 2015-05-18
2015-05-18 5106
51061. Отбор факторов производится на основе качественного теоретико-экономического анализа, то есть включение в уравнение тех или иных факторов должно опираться на понимание природы взаимосвязи экономических переменных.
2. Факторы должны быть количественно измеримы. Если исследователь хотел бы включить в модель качественный фактор (например, район города как фактор цены на квартиру), то нужно придать этому фактору количественную определенность. В зависимости от целей модели район города можно ранжировать по экологической ситуации, или по удаленности от центра и в модель включить уже порядковый номер района в ранжированном ряду.
3. Каждый из факторов не может быть частью другого.
4. Число включаемых факторов должно быть как минимум в 6-7 раз меньше объема совокупности, по которой изучается регрессия.
5. Каждый дополнительно включенный в уравнение регрессии фактор должен увеличивать множественный коэффициент детерминации, то есть доля объясненной вариации результативного признака за счет включенного фактора должна увеличиваться, а, соответственно, доля остаточной вариации должна уменьшаться. Если до включения фактора в модель и после его включения коэффициенты множественной детерминации мало отличаются друг от друга, то данный фактор является лишним в модели. Насыщение модели лишними факторами приводит к статистической недостоверности параметров регрессии по критерию Стьюдента.
6. Факторы, включенные в модель, должны быть независимы друг от друга, то есть они не должны быть интеркоррелированы друг с другом и, тем более, находиться в жесткой функциональной связи. Если между самими факторами существует высокая корреляция, то нельзя определить их изолированное влияние на результат и параметры уравнения тогда невозможно интерпретировать.
Проблема коррелированности факторов является наиболее серьезной проблемой множественной регрессии, поэтому рассмотрим ее подробнее.
Коллинеарность факторов, методы преодоления межфакторной связи:
Предположим, что у = a +b1х1 +b2х2 + и и допустим, что величины b1и b2 положительны и х1 и х2 положительно коррелированы.
Что произойдет, если оценить парную регрессию между у и х1? По мере увеличения х1:
1) у имеет тенденцию к росту, поскольку коэффициент b1 положителен; 2) х2 имеет тенденцию к росту, так как х1 и х2 положительно коррелированы;
3) у получит ускорение из-за увеличения х2 и благодаря тому, что коэффициент b2 положителен. Другими словами, изменения у будут преувеличивать влияние текущих значений х1, так как отчасти они будут связаны с изменениями х2. В результате оценка значения b1 будет смещена
Считается, что факторы явно коллинеарны (то есть находятся между собой в линейной зависимости), если коэффициент парной линейной корреляции между ними rx1x2 ³ 0,7. Коллинеарность факторов нарушает условие независимости объясняющих переменных и приводит к тому, что факторы дублируют друг друга. Коэффициенты интеркорреляции (то есть коэффициенты корреляции между самими факторами) позволяют исключать из модели какой-то из дублирующих факторов. Оставлять в модели следует не тот фактор, который теснее связан с результатом, а тот, который при достаточно тесной связи с результатом имеет наименьшую тесноту связи с другими факторами.
Наибольшие трудности в аппарате множественной регрессии возникают при наличии мультиколлинеарности факторов, когда более двух факторов связаны между собой тесной линейной зависимостью, то есть имеет место совокупное воздействие факторов друг на друга. Включение мультиколлинеарных факторов в модель приводит к следующим негативным последствиям:
1) такие факторы всегда будут действовать в унисон, поэтому затрудняется интерпретация параметров множественной регрессии как характеристик действия факторов в «чистом виде», параметры линейной множественной регрессии теряют экономический смысл;
2) оценки параметров связи становятся ненадежными, обнаруживают большие стандартные ошибки, что делает модель непригодной для анализа и прогнозирования.
Существует ряд методов, которые позволяют преодолеть сильную межфакторную связь.
Первый метод основан на последовательном анализе коэффициентов множественной детерминации, где в качестве зависимой переменной рассматривается каждый из факторов (R2x1/x2x3…, R2x2 /x1x3 и т.п.). Чем ближе значение коэффициента множественной детерминации к единице, тем сильнее проявляется мультиколлинеарность факторов. Сравнивая между собой коэффициенты множественной детерминации факторов, можно выделить переменные, ответственные за мультиколлинеарность и исключить их из модели. В уравнении останутся факторы с минимальной величиной межфакторной связи.
Второй метод связан с преобразованием факторов, при котором уменьшается корреляция между ними. Этот метод наиболее часто используется при анализе корреляции в динамических рядах экономических показателей. При построении модели на основе рядов динамики переходят от первоначальных данных к первым разностям уровней 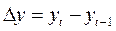 , чтобы исключить влияние тенденции (мы подробнее познакомимся с этим методом позднее в теме «корреляция в рядах динамики»).
, чтобы исключить влияние тенденции (мы подробнее познакомимся с этим методом позднее в теме «корреляция в рядах динамики»).
Третий метод – построение совмещенных уравнений регрессии. Совмещенными называют уравнения, которые отражают не только влияние факторов, но и их взаимодействие. Так, если у=f(x1,x2,x3), то возможно построение следующего совмещенного уравнения
y=a+b1x1+b2 x2+b3x3+b12x1x2+b13 x1x3+b23 x2x3
Если дисперсионный анализ совмещенного уравнения по критерию Фишера доказал статистическую значимость взаимодействия только первого и третьего факторов, то уравнение регрессии будет иметь вид:
y=a+b1x1+b2 x2+b3x3+2+b13 x1x3
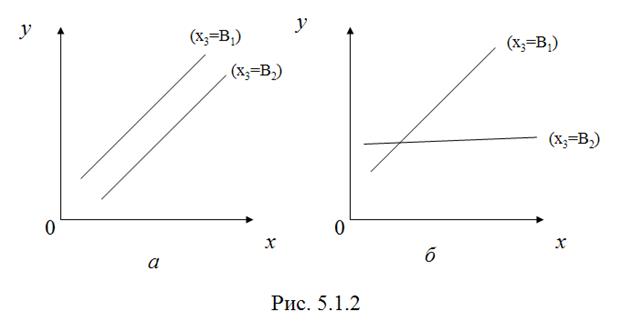 Взаимодействие факторов (первого и третьего) можно продемонстрировать на рисунке.
Взаимодействие факторов (первого и третьего) можно продемонстрировать на рисунке.
Если взаимодействие есть, то на разных уровнях третьего фактора влияние первого фактора будет неодинаково (б). И наоборот, параллельные линии влияния первого фактора на результат при разных уровнях третьего фактора означают отсутствие взаимодействия самих факторов (а).
Четвертый метод преодоления мультиколлинеарности факторов – переход к уравнениям приведенной формы. С этой целью в уравнение регрессии производится подстановка рассматриваемого фактора через выражение его из другого уравнения. Пусть, например, рассматривается двухфакторная регрессия у = a +b1х1 +b2х2, для которой факторы обнаруживают высокую корреляцию. Если исключить один из факторов, то мы придем к уравнению парной регрессии. Вместо этого, можно оставить факторы в модели, но исследовать данное двухфакторное уравнение регрессии вместе с другим уравнением, где второй фактор рассматривается как зависимая переменная х2 = А + Ву+ Сх3.. Далее можно подставить правую часть данного равенства (А + Ву+ Сх3) вместо х2 в исходную модель.
Итак, мы имели следующие проблемы: первый и второй фактор одновременно включать было нельзя из-за тесной их связи; второй фактор был также функционально связан с третьим фактором, что также не давало возможности их одновременного включения. Выразив второй фактор через третий, мы включили его действие в модель, избежав при этом корреляции самих факторов.
Параметризация уравнения множественной регрессии и его интерпретация:
Установив перечень признаков-факторов, и предварительно оценив форму связи, можно записать соответствующее математическое уравнение теоретической линии множественной регрессии. Так, например, в случае двухфакторной линейной регрессии нахождение неизвестных параметров по методу наименьших квадратов предполагает решение системы нормальных уравнений:
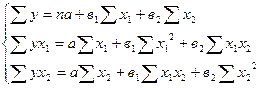
Комментируя решенное уравнение, следует помнить о том, что существует различие в интерпретации коэффициента регрессии в парных и множественных моделях. В уравнениях парной регрессии коэффициент в называют коэффициентом полной регрессии. Он показывает, как в среднем изменится у при изменении х на единицу, при условии, что влияние других факторов не учтено. В уравнениях множественной регрессии коэффициент вi называют коэффициентом чистой регрессии. Он измеряет среднее изменение у при изменении фактора хi на единицу, но при условии, что действие других факторов, включенных в уравнение регрессии, учтено и зафиксировано на среднем уровне.
Коэффициенты регрессии в уравнении связи несопоставимы друг с другом в силу разных единиц измерения. Для целей сравнения и определения приоритетности факторов определяют стандартизованные коэффициенты регрессии: коэффициенты эластичности и бета-коэффициенты.
Коэффициенты эластичности для линейной связи определяются по формулам
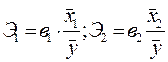 и т.д.
и т.д.
Они показывают, на сколько процентов изменится признак-результат, если признак-фактор изменится на один процент.
Формулы для расчета бета-коэффициентов имеют вид
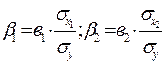
Величина бета-коэффициента показывает, на сколько средних квадратических отклонений изменится у, если хi изменится на одно среднее квадратическое отклонение.
Стандартизованные коэффициенты регрессии позволяют выделить приоритетные факторы, в изменении которых заложены наибольшие возможности в управлении изменением результативного признака.
Часто линейная регрессионная модель используется в функциях потребления (спроса), где у – потребление товара или группы товаров, а факторами могут быть доход семьи в текущем и предшествующем периоде, размер семьи, цены, прошлые привычки потребления, то есть потребление товара в предшествующем периоде. Параметр а в таком уравнении не подлежит экономической интерпретации, а коэффициенты регрессии рассматриваются как характеристики склонности к потреблению.
Например, функция потребления имеет вид Пt = a +b1Dt + b2Dt-1
где потребление в период времени t зависит от дохода того же периода Dt и от дохода предшествующего периода Dt-1. Коэффициент в1 называют краткосрочной предельной склонностью к потреблению. Он показывает, на сколько увеличится потребление товара при увеличении доходов текущего периода на единицу. Общим эффектом возрастания как текущего, так и предыдущего дохода будет рост потребления на величину b = b1 + b2. Коэффициент в рассматривается здесь как долгосрочная склонность к потреблению.
Однако аддитивная модель пригодна не для любых связей в экономике. Если, например, изучается зависимость объема продукции предприятия от занимаемых площадей, числа работников, стоимости основных фондов (или всего капитала), то каждый из факторов является необходимым для существования результата, а не добавлением к нему. В таких ситуациях нужно исходить из гипотезы о мультипликативной форме модели:
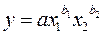
Такая модель по ее первым создателям получила название модель Кобба-Дугласа. Это степенная функция и, как мы уже знаем, показатели степени при факторах являются коэффициентами эластичности. Они показывают, на сколько процентов изменяется в среднем результат с изменением соответствующего фактора на 1 процент при неизменности других факторов. Степенные множественные функции часто используются как производственные функции, где результатом выступают объемы производства, а факторами – используемые ресурсы (трудовые ресурсы, основные производственные фонды, машины, текущие затраты и т.п.). Экономический смысл здесь имеют не только коэффициенты эластичности по каждому фактору, но и их сумма
B = b1+b2. Эта величина фиксирует обобщенную характеристику эластичности производства (показывает, на сколько процентов в среднем увеличиваются объемы производства при увеличении всех факторов на 1%).
Дополнительно!!! Множественная корреляция:
Наиболее общим показателем тесноты связи всех входящих в уравнение регрессии факторов с результативным признаком является коэффициент множественной детерминации R2. Принципиальное содержание множественного коэффициента детерминации, как и парного, раскрывается формулой
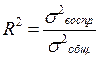
Это отношение части вариации результативного признака, объясняемой за счет вариации входящих в уравнение факторов к общей вариации результативного признака за счет всех факторов.
Для случая двухфакторной линейной связи коэффициент множественной детерминации можно вычислить из парных коэффициентов детерминации по формуле
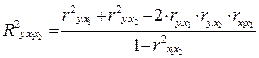
Кроме определения показателя общей тесноты связи результативного признака со всеми факторами, включенными в уравнение, множественный корреляционно-регрессионный анализ дает возможность измерить долю каждого фактора в общей вариации результативного признака. Для этого рассчитывают коэффициенты раздельной (частной) детерминации по одной из формул
1) 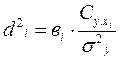 , где
, где 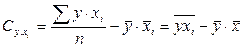
2) 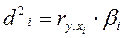
Сумма коэффициентов раздельной детерминации дает множественный коэффициент детерминации
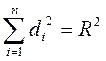
Качество уравнения множественной регрессии, а также его практическая значимость оценивается с помощью показателей множественной корреляции и детерминации, которые измеряют тесноту совместного влияния факторов на результат. Независимо от формы связи показатель множественной корреляции может быть найден как индекс множественной корреляции, что предполагает решение уравнения множественной регрессии и определения на его основе остаточной дисперсии
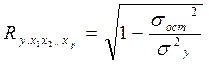
Величина индекса множественной корреляции должна быть больше или равна максимальному парному индексу корреляции
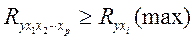
При правильном включении факторов в регрессионный анализ величина индекса множественной корреляции будет существенно отличаться от индекса парной корреляции. Если же дополнительно включенные в уравнение множественной регрессии факторы третьестепенны, то индекс множественной корреляции может практически совпадать с индексом парной корреляции (различия в третьем и далее знаках). Таким образом, сравнивая индексы множественной и парной корреляции, можно делать вывод о целесообразности включения в уравнение регрессии того или иного фактора.
При линейной зависимости признаков формула индекса корреляции может быть представлена следующим выражением
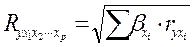
где β – стандартизованные коэффициенты регрессии, а r - парные коэффициенты корреляции результата с каждым фактором.
При трех переменных для двухфакторного линейного уравнения регрессии величина множественного коэффициента корреляции может быть определена по формуле
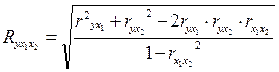
Индекс множественной корреляции равен коэффициенту множественной корреляции в двух случаях:
1) при линейной зависимости рассматриваемых признаков;
2) при криволинейной зависимости, нелинейной по переменным, но линейной по параметрам.
Иначе обстоит дело с криволинейной регрессией, нелинейной по параметрам. Рассмотрим производственную функцию Кобба-Дугласа:
где у - объем продукции; х1 - затраты труда; х2 - величина капитала. Логарифмируя ее, получим линейное в логарифмах уравнение
loq y = loq a + b1loq x1 + b2loq x2
Определив параметры этого уравнения по МНК, можно найти теоретические значения объема продукции 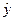 и соответственно остаточную сумму квадратов отклонений
и соответственно остаточную сумму квадратов отклонений 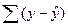 , которая используется в расчете индекса детерминации (корреляции). Величина индекса множественной корреляции, определенная таким образом, не будет совпадать с линейным коэффициентом множественной корреляции, который может быть рассчитан для линейного в логарифмах уравнения регрессии. Это объясняется тем, что в данном случае МНК применяется не к исходным данным, а к их логарифмам, поэтому на факторную и остаточную сумму квадратов отклонений раскладывается не зависимая переменная, а ее логарифм.
, которая используется в расчете индекса детерминации (корреляции). Величина индекса множественной корреляции, определенная таким образом, не будет совпадать с линейным коэффициентом множественной корреляции, который может быть рассчитан для линейного в логарифмах уравнения регрессии. Это объясняется тем, что в данном случае МНК применяется не к исходным данным, а к их логарифмам, поэтому на факторную и остаточную сумму квадратов отклонений раскладывается не зависимая переменная, а ее логарифм.
Дополнительно!!! Скорректированный индекс детерминации (корреляции):
В рассмотренных показателях множественной корреляции (индекс и коэффициент) используется остаточная дисперсия, которая имеет систематическую ошибку в сторону преуменьшения, тем более значительную, чем больше параметров определяется в уравнении регрессии при заданном объеме п. Таким образом, чем больше параметров при х, тем ближе остаточная дисперсия к нулю и, тем ближе коэффициент (индекс) корреляции приблизится к единице даже при слабой связи фактора с результатом. Для того, чтобы не допускать возможного преувеличения тесноты связи, используется скорректированный индекс (коэффициент) множественной корреляции.
Скорректированный индекс множественной корреляции содержит поправку на число степеней свободы, а именно: остаточная сумма квадратов делится на число степеней свободы остаточной вариации, а общая сумма квадратов делится на число степеней свободы в целом по совокупности
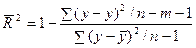
Поскольку 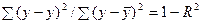 , то величину скорректированного индекса детерминации можно представить в виде
, то величину скорректированного индекса детерминации можно представить в виде
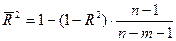
Чем больше т, тем сильнее различия между 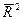 и R2.
и R2.
Для линейной зависимости признаков скорректированный коэффициент множественной корреляции определяется как корень квадратный из скорректированного коэффициента детерминации. Отличие состоит лишь в том, что в линейной регрессии под т понимают число факторов, включенных в модель, а в криволинейной зависимости т – число параметров при х и их преобразованиях (х2, loq x и др.). Так, для функции
y = a + b1x1 + c1x21+ b2x2 + c2x22 m = 4.
При заданном объеме наблюдений с увеличением числа факторов скорректированный коэффициент множественной детерминации убывает Его величина может стать и отрицательной при слабых связях результата с факторами, в этом случае он должен считаться равным нулю. Чем больше объем совокупности, тем ближе значения и R2.
В статистических пакетах прикладных программ в процедуре множественной регрессии обычно приводится скорректированный коэффициент (индекс) корреляции (детерминации). Величина коэффициента детерминации применяется для оценки качества модели. Низкое значение показателя означает, что в модель не включены существенные факторы – с одной стороны, а с другой – форма связи не отражает реальные соотношения между переменными. Требуется дальнейшая работа по улучшению качества модели.
Предпосылки МНК:
При оценке параметров уравнения регрессии мы применяем метод наименьших квадратов (МНК). В модели у = a + b1х + b2 р + е, случайная составляющая (е) представляет собой «необъясненную или ненаблюдаемую величину». После того, как произведено решение модели, то есть дана оценка параметрам, мы можем определить величину остатков в каждом конкретном случае как разность между фактическими и теоретическими значениями результативного признака еi=yi- 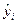 . Поскольку это не есть реальные остатки, то мы их считаем лишь выборочной реализацией неизвестного остатка заданного уравнения. При изменении спецификации модели, добавления в нее новых наблюдений, выборочные оценки остатков могут меняться, поэтому в задачу регрессионного анализа входит не только построение самой модели, но и исследование случайных отклонений, то есть остаточных величин.
. Поскольку это не есть реальные остатки, то мы их считаем лишь выборочной реализацией неизвестного остатка заданного уравнения. При изменении спецификации модели, добавления в нее новых наблюдений, выборочные оценки остатков могут меняться, поэтому в задачу регрессионного анализа входит не только построение самой модели, но и исследование случайных отклонений, то есть остаточных величин.
В предыдущих разделах мы останавливались на формально-математических проверках статистической достоверности коэффициентов регрессии и корреляции с помощью Т -критерия Стьюдента и критерия Фишера. При использовании этих критериев делаются предположения относительно поведения остатков: предполагают, что 1) остатки представляют собой независимые случайные величины и их среднее значение равно нулю; 2) остатки имеют постоянную дисперсию и подчиняются закону нормального распределения.
Пока мы не построим модель, остатки определены быть не могут, и поэтому мы не можем проверить, обладают ли они этими свойствами или нет. Таким образом, проверяя статистическую достоверность параметров связи, мы опираемся всего лишь на непроверенные предпосылки о распределении случайной составляющей уравнения регрессии. Но после построения уравнения регрессии мы уже можем определить остатки и проверить у них наличие тех свойств, которые предполагались вначале.
С чем связана необходимость проверки таких свойств? Связано это с тем, что выборочные оценки параметров регрессии должны отвечать определенным критериям. Они должны быть несмещенными, состоятельными и эффективными. Эти свойства оценок, полученных по МНК, имеют важное практическое значение в использование результатов регрессии и корреляции.
Несмещенные оценки означают, что математическое ожидание остатков равно нулю. Следовательно, при большом числе выборочных оценок коэффициента регрессии в найденный параметр по результатам одной выборки можно рассматривать как среднее значение из большого числа несмещенных оценок.
Оценки считаются эффективными, если они характеризуются меньшей дисперсией (то есть мы имеем минимальную вариацию выборочных оценок).
Оценки считаются состоятельными, если их точность увеличивается с увеличением объема выборки.
Условия, необходимые для получения несмещенных, состоятельных и эффективных оценок, представляют собой предпосылки МНК, соблюдение которых желательно для получения достоверных результатов регрессии.
Предпосылки МНК:
1- случайный характер остатков;
2- гомоскедастичность – дисперсия остатков одинакова для всех значений фактора;
3- отсутствие автокорреляции остатков (то есть остатки распределены независимо друг от друга);
4- остатки подчиняются нормальному закону распределения.
В тех случаях, когда эти предпосылки выполняются, оценки, полученные по МНК, будут обладать вышеназванными свойствами, если же некоторые предпосылки не выполняются, то необходимо корректировать модель.
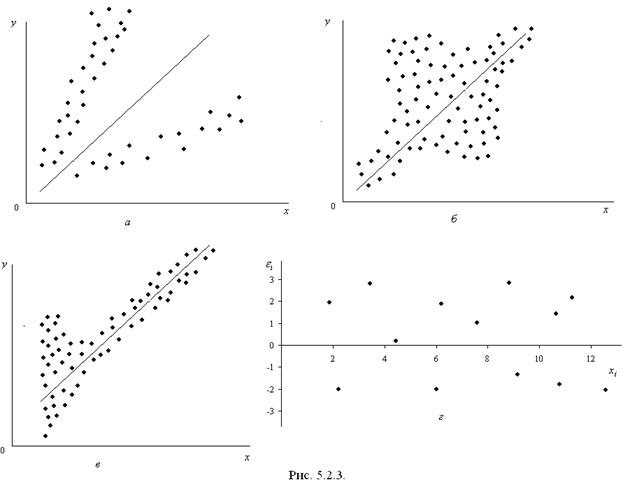
Итак, проверяем случайный характер остатков. С этой целью строится график зависимости остатков от теоретических значений результативного признака.
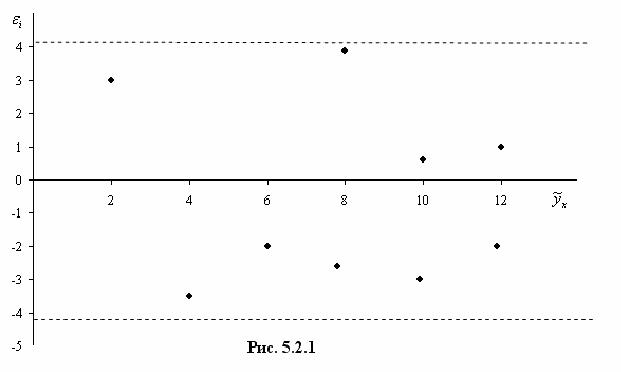
Если на графике получена горизонтальная полоса, то остатки представляют собой случайные величины и МНК оправдан.
Возможны иные случаи:
а) – остатки носят систематический характер, то есть отрицательные значения соответствуют низким значениям расчетных «у», а положительные – высоким;
б) – преобладание положительных остатков над отрицательными. В этих случаях необходимо применять либо другую функцию, либо вводить дополнительную информацию и заново строить уравнение регрессии до тех пор, пока остатки не будут случайными величинами.
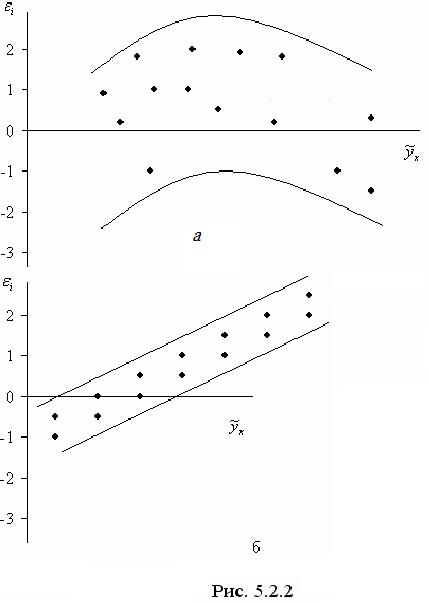
Вторая предпосылка МНК требует, чтобы дисперсия остатков была гомоскедастичной. Это значит, что для каждого значения фактора остатки имеют одинаковую дисперсию. Если это условие не соблюдается, то имеет место гетероскедастичность. Наличие гомо- или гетероскедастичности можно видеть по графику зависимости остатков от теоретических значений результативного признака:
а) большая дисперсия остатков для больших значений «у» (гетероскедастичность);
б) большая дисперсия остатков для средних значений «у» (гетероскедастичность);
в) – большая дисперсия для меньших значений результата (гетероскедастичность);
г) – равная дисперсия (гомоскедастичность).
Наличие гетероскедастичности приводит к смещенным оценкам коэффициентов регрессии, а также уменьшает их эффективность. В частности, становится затруднительным использование формулы стандартной ошибки коэффициента регрессии, которая предполагает единую дисперсию остатков.
Для множественной регрессии данный вид графиков является наиболее приемлемым визуальным способом изучения гомо- или гетероскедастичности. Однако, чтобы убедиться в наличии этих качеств, обычно не ограничиваются визуальной проверкой гетероскедастичности, а проводят также ее количественное подтверждение. При малом объеме выборки, что характерно для эконометрических исследований для этих целей используется метод Гольдфельда –Квандта, который включает в себя следующие шаги:
1. Упорядочение наблюдений по мере возрастания фактора х.
2. Исключение из наблюдений нескольких центральных наблюдений (С). При этом должно выполняться условие, что (N – С)/2 должно быть больше р – число параметров в модели.
3. Распределение оставшихся наблюдений на две равные группы с малыми и большими значениями факторного признака.
4. Решение уравнения регрессии для каждой группы (имеем два уравнения).
5. Определение остаточной суммы квадратов отклонений для каждой группы и определение их отношения (отношение большей к меньшей).
6. Сравнение этого отношения с табличным значением критерия Фишера (d f = n - C – 2p/2). Если это отношение меньше табличного значения F- критерия, то мы имеем гомоскедастичные остатки. Чем больше это отношение превышает табличное, тем больше нарушена предпосылка о равенстве дисперсий остаточных величин.
Следующая предпосылка МНК – это отсутствие автокорреляции остатков. Это означает, что остатки распределены независимо друг от друга. Автокорреляция – это наличие тесной корреляционной зависимости между остатками текущих и предшествующих наблюдений, если наблюдения упорядочены по фактору х. Автокорреляционная зависимость определяется по линейному коэффициенту корреляции между текущими и предшествующими наблюдениями (более подробно с этой проблемой мы ознакомимся в теме «Моделирование рядов динамики»). Отсутствие автокорреляции остатков обеспечивает состоятельность и эффективность оценок коэффициентов регрессии.
Соответствие распределение остатков нормальному закону распределения можно проверить с помощью критерия Пирсона как критерия согласия.
При несоблюдении основных предпосылок МНК приходится корректировать модель, изменяя ее спецификацию, добавлять или исключать некоторые факторы, преобразовывать исходные данные. В частности, при нарушении гомоскедастичности и наличии автокорреляции остатков рекомендуется традиционный МНК, который проводится по исходным данным, заменять обобщенным методом наименьших квадратов, который проводится по преобразованным данным. Обобщенный метод наименьших квадратов применяется к преобразованным данным и позволяет получать оценки, которые обладают не только свойством несмещенности, но и имеют меньшие выборочные дисперсии.

