 2015-05-18
2015-05-18 2288
2288| Номер команды | Номер такта | ||||||||
| Команда i | IF | ID | EX | MEM | WB | ||||
| Команда i+1 | IF | ID | EX | MEM | WB | ||||
| Команда i+2 | IF | ID | EX | MEM | WB | ||||
| Команда i+3 | IF | ID | EX | MEM | WB | ||||
| Команда i+4 | IF | ID | EX | MEM | WB |
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. В действительности она даже несколько увеличивает время выполнения каждой команды из-за накладных расходов, связанных с управлением регистровыми станциями. Однако увеличение пропускной способности означает, что программа будет выполняться быстрее по сравнению с простой неконвейерной схемой.
Тот факт, что время выполнения каждой команды в конвейере не уменьшается, накладывает некоторые ограничения на практическую длину конвейера. Кроме ограничений, связанных с задержкой конвейера, имеются также ограничения, возникающие в результате несбалансированности задержки на каждой его ступени и из-за накладных расходов на конвейеризацию. Частота синхронизации не может быть выше, а, следовательно, такт синхронизации не может быть меньше, чем время, необходимое для работы наиболее медленной ступени конвейера. Накладные расходы на организацию конвейера возникают из-за задержки сигналов в конвейерных регистрах (защелках) и из-за перекосов сигналов синхронизации. Конвейерные регистры к длительности такта добавляют время установки и задержку распространения сигналов.
В качестве примера рассмотрим неконвейерную машину с пятью этапами выполнения операций, которые имеют длительность 50, 50, 60, 50 и 50 нс соответственно (рис. 12).
Пусть накладные расходы на организацию конвейерной обработки составляют 5 нс. Тогда среднее время выполнения команды в неконвейерной машине будет равно 260 нс. Если же используется конвейерная организация, длительность такта будет равна длительности самого медленного этапа обработки плюс накладные расходы, т.е. 65 нс. Это время соответствует среднему времени выполнения команды в конвейере. Таким образом, ускорение, полученное в результате конвейеризации, будет равно:
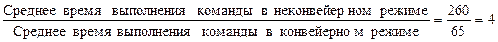
Конвейеризация эффективна только тогда, когда загрузка конвейера близка к полной, а скорость подачи новых команд и операндов соответствует максимальной производительности конвейера. Если произойдет задержка, то параллельно будет выполняться меньше операций и суммарная производительность снизится. Такие задержки могут возникать в результате возникновения конфликтных ситуаций.
При реализации конвейерной обработки возникают ситуации, которые препятствуют выполнению очередной команды из потока команд в предназначенном для нее такте. Такие ситуации называются конфликтами. Конфликты снижают реальную производительность конвейера, которая могла бы быть достигнута в идеальном случае. Существует три класса конфликтов:
1. Структурные конфликты, которые возникают из-за конфликтов по ресурсам, когда аппаратные средства не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением.
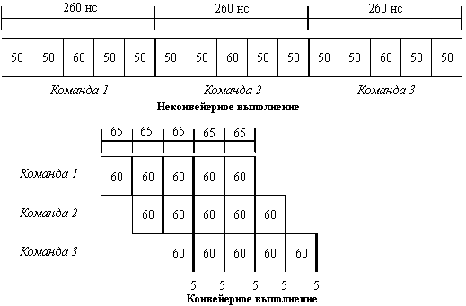
Рис. 12. Эффект конвейеризации при выполнении трех команд – четырехкратное ускорение
2. Конфликты по данным, возникающие в случае, когда выполнение одной команды зависит от результата выполнения предыдущей команды.
3. Конфликты по управлению, которые возникают при конвейеризации команд переходов и других команд, которые изменяют значение счетчика команд.
Конфликты в конвейере приводят к необходимости приостановки выполнения команд. Обычно в простейших конвейерах, если приостанавливается какая-либо команда, то все следующие за ней команды также приостанавливаются. Команды, предшествующие приостановленной, могут продолжать выполняться, но во время приостановки не выбирается ни одна новая команда.
3.3. Классификация систем параллельной обработки данных
На протяжении всей истории развития вычислительной техники делались попытки найти какую-то общую классификацию, под которую подпадали бы все возможные направления развития компьютерных архитектур. Ни одна из таких классификаций не могла охватить все разнообразие разрабатываемых архитектурных решений и не выдерживала испытания временем. Тем не менее в научный оборот попали и широко используются термины, которые полезно знать не только разработчикам, но и пользователям компьютеров.
Любая вычислительная система (будь то супер-ЭВМ или персональный компьютер) достигает своей наивысшей производительности благодаря использованию высокоскоростных элементов и параллельному выполнению большого числа операций. Именно возможность параллельной работы различных устройств системы (работы с перекрытием) является основой ускорения основных операций.
Параллельные ЭВМ часто подразделяются по классификации Флинна на машины типа SIMD и MIMD.
Машины типа SIMD (Single Instruction Multiple Data) – ЭВМ с одним потоком команд при множественном потоке данных.
Машины типа MIMD (Multiple Instruction Multiple Data) – ЭВМ с множественным потоком команд при множественном потоке данных.
Как и любая другая, приведенная выше классификация несовершенна: существуют машины прямо в нее не попадающие, имеются также важные признаки, которые в этой классификации не учтены. В частности, к машинам типа SIMD часто относят векторные процессоры, хотя их высокая производительность зависит от другой формы параллелизма – конвейерной организации машины. Многопроцессорные векторные системы типа Cray Y–MP состоят из нескольких векторных процессоров и поэтому могут быть названы MSIMD (Multiple SIMD).
Можно выделить четыре основных типа архитектуры систем параллельной обработки:
1. Конвейерная и векторная обработка.
Конвейерная обработка была рассмотрена выше. Векторные операции обеспечивают идеальную возможность полной загрузки вычислительного конвейера.
При выполнении векторной команды одна и та же операция применяется ко всем элементам вектора (или чаще всего к соответствующим элементам пары векторов). Для настройки конвейера на выполнение конкретной операции может потребоваться некоторое установочное время, однако затем операнды могут поступать в конвейер с максимальной скоростью, допускаемой возможностями памяти. При этом не возникает пауз ни в связи с выборкой новой команды, ни в связи с определением ветви вычислений при условном переходе. Таким образом, главный принцип вычислений на векторной машине состоит в выполнении некоторой элементарной операции или комбинации из нескольких элементарных операций, которые должны повторно применяться к некоторому блоку данных. Таким операциям в исходной программе соответствуют небольшие компактные циклы.
2. Машины типа SIMD.
Машины типа SIMD состоят из большого числа идентичных процессорных элементов, имеющих собственную память. Все процессорные элементы в такой машине выполняют одну и ту же программу. Машина типа SIMD, составленная из большого числа процессоров, может обеспечить очень высокую производительность только на тех задачах, при решении которых все процессоры могут делать одну и ту же работу. Модель вычислений для машины SIMD очень похожа на модель вычислений для векторного процессора: одиночная операция выполняется над большим блоком данных.
В отличие от ограниченного конвейерного функционирования векторного процессора, матричный процессор (синоним для большинства SIMD-машин) может быть значительно более гибким. Обрабатывающие элементы таких процессоров - это универсальные программируемые ЭВМ, так что задача, решаемая параллельно, может быть достаточно сложной и содержать ветвления. Обычное проявление этой вычислительной модели в исходной программе примерно такое же, как и в случае векторных операций: циклы на элементах массива, в которых значения, вырабатываемые на одной итерации цикла, не используются на другой итерации цикла.
Модели вычислений на векторных и матричных ЭВМ настолько схожи, что эти ЭВМ часто обсуждаются как эквивалентные.
3. Машины типа MIMD.
Термин “мультипроцессор” охватывает большинство машин типа MIMD и (подобно тому как термин “матричный процессор” применяется к машинам типа SIMD) часто используется в качестве синонима для машин типа MIMD. В мультипроцессорной системе каждый процессорный элемент (ПЭ) выполняет свою программу достаточно независимо от других процессорных элементов. Процессорные элементы, конечно, должны как-то связываться друг с другом, что делает необходимым более подробную классификацию машин типа MIMD. В мультипроцессорах с общей памятью (сильносвязанных мультипроцессорах) имеется память данных и команд, доступная всем ПЭ. С общей памятью ПЭ связываются с помощью общей шины или сети обмена. В противоположность этому варианту в слабосвязанных многопроцессорных системах (машинах с локальной памятью) вся память делится между процессорными элементами и каждый блок памяти доступен только связанному с ним процессору. Сеть обмена связывает процессорные элементы друг с другом.
Базовой моделью вычислений на MIMD-мультипроцессоре является совокупность независимых процессов, эпизодически обращающихся к разделяемым данным. Существует большое количество вариантов этой модели. На одном конце спектра - модель распределенных вычислений, в которой программа делится на довольно большое число параллельных задач, состоящих из множества подпрограмм. На другом конце спектра - модель потоковых вычислений, в которых каждая операция в программе может рассматриваться как отдельный процесс. Такая операция ждет своих входных данных (операндов), которые должны быть переданы ей другими процессами. По их получении операция выполняется, и полученное значение передается тем процессам, которые в нем нуждаются.
4. Многопроцессорные машины с SIMD-процессорами.
Многие современные супер-ЭВМ представляют собой многопроцессорные системы, в которых в качестве процессоров используются векторные процессоры или процессоры типа SIMD. Такие машины относятся к машинам класса MSIMD.
Языки программирования и соответствующие компиляторы для машин типа MSIMD обычно обеспечивают языковые конструкции, которые позволяют программисту описывать “крупнозернистый” параллелизм. В пределах каждой задачи компилятор автоматически векторизует подходящие циклы. Машины типа MSIMD, как можно себе представить, дают возможность использовать лучший из этих двух принципов декомпозиции: векторные операции (“мелкозернистый” параллелизм) для тех частей программы, которые подходят для этого, и гибкие возможности MIMD-архитектуры для других частей программы.
Многопроцессорные системы за годы развития вычислительной техники претерпели ряд этапов своего развития. Исторически первой стала осваиваться технология SIMD. Однако в настоящее время наметился устойчивый интерес к архитектурам MIMD. Этот интерес, главным образом, определяется двумя факторами:
1. Архитектура MIMD дает большую гибкость: при наличии адекватной поддержки со стороны аппаратных средств и программного обеспечения MIMD может работать как однопользовательская система, обеспечивая высокопроизводительную обработку данных для одной прикладной задачи, как многопрограммная машина, выполняющая множество задач параллельно, и как некоторая комбинация этих возможностей.
2. Архитектура MIMD может использовать все преимущества современной микропроцессорной технологии на основе строгого учета соотношения стоимость/производительность. В действительности практически все современные многопроцессорные системы строятся на тех же микропроцессорах, которые можно найти в персональных компьютерах, рабочих станциях и небольших однопроцессорных серверах.
Существующие MIMD-машины распадаются на два основных класса в зависимости от количества объединяемых процессоров, которое определяет и способ организации памяти, и методику их межсоединений.
К первой группе относятся машины с общей (разделяемой) основной памятью, объединяющие до нескольких десятков (обычно менее 32) процессоров. Сравнительно небольшое количество процессоров в таких машинах позволяет иметь одну централизованную общую память и объединить процессоры и память с помощью одной шины. При наличии у процессоров кэш-памяти достаточного объема высокопроизводительная шина и общая память могут удовлетворить обращения к памяти, поступающие от нескольких процессоров. Поскольку имеется единственная память с одним и тем же временем доступа, эти машины иногда называются UMA (Uniform Memory Access). Такой способ организации со сравнительно небольшой разделяемой памятью в настоящее время является наиболее популярным.
Вторую группу машин составляют крупномасштабные системы с распределенной памятью. Для того чтобы поддерживать большое количество процессоров, приходится распределять основную память между ними, в противном случае полосы пропускания памяти просто может не хватить для удовлетворения запросов, поступающих от очень большого числа процессоров. Естественно, при таком подходе также требуется реализовать связь процессоров между собой.
С ростом числа процессоров невозможно обойти необходимость реализации модели распределенной памяти с высокоскоростной сетью для связи процессоров. С быстрым ростом производительности процессоров и связанным с этим ужесточением требования увеличения полосы пропускания памяти масштаб систем (т.е. число процессоров в системе), для которых требуется организация распределенной памяти, уменьшается, также как и уменьшается число процессоров, которые удается поддерживать на одной разделяемой шине и общей памяти.
Распределение памяти между отдельными узлами системы имеет два главных преимущества. Во-первых, это эффективный с точки зрения стоимости способ увеличения полосы пропускания памяти, поскольку большинство обращений могут выполняться параллельно к локальной памяти в каждом узле. Во-вторых, это уменьшает задержку обращения (время доступа) к локальной памяти. Эти два преимущества еще больше сокращают количество процессоров, для которых архитектура с распределенной памятью имеет смысл.
4. Многомашинные системы
4.1. Многомашинные вычислительные комплексы (ММВК)
Двумя основными проблемами построения вычислительных систем для критически важных приложений, связанных с обработкой транзакций, управлением базами данных и обслуживанием телекоммуникаций, являются обеспечение высокой производительности и продолжительного функционирования систем. Наиболее эффективный способ достижения заданного уровня производительности – применение параллельных масштабируемых архитектур. Задача обеспечения продолжительного функционирования системы имеет три составляющих: надежность, готовность и удобство обслуживания. Все эти три составляющие предполагают, в первую очередь, борьбу с неисправностями системы, порождаемыми отказами и сбоями в ее работе. Эта борьба ведется по всем трем направлениям, которые взаимосвязаны и применяются совместно.
В последние годы в литературе по вычислительной технике все чаще употребляется термин “системы высокой готовности” (High Availability Systems). Все типы систем высокой готовности имеют общую цель - минимизацию времени простоя. Имеется два типа времени простоя компьютера: плановое и неплановое. Минимизация каждого из них требует различной стратегии и технологии. Плановое время простоя обычно включает время, принятое руководством, для проведения работ по модернизации системы и для ее обслуживания. Неплановое время простоя является результатом отказа системы или компонента. Хотя системы высокой готовности, возможно, больше ассоциируются с минимизацией неплановых простоев, они оказываются также полезными для уменьшения планового времени простоя. Следует отметить, что высокая готовность не дается бесплатно. Стоимость систем высокой готовности намного превышает стоимость обычных систем.
Главными характеристиками систем высокой готовности по сравнению со стандартными системами являются пониженная частота отказов и более быстрый переход к нормальному режиму функционирования после возникновения неисправности посредством быстрого восстановления приложений и сетевых сессий до того состояния, в котором они находились в момент отказа системы. Следует отметить, что во многих случаях пользователей вполне может устроить даже небольшое время простоя в обмен на меньшую стоимость системы высокой готовности по сравнению со значительно более высокой стоимостью обеспечения режима непрерывной готовности.
Создание систем высокой готовности возможно на основе многомашинных вычислительных систем.
Многомашинная вычислительная система (ММВС) – вычислительная система, содержащая несколько ЭВМ, каждая из которых имеет свою оперативную память и работает под управлением своей операционной системы, а также средства обмена информацией между машинами.
Многомашинные системы, создаваемые путем комплексирования оборудования нескольких серийных ЭВМ, часто называют многомашинными вычислительными комплексами (ММВК). ММВК обычно используются для управления каким-либо объектом.
Конфигурации ММВК, предлагаемые современной компьютерной промышленностью, простираются в широком диапазоне от “простейших” жестких схем, обеспечивающих дублирование основной системы отдельно стоящим горячим резервом в соотношении 1:1, до весьма свободных кластерных схем, позволяющих одной системе подхватить работу любой из нескольких систем в кластере в случае их неисправности.
Рис. 13. Структура двухмашинной системы
Термин “кластеризация” на сегодня в компьютерной промышленности имеет много различных значений. Строгое определение могло бы звучать так: “реализация объединения машин, представляющегося единым целым для прикладных программ и пользователей”. Машины, кластеризованные вместе таким способом, могут при отказе одного процессора очень быстро перераспределить работу на другие процессоры внутри кластера. Это, возможно, наиболее важная задача многих поставщиков систем высокой готовности.
Кластерные системы, благодаря тому, что они обеспечивают достаточно высокий уровень готовности систем при относительно низких затратах, получили наибольшее распространение в мире. Имеются несколько поставщиков, которые называют свои системы высокой готовности “кластерами” или “простыми кластерами”.
ММС могут быть однородными и неоднородными.
Однородные многомашинные системы – системы, состоящие из однотипных ЭВМ.
Неоднородные ММС состоят из ЭВМ различного типа.
ММС могут иметь одноуровневую и иерархическую структуру. В первом случае машины системы образуют один общий уровень обработки данных, а во втором система содержит отдельные машины для выполнения различных уровней обработки информации. Обычно менее мощная машина (сателлит) берет на себя ввод информации с различных терминалов и ее предварительную обработку, разгружая от этих сравнительно простых операций основную более мощную ЭВМ, чем достигается увеличение общей пропускной способности комплекса.
Современные конструкции ММВК предполагают использование горячего резерва (Fail-Over), включая переключение прикладных программ и пользователей на другую машину с гарантией отсутствия потерь или искажений данных во время отказа и переключения.
Такое переключение может выполняться вручную или автоматически, и имеется несколько уровней автоматизации этого процесса. Например, в некоторых случаях пользователи инструктируются о том, что они должны выйти и снова войти в систему. В других случаях переключение осуществляется более прозрачным для пользователя способом: он только должен подождать в течение короткого периода времени. Иногда пользователь может делать выбор между ручным и автоматическим переключением. В некоторых системах пользователи могут продолжить работу после переключения именно с той точки, где они находились во время отказа. В других случаях их просят повторить последнюю транзакцию.
Резервная система не обязательно должна полностью повторять систему, которую она резервирует (конфигурации систем могут отличаться). Это позволяет в ряде случаев сэкономить деньги за счет резервирования большой системы или систем с помощью системы меньшего размера и предполагает либо снижение производительности в случае отказа основной системы, либо переключение на резервную систему только критичных для жизнедеятельности организации приложений.
Следует добавить, что одни пользователи предпочитают не выполнять никаких приложений на резервной машине, хотя другие, наоборот, стараются немного нагрузить резервный сервер в кластере. Возможность выбора конфигурации системы с помощью процедур начальной установки дает пользователям большую гибкость, позволяя постепенно использовать весь заложенный в системе потенциал.
В настоящее время широкое распространение получила технология параллельных баз данных. Эта технология позволяет множеству машин разделять доступ к единственной базе данных. Распределение заданий по множеству процессорных ресурсов и параллельное их выполнение позволяют достичь более высокого уровня пропускной способности транзакций, поддерживать большее число одновременно работающих пользователей и ускорить выполнение сложных запросов.
Параллельные базы данных находят широкое применение в системах обработки транзакций в режиме on-line, системах поддержки принятия решений и часто используются при работе с критически важными для работы предприятий и организаций приложениями, которые эксплуатируются по 24 часа в сутки.
4.2. Способы организации и их особенности
4.2.1. Базовая модель VAX-кластеров
Компания DEC первой анонсировала концепцию кластерной системы в 1983 году, определив ее как группу объединенных между собой вычислительных машин, представляющих собой единый узел обработки информации. По существу VAX-кластер представляет собой слабосвязанную многомашинную систему с общей внешней памятью, обеспечивающую единый механизм управления и администрирования.
VAX-кластер обладает перечисленными ниже свойствами.
Разделение ресурсов. Компьютеры VAX в кластере могут разделять доступ к общим ленточным и дисковым накопителям. Все компьютеры VAX в кластере могут обращаться к отдельным файлам данных как к локальным.
Высокая готовность. Если происходит отказ одного из VAX-компьютеров, задания его пользователей автоматически могут быть перенесены на другой компьютер кластера. Если в системе имеется несколько контроллеров ПУ и один из них отказывает, другие контроллеры ПУ автоматически подхватывают его работу.
Высокая пропускная способность. Ряд прикладных систем могут пользоваться возможностью параллельного выполнения заданий на нескольких компьютерах кластера.
Удобство обслуживания системы. Общие базы данных могут обслуживаться с единственного места. Прикладные программы могут инсталлироваться только однажды на общих дисках кластера и разделяться между всеми компьютерами кластера.
Расширяемость. Увеличение вычислительной мощности кластера достигается подключением к нему дополнительных VAX-компьютеров. Дополнительные накопители на магнитных дисках и магнитных лентах становятся доступными для всех компьютеров, входящих в кластер.
Работа VAX-кластера определяется двумя главными компонентами. Первым компонентом является высокоскоростной механизм связи, а вторым - системное программное обеспечение, которое обеспечивает синхронизацию работы вычислительных машин.
Синхронизация – организация действий в определенной последовательности – последовательно или параллельно.
Основные методы связи в VAX-кластере представлены на рис. 14.
Шина связи компьютеров CI (Computer Interconnect) работает со скоростью 70 Мбит/с и используется для соединения компьютеров VAX и контроллеров HSC с помощью коммутатора Star Coupler. Каждая связь CI имеет двойные избыточные линии, две для передачи и две для приема, используя базовую технологию CSMA, которая для устранения коллизий использует специфические для данного узла задержки. Максимальная длина связи CI составляет 45 метров. Звездообразный коммутатор Star Coupler может поддерживать подключение до 32 шин CI, каждая из которых предназначена для подсоединения компьютера VAX или контроллера HSC. Контроллер HSC представляет собой интеллектуальное устройство, которое управляет работой дисковых накопителей.
Компьютеры VAX могут объединяться в кластер также посредством локальной сети Ethernet, используя NI - Network Interconnect (так называемые локальные VAX-кластеры), однако производительность таких систем сравнительно низкая из-за необходимости делить пропускную способность сети Ethernet между компьютерами кластера и другими клиентами сети.
В начале 1992 года компания DEC анонсировала поддержку построения кластера на основе шины DSSI (Digital Storage System Interconnect). На шине DSSI могут объединяться до четырех компьютеров VAX нижнего и среднего класса. Каждый компьютер может поддерживать несколько адаптеров DSSI. Отдельная шина DSSI работает со скоростью 4 Мбайт/с (32 Мбит/с) и допускает подсоединение до 8 устройств. DSSI ограничивает расстояние между узлами в кластере 25 метрами.
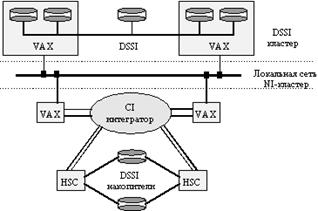
Рис. 14. Архитектура VAX-кластера
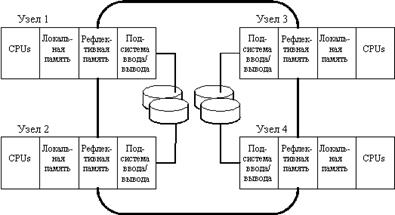
Рис. 15. Архитектура кластера компании DEC на базе рефлективной памяти и каналов “память-память”
В 1994 году компания DEC анонсировала продукт под названием Integrated Cluster Server, который по своим функциональным характеристикам соответствует стандарту VAX-кластеров. Основу этого решения составляет новая технология так называемой рефлективной памяти, имеющейся в каждом узле кластера. Устройства рефлективной памяти разных узлов кластера объединяются с помощью высокоскоростных каналов на основе интерфейса PCI (рис. 15). Обмен информацией между узлами типа “память-память” по этим каналам может производиться со скоростью 100 Мбайт/с, что на порядок превышает скорость обмена по обычным каналам ввода/вывода.
В настоящее время на смену VAX-кластерам приходят UNIX-кластеры.
4.2.2. UNIX-кластеры компании IBM
Компания IBM предлагает несколько типов слабосвязанных систем, объединенных в кластеры. В этих системах поддерживаются три режима автоматического восстановления системы после отказа:
- режим 1 – в конфигурации с двумя системами, одна из которых является основной, а другая находится в горячем резерве, в случае отказа обеспечивает автоматическое переключение с основной системы на резервную;
- режим 2 – в той же двухмашинной конфигурации позволяет резервному процессору обрабатывать некритичные приложения, выполнение которых в случае отказа основной системы можно либо прекратить совсем, либо продолжать их обработку в режиме деградации;
- режим 3 – можно действительно назвать кластерным решением, поскольку системы в этом режиме работают параллельно, разделяя доступ к логическим и физическим ресурсам пользуясь возможностями менеджера блокировок.
UNIX-кластеры компании IBM строятся на базе локальных сетей Ethernet, Token Ring или FDDI и могут быть сконфигурированы различными способами с точки зрения обеспечения повышенной надежности:
1. Горячий резерв или простое переключение в случае отказа. В этом режиме активный узел выполняет прикладные задачи, а резервный может выполнять некритичные задачи, которые могут быть остановлены в случае необходимости переключения при отказе активного узла.
2. Симметричный резерв. Аналогичен горячему резерву, но роли главного и резервного узлов не фиксированы.
3. Взаимный подхват или режим с распределением нагрузки. В этом режиме каждый узел в кластере может “подхватывать” задачи, которые выполняются на любом другом узле кластера.
4.2.3. Требования, предъявляемые к ММС
Требования начальной установки системы
Большинство систем высокой готовности требуют включения в свой состав процедур начальной установки (System Setup), обеспечивающих конфигурацию кластера для подобающего выполнения процедур переключения, необходимых в случае отказа. Пользователи могут запрограммировать “скрипты” (сценарии) начальной установки самостоятельно или попросить системного интегратора или поставщика проделать эту работу.
Время простоя при переключении системы на резервную для систем высокой готовности может меняться в диапазоне от нескольких секунд до 20-40 и более минут. Процедура переключения на резерв включает в себя следующие этапы: резервная машина обнаруживает отказ основной и затем следует предписаниям скрипта, который, вероятнее всего, включает перезапуск системы, передачу адресов пользователей, получение и запуск необходимых приложений, а также выполнение определенных шагов по обеспечению корректного состояния данных. Время восстановления зависит, главным образом, от того, насколько быстро вторая машина сможет получить и запустить приложения, а также от того, насколько быстро операционная система и приложения, такие как базы данных или мониторы транзакций, смогут получить приведенные в порядок данные.
Журнализация файловой системы
Следствием журнализации изменений файловой системы является то, что файлы всегда находятся в готовом для использования состоянии. Когда система отказывает, журнализованная файловая система гарантирует, что файлы сохранены в последнем согласованном состоянии. Это позволяет осуществлять переключение на резервную систему без какой-либо порчи данных, а также либо вообще без каких-либо потерь данных, либо с потерей только одной последней транзакции. Такой подход отличается от систем, которые осуществляют журнализацию только метаданных файловой системы - процедура, которая помогает управлять целостностью файловой системы, но не целостностью данных.
Изоляция неисправного процесса
Для активно используемых компонентов программного обеспечения, таких как файловая система, часто применяется технология изоляции неисправных процессов, гарантирующая изоляцию ошибок в одной системе и невозможность их распространения за пределы этой системы.
Требования к прикладному программному обеспечению
Первыми открытыми системами, построенными в расчете на высокую готовность, были приложения баз данных и систем коммуникаций. Базы данных высокой готовности гарантируют непрерывный доступ к информации, которая является жизненно важной для функционирования многих корпораций и стержнем сегодняшней информационной экономики. Программное обеспечение систем коммуникаций высокой готовности усиливает средства горячего резервирования систем и составляет основу для распределенных систем высокой готовности и систем, устойчивых к стихийным бедствиям.
Другие функции программного обеспечения
В современных системах все возрастающую роль играет диагностика в режиме on-line, позволяющая предвосхищать проблемы, которые могут привести к простою системы. В настоящее время она специфична для каждой системы. В будущем, возможно, диагностика станет частью распределенного управления системой.
Требования к коммуникациям
Системы высокой готовности требуют также высокой готовности коммуникаций. Чем быстрее осуществляются коммуникации между машинами, тем быстрее происходит восстановление после отказа. Некоторые конфигурации систем высокой готовности имеют дублированные коммуникационные связи. В результате связь перестает быть точкой, отказ которой может привести к выходу из строя всей системы.

