписывается в синтаксическую модель. Альтернативные подходы развивались на ранних этапах развития ЕЯ-систем. Это тезаурусный подход (М. Мастерман) и корреляционный анализ (С. Чеккато).
В системах машинного перевода CETA (Франция, Гренобльский университет) и LRC представлен логико-семантический подход (который в дальнейшем получил большое развитие), представляющий структуру предложений в терминах логических отношений (предикаты, аргументы, атрибуты).
Однако прямой переход от поверхностных синтаксических деревьев к соответствующим представлениям смысла слишком сложен вследствие большой синонимичности языка. По этому в последнее время в качестве некоторого переходного элемента между синтаксисом и семантикой стали использовать глубинные синтаксические структуры (ГСС). Для описания ГСС используют т.н. D-грамматики, работающие с деревьями зависимостей.
Распространённым типом реализации семантического этапа является построение падежных грамматик. В основе грамматики лежит понятие глубинного или семантического падежа. Падежная рамка глагола является расширением понятия валентность: это набор смысловых отношений, которые могут (обязательно или факультативно) сопровождать глагол и его вариации в тексте (например: агент, адресат, цель и др.). В пределах одного языка один и тот же глубинный падеж реализуется разными поверхностными предложно-падежными формами.
Результатом этапа семантического анализа является семантическая структура, соответствующая предложению ЕЯ.
Трансформационные грамматики.
Н.Хомский первый в явном виде сформулировал задачу превращения лингвистики в точную науку путем построения формализуемых моделей языка, которые могут быть реализованы на компьютере, назвав это генеративной парадигмой. Его теория трансформационных грамматик (ТГ) в различных вариациях является одной из наиболее популярных.
Целью лингвистического исследования Хомский ставит теорию грамматической компетенции носителя языка. Грамматические структуры описываются формально, при этом целью является развитие синтаксических формализмов, обеспечивающих точное описание множества предложений языка. Теория вводит три языковых уровня: семантический, синтаксический и фонологический. При этом основное внимание обращается на синтаксический уровень, который описывается автономно. По мнению Хомского, его теория описывает универсальную часть структуры языкового аппарата человека, не зависящую от конкретного языка.
В дополнение к КС-правилам в трансформационной грамматике вводятся контекстно-зависимые правила трансформаций, позволяющие переходить от поверхностной (S-) синтаксической структуры к глубинной (D-) структуре, которая одинакова для всех способов выражения данного смысла и отражает языковые универсалии. Практика построения трансформационных правил показала, что у многих из них совпадают контекстные условия, ограничивающие трансформации глубинной структуры.
Одной из первых компьютерных реализаций ТГ является система MITRE transformational parser. К семидесятым годам относится и система PHLIQA1. В числе поздних реализаций ТГ-теории в упоминается система PARSIFAL.
GB положена в основу двух исследовательских систем, PAULA и GIBBERISH. Первая создана в университете Пассау (Германия), реализована на языке Modula-2 и позволяет обрабатывать неграмматичности. Вторая предназначена для обучения студентов применению базовых понятий GB и представляет собой расширяемую систему, написанную на Prolog.
Наибольшее распространение среди поздних систем получила PAPPI. Для моделирования основных механизмов теории GB предлагается применение языка программирования, основанного на структурированных типах, которые обладают наследованием и набором ограничений и представляют составляющие с типизированными термами. Ограничения, в частности, используются для выражения удаленных зависимостей и падежных фильтров, наследование типов моделирует субкатегоризацию.
Для представления X-составляющих вводятся три конструктора типов:
а) x0 – для лексических единиц;
б) x1 – для незавершенных составляющих;
в) xp – для составляющих с максимальной проекцией.
Идее Хомского о формализации лингвистических теорий следуют и работы Ю. С. Мартемьянова, в которых также используются трансформации между глубинной и поверхностной структурами, однако эта теория сочетает в себе черты ТГ с функциональным подходом, поскольку в рамках его концепции требовалась семантическая мотивированность трансформаций и получающихся глубинно-синтаксических отношений. Своеобразие этих представлений заключается во введении еще в начале 70-х годов юнктивно-энфазных отношений и языка структур непосредственных составляющих с расчлененной категоризацией, что во многом предвосхитило описания с помощью X-теории. Так, правила порождения глубинного представления имеют следующий вид:
Таблица 1.
| nV(1)® N1+V1 | Группа по первой валентности развертывается на имя (подлежащее) и глагол (сказуемое). |
| nVM, M<n ® nV(M+1) | Глагол с валентностью M, не достигшей общего числа валентностей n, может быть по своему содержанию глагольной группой очередной валентности. |
Большее внимание к функциональному представлению привело к использованию актуального членения в терминах ТГ, семантическая мотивированность описывалась с помощью аппарата, основанного на логической семантике. Предложенные метасредства описания языка были реализованы в проектах ФЛОС (Формализованное Лингвистическое Описание Синтеза) и ФЛОРА (Формализованное Лингвистическое Описание Русского Анализа), в которых были построены грамматики русского, английского, немецкого и французского языков.
Достоинства модели: развитые средства описания синтаксиса; многоязычность.
Недостатки модели: ориентация на синтез; ГСС жестко ограничивает свободу выбора вариантов выражения определенного семантического значения – прямое следствие ориентации на КС-грамматику; слабость модели на семантическом уровне; порождающий характер.
Генеративный лексикон.
Попытки описания семантики в рамках генеративной парадигмы на основе декомпозиции значения слов в набор примитивов не привели к созданию формальной модели. В 90-е годы появилась генеративная модель – Generative Lexicon (GL) – определяющая значение в терминах структур типизированных свойств. Вычислительным формализмом для этой модели служит TDL. Целью данной модели была разработка аппарата представления значения слов с учетом полисемии. В рамках этой теории значения представлены в недоопределенном виде (underspecified) с помощью четверки компонентов a = <A, E, Q, I>, соответственно Argument, Event, Qualia и Inheritance структур.
Аргументная структура соответствует актантам предиката или значениям слова (используются возможности параллельных аргументных структур и умолчательных аргументов). Qualia соответствует представлению знания, ассоциированного с данной структурой. В нее могут входить такие атрибуты, как CONST (из чего состоит a), FORMAL (определение a в терминах других структур), TELIC (цель a), AGENTIVE (источник появления a). Скращение lcp означает lexical-conceptual paradigm, т.е. набор понятий, на которые ссылаются слова такого типа, подобно морфологической парадигме.
Структура наследования представляет собой сеть ортогональных иерархий, описывающих виды объектов и действий (например, phys_obj и information) и задающих систему измерений семантического описания. Пересечение ортогональных иерархий, определяемое для конкретных слов (называемых dot-objects), задает точку в этом пространстве, обладающую несколькими модусами интерпретации. Событийная структура хранит информацию о видах пропозиций согласно выбранной аргументной структуре с заполненными упомянутыми аргументами и восстановленными умолчательными.
Достоинства модели: явные средства учета многозначности; наличие иерархии понятий.
Недостатки модели: ориентация только на синтез;не учитываются многие ЕЯ-феномены; неявное использование только английского языка.
Модель «Смысл↔Текст».
Отечественная теория, разрабатывалась начиная с середины 60-х годов. Специфической чертой этой системы является большая (по сравнению с ТГ) разработанность семантического компонента. Описание языка в этой модели устанавливает соответствие между смыслом и всеми текстами данного языка, выражающими этот смысл, т.е. язык рассматривается как система кодов, которая соответствует системе смыслов. Вводимый набор уровней представления имеет большее число ступеней по сравнению с ТГ: семантический, синтаксический, морфологический, фонологический и фонетический. Основу семантического уровня составляет семантическое представление (СемП); синтаксический же уровень содержит глубинно-синтаксическую структуру (ГСС) и поверхностно-семантическую (или просто синтаксическую) структуру (ПСС), описываемые в терминах дерева зависимостей. СемП содержит сеть, состоящую из минимальных единиц смысла, связанных между собой определенным набором отношений и некоторой коммуникативной информацией (например, она включает деление на тему-рему). Оригинальным является также аппарат лексических функций – метод описания лексических коррелятов слова, т.е. других слов, регулярно используемых с данным. Лексические функции, описывают связь между семантическим представлением и явлениями грамматики.
Помимо большего внимания к механизмам семантического представления теория «Смысл↔Текст» отличается от ТГ вниманием к коммуникативной организации высказывания: такие категории, как тема и рема, эмфаза и пр. могут быть представлены как на уровне семантического представления, так и в ГСС и ПСС фразы, на более низких уровнях они уже реализованы порядком слов, выбором лексики, специальными конструкциями (специфическая реализация зависит от языка).
Достоинства модели: полнота представления (все уровни – от семантического до фонетического); двунаправленность (анализ и синтез); развитость представления семантического уровня; оригинальный аппарат лингвистических функций; многоязычность; не порождающий характер.
Недостатки модели: высокая сложность построения семантического словаря; приоритетность синтеза (мощные средства перефразирования); высокоуровневость: отсутствие явных вычислительных формализмов.
Общие идеи HPSG.
HPSG (Head-Driven Phrase-Structure Grammar) как теория языка в значительной степени является хорошо сбалансированным объединением идей сразу из нескольких грамматических теорий, таких как LFG и GPSG. Однако, разделяя с этими теориями подход к моделированию феноменов ЕЯ, HPSG как формализм основана на другой вычислительной модели, а именно на разрешении системы ограничений структур типизированных признаков (TFS). Эти системы, в отличие от GPSG, используются не для хранения информации о синтаксической структуре, а как набор частных ограничений на ее сформированность, разрешение которых приводит к большей определенности этой структуры. Что касается математического формализма, подход HPSG близок унификационным категориальным грамматикам. Многие исследователи отмечали интеграции описаний, разработанных в категориальных грамматиках, в HPSG и наоборот.
Благодаря представлению знака как набора атрибутов различных уровней, становится возможной интеграция всей лингвистически-релевантной информации от фонологической до прагматической с одновременным ее использованием, поскольку ограничения могут формулироваться, например, как «если данный фонологический компонент маркирован, то соответствующий прагматический компонент должен иметь значение атрибута фокуса».
При этом благодаря тому что теория HPSG основана на ограничениях, все представление о грамматике записано в виде этих ограничений, которые разрешаются параллельно. Параллельность обработки ограничений, принадлежащих различным уровням грамматической структуры, подтверждается, по словам разработчиков этой теории, и данными из психологии об одновременной обработке человеком всех уровней (от фонетического до прагматического) за период около 100-150 миллисекунд.
Основные принципы грамматической теории в HPSG состоят в следующем:
а) строгий лексикализм (структура слова и составляющих описываются разными принципами);
б) геометрическое предсказание (лингвистические данные иерархически организованы таким образом, чтобы предсказывать невозможность некоторых явлений);
в) локальность выбора валентности (в соответствии с теорией валентности в HPSG только synsemобъекты могут выступать в роли дополнений или спецификаторов. Это означает, что выбор категории, присваивание ролей, синтаксическое и семантическое согласование определяются на основании ограничений на локальность, записанных в valence selection features);
г) локальность определения удаленных зависимостей (вместо грамматических трансформаций используется передача некоторых свойств, определяемых вдоль пути от реального заполнителя к месту, где он должен быть);
д) наличие нескольких типов согласования (синтаксическое, анафорическое, прагматическое; геометрия согласований предсказывает, в частности, отсутствие согласования в падеже для анафоры);
е) лексическая кросс-классификация (лексическая информация задается в терминах множественного наследования, и многие свойства слов определяются из словарной информации на основе лексических правил);
ж) семантически ориентированная теория управления;
з) теория линеаризации (способы упорядочивания компонентов основаны на использовании традиционной модели структуры составляющих в качестве поддержки для структур зависимости, последние составляют основу синтаксической структуры. Это облегчает, в частности, использование разрывных составляющих. Операции, подобные образованию составляющих, представляются в TFS с помощью символа «&», означающего конкатенацию строк).
Достоинства модели: полнота представления (все уровни – от семантического до фонетического); наличие нескольких типов согласования.
Недостатки модели: основана на КС-грамматике; ориентация на синтез;
имеет в основе строй английского языка.
Функциональные грамматики.
К функциональным грамматикам относится целый ряд теорий, уделяющих большее внимание семантике и описывающих синтаксические категории с точки зрения их функций для выражения некоторого значения. В них структуры естественного языка рассматриваются лишь как средство реализации коммуникативных целей. Рассмотрим одну из типичных теорий, грамматику семантических падежей Филмора.
В соответствии с этой концепцией предикат управляет набором семантических падежей, определяющих роли участников ситуации. Состав подобных ролей участников сильно зависит от целей ее построения. Канонический список Филмора представлен на табл. 2.
Таблица 2 – канонические семантические падежи Ч. Филлмора
| Семантический падеж | Описание |
| Агент | непосредственный участник |
| Контрагент | участник ситуации, его действия не совпадают с Агентом |
| Объект | сущность, которую действие перемещает, изменяет, или сущность, положение или существование которой рассматривается |
| Результат | сущность, которая получилась в результате действия |
| Инструмент | стимул или физическая причина события |
| Источник | то, откуда что-либо перемещается |
| Цель | то, куда что-либо перемещается |
| Senser | сущность, которая получает, принимает или претерпевает результат действия |
К теории семантических падежей близка теория функциональной грамматики Саймона Дика. Эта теория, в дополнение к набору семантических падежей, вносит деление на Тему-Хвост и Топик-Фокус. Кроме того, вводится понятие иерархии семантических функций на основе того, что Действие не может осуществляться без Деятеля, следовательно, эта функция является более главной по сравнению с функцией Цель, которая важнее, чем Получатель. Эта иерархия используется для определения соответствующих функций при анализе либо для правильной расстановки падежных маркеров при синтезе.
Достоинства модели: риторические отношения позволяют отразить связи между предложениями; многоязычность; оригинальная система семантических ролей.
Недостатки модели: имеются зависимости модели от поверхностной структуры предложений; ориентация на описание коммуникативных ситуаций; неполный набор семантических падежей.
Системы семантических образцов. Одна из наиболее старых идей, используемых в семантически ориентированном анализе, – предположение возможности прямого отображения между предикатно-аргументной структурой и поверхностным языковым представлением. Это означает возможность определения смысла непосредственно из текста без обращения к дополнительному уровню синтаксических представлений.
Пионером этого подхода является Уилкс, который предложил теорию семантики предпочтений. В разных работах этого направления вводится различное число семантических примитивов (80-100), включающих 15-20 классов, обозначаемых звездочкой. Например, к числу примитивов класса *ANIMATE относятся примитивы THIS, MAN, FOLK, BEAST, *HUMAN; к примитивам класса *PLACE относятся THIS, POINT, SPREAD, PART. Примитивы образуют иерархию классов с множественным наследованием. На основании примитивов строятся семантические формулы, отражающие один из смыслов слова. Формулы могут быть взаимозависимы. В некоторых случаях это используется для разрешения метафорического и метонимического употребления слов, как, например, в предложении «чайник кипит», где имеется в виду кипение жидкости в чайнике. Анализ текста ведется путем объединения образцов (templates), графов, каждый из которых содержит три узла для агента, действия и объекта, являющихся семантическими формулами. Объединение графов должно удовлетворять принципу максимальной семантической плотности, т.е. из нескольких смыслов выбирается один с наиболее насыщенными семантическими предпочтениями в формулах. Операции над построенными графами предпочтений включают вывод на основе информации о мире, представленной в тезаурусе, что позволяет разрешать анафорическое местоимение «them» в предложении «The soldiers fired at the women and I saw several of them fall».
Одна из первых реализаций концепции Уилкса относится к концу 60-х. Богураев построил систему для описания семантических предпочтений с помощью ATN-формализма и применил ее для системы обработки запросов к базе данных. Система PREMO является одной из наиболее полных реализаций современных версий семантики предпочтений. В качестве словаря в ней использован LDOCE, словарные статьи которого дополнены сведениями о примитивах, прагматических знаниях и вероятности использования того или иного смысла данного слова. В процессе анализа «языковые объекты» (результаты частичного разрешения семантических образцов) хранятся в очереди вместе со своими приоритетами, которые вычисляются функцией метрики предпочтений, принимающей во внимание разрешенные семантические предпочтения, прагматическую связность и некоторые грамматические ожидания. Для новых слов используется также информация о вероятностях сочетания из словаря, зависящая от типа текста. Так, слово «measure» в научном тексте имеет другие возможности сочетания, чем, например, в тексте политическом или музыкальном.
Концепция семантически-ориентированного анализа основывается на приписывании лексическим единицам семантических типов и наборов ориентаций, т.е. множеств возможных концептов, к которым может относиться данная единица. В состав лексических единиц включаются словокомплексы (устойчивые терминологические сочетания или семантические формулы типа «how many») и шаблоны (несловарные единицы, имеющие регулярную структуру, например, номера телефонов). На основе определенных правил комбинации семантических типов, имеющих пересекающиеся ориентации, строятся предикаты, связываемые логическими связками в единое представление.
Ориентации в традиционном синтаксическом анализе могут соответствовать согласовательным характеристикам, таким как число, а семантические типы – атрибут, значение, предикатная формула – синтаксическим, таким как существительное, прилагательное, именная группа. Этот подход позволяет строить структуры, большие по объему, чем предложения, связывая их дискурсными связями в соответствии с тематическими ориентациями фрагментов текста.
Одной из основных проблем работы ЕЯ-систем является проблема многозначности (омонимии и синонимии): проблема выбора вариантов, возникающая из-за того, что в ЕЯ имеет место одномерный план выражения при многомерном плане содержания. Данная проблема характерна для всех уровней лексического анализа. Существует три основных подхода к решению подобных задач:
а) метод фильтров – заключается в том, что сначала получают все варианты предложения, а затем отбраковывают те, которые не удовлетворяют некоторой системе условий (фильтров в виде продукционных правил, путём приписывания штрафов, с использованием вероятностных методов);
б) эвристический метод – состоит в том, что с самого начала строится лишь часть вариантов, более правдоподобных с точки зрения заданных критериев (например приписывание дугам весов);
в) многоагентный анализ – предложение анализируется несколькими независимыми и взаимодействующими агентами, проблема разрешения многозначности сводится к разрешению конфликтов между агентами.
Метод фильтров является наименее быстродействующим, но гарантирует рассмотрение всех вариантов изоморфных структур. Данный подход также предусматривает возможность явного указания на неразрешимость проблемы многозначности на данном уровне, т.е. множественность выходов.
Кроме того, при переходе на более высокий уровень, проблема многозначности часто устраняется фильтрующими правилами в явном виде. Семантическая многозначность является наиболее сложной.
Прямое применение существующего аппарата описания формальных языков к ЕЯ невозможно из-за того, что это объект принципиально другой природы. В частности, ЕЯ не следует задуманной и последовательно реализованной концепции и не является просто вещью в себе, а соотносится со структурами знания, используемыми его носителями.
Этим объясняется множественность теорий представления ЕЯ-феноменов. Наиболее полной и удачной теорией является, по-видимому, модель «Смысл↔Текст». Этот вывод косвенно подтверждается эволюцией других теорий к традициям «С↔Т». Однако, удаленность «С↔Т» от вычислительных формализмов требуетсоздания этих формализмов для реализации на ЭВМ.
Сложность процессов анализа и синтеза ЕЯ-структур приводит к разделению этих процессов на этапы: семантический, синтаксический, морфологический.
Важной проблемой анализа является снятие многозначности, синтеза – снятие многовариантности.
В настоящее время ни одна из теорий не может претендовать на полноту описания ЕЯ-феноменов, хотя наиболее продвинутые лингвистические теории (такие как модель «Смысл↔Текст» и трансформационные грамматики Хомского) достигли удовлетворительных теоретических результатов. Однако, подобные теории используют предложение как структурную единицу и имеют слабые средства представления связного текста. Кроме того, некоторые теории требуют дополнительной формализации для их реализации на ЭВМ.

