 2015-05-13
2015-05-13 2091
2091% Перед началом работы алгоритма задаются начальные
% значения параметров.
b0 = log(mean(y)/(1-mean(y))); % 1st element, function of the mean value of y's b = [b0 zeros(size(X,2)-1,1)]'; % column-vector of parameters% Итерационное вычисление параметров логистической регрессии
while 1==1 z = X*b; p = 1./(1+exp(-z)); % recover the regression w = p.*(1-p); % calculate the weights of the samples u = z + (y-p)./w; % calculate the dependent variable for this step b_old = b; % store old parameters b = inv(X'*diag(w)*X) * X' * diag(w) * u; % calculate new parameters with least squares% terminate the iterations if changes of the parameters are small if sumsqr(b - b_old) <= TolFun, break; endend Функция MatLab для логистической регрессииДля получения параметров логистической регрессии используют функцию обощенной линейной регрессионной модели
b = glmfit(X,y, distr)
Функция возвращает вектор b размером m -на-1 коэффициентов обощенной линейной регрессии для зависимой переменой y и матрицы наблюдений X, используя распределение distr . X - матрица m * n для n наблюдений. Если distr принимает значение 'binomial', то получаем логистическую регрессию. В этом случае вектор y - двоичный вектор, характеризующий успех или неудачу для каждого наблюдения. Модель сводится к линейной преобразованием
log(p/(1 – p)) = Xb,
которое называется логит-преобразованием.
2.3 Классификация на основе дерева решений
Деревья решений относятся к числу самых популярных и мощных инструментов Data Mining, позволяющих эффективно решать задачи классификации. В основе работы деревьев решений лежит процесс рекурсивного разбиения исходного множества наблюдений или объектов на подмножества, ассоциированные с классами.
Процесс конструирования дерева решений. Напомним, что рассматриваемая нами задача классификации относится к стратегии обучения с учителем, иногда называемого индуктивным обучением. В этих случаях все объекты тренировочного набора данных заранее отнесены к одному из предопределенных классов.
Алгоритмы конструирования деревьев решений состоят из этапов "построение" или "создание" дерева (tree building) и "сокращение" дерева (tree pruning). В ходе создания дерева решаются вопросы выбора критерия расщепления и остановки обучения (если это предусмотрено алгоритмом). В ходе этапа сокращения дерева решается вопрос отсечения некоторых его ветвей.
Критерий расщепления. Процесс создания дерева происходит сверху вниз, т.е. является нисходящим. В ходе процесса алгоритм должен найти такой критерий расщепления, иногда также называемый критерием разбиения, чтобы разбить множество на подмножества, которые бы ассоциировались с данным узлом проверки. Каждый узел проверки должен быть помечен определенным атрибутом. Существует правило выбора атрибута: он должен разбивать исходное множество данных таким образом, чтобы объекты подмножеств, получаемых в результате этого разбиения, являлись представителями одного класса или же были максимально приближены к такому разбиению. Последняя фраза означает, что количество объектов из других классов, так называемых "примесей", в каждом классе должно стремиться к минимуму.
Существуют различные критерии расщепления. Наиболее известные - мера энтропии и индекс Gini. Если дано множество T, включающее примеры из n классов, индекс Gini, определяется по формуле:
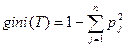 ,
, 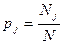 - доля класса j в узле T.
- доля класса j в узле T.
где T - текущий узел, pj - вероятность класса j в узле T, n - количество классов, N – количество объектов в узле.
Мера энтропии при построении деревьев решений – это мера разнообразия классов в узле. В результате разбиения должны образовываться узлы с меньшим разнообразием состояний входной переменной. Следовательно, энтропия падает, а количество внутренней информации в узле растет. Формально энтропия определенного узла Т дерева решений определяется:
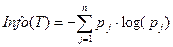 .
.
Энтропия всего разбиения – сумма энтропий всех узлов, умноженная на долю записей каждого узла в общем числе записей:
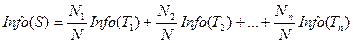 .
.
Для выбора атрибута расщепления используется критерий, называемый приростом информации или уменьшением энтропии:
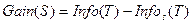 .
.
В качестве наилучшего атрибута для использования в разбиении S выбирается тот, который обеспечивает наибольший прирост информации Gain(S).
Большое дерево не означает, что оно "подходящее". Чем больше частных случаев описано в дереве решений, тем меньшее количество объектов попадает в каждый частный случай. Такие деревья называют "ветвистыми" или "кустистыми", они состоят из неоправданно большого числа узлов и ветвей, исходное множество разбивается на большое число подмножеств, состоящих из очень малого числа объектов. В результате "переполнения" таких деревьев их способность к обобщению уменьшается, и построенные модели не могут давать верные ответы.
В процессе построения дерева, чтобы его размеры не стали чрезмерно большими, используют специальные процедуры, которые позволяют создавать оптимальные деревья, так называемые деревья "подходящих размеров" (Breiman,1984).
Какой размер дерева может считаться оптимальным? Дерево должно быть достаточно сложным, чтобы учитывать информацию из исследуемого набора данных, но одновременно оно должно быть достаточно простым. Другими словами, дерево должно использовать информацию, улучшающую качество модели, и игнорировать ту информацию, которая ее не улучшает.
Тут существует две возможные стратегии. Первая состоит в наращивании дерева до определенного размера в соответствии с параметрами, заданными пользователем.
Определение этих параметров может основываться на опыте и интуиции аналитика, а также на некоторых "диагностических сообщениях" системы, конструирующей дерево решений.
Вторая стратегия состоит в использовании набора процедур, определяющих "подходящий размер" дерева, они разработаны Бриманом, Куилендом и др. в 1984 году. Однако, как отмечают авторы, нельзя сказать, что эти процедуры доступны начинающему пользователю.
Процедуры, которые используют для предотвращения создания чрезмерно больших деревьев, включают: сокращение дерева путем отсечения ветвей; использование правил остановки обучения.
Следует отметить, что не все алгоритмы при конструировании дерева работают по одной схеме. Некоторые алгоритмы включают два отдельных последовательных этапа: построение дерева и его сокращение; другие чередуют эти этапы в процессе своей работы для предотвращения наращивания внутренних узлов.
Остановка построения дерева. Рассмотрим правило остановки. Оно должно определить, является ли рассматриваемый узел внутренним узлом, при этом он будет разбиваться дальше, или же он является конечным узлом, т.е. узлом решением.
Остановка - такой момент в процессе построения дерева, когда следует прекратить дальнейшие ветвления.
Один из вариантов правил остановки - "ранняя остановка" (prepruning), она определяет целесообразность разбиения узла. Преимущество использования такого варианта - уменьшение времени на обучение модели. Однако здесь возникает риск снижения точности классификации. Поэтому рекомендуется "вместо остановки использовать отсечение" (Breiman, 1984).
Второй вариант остановки обучения - ограничение глубины дерева. В этом случае построение заканчивается, если достигнута заданная глубина.
Еще один вариант остановки - задание минимального количества примеров, которые будут содержаться в конечных узлах дерева. При этом варианте ветвления продолжаются до того момента, пока все конечные узлы дерева не будут чистыми или будут содержать не более чем заданное число объектов.
Сокращение дерева или отсечение ветвей. Решением проблемы слишком ветвистого дерева является его сокращение путем отсечения (pruning) некоторых ветвей.
Качество классификационной модели, построенной при помощи дерева решений, характеризуется двумя основными признаками: точностью распознавания и ошибкой.
Точность распознавания рассчитывается как отношение объектов, правильно классифицированных в процессе обучения, к общему количеству объектов набора данных, которые принимали участие в обучении.
Ошибка рассчитывается как отношение объектов, неправильно классифицированных в процессе обучения, к общему количеству объектов набора данных, которые принимали участие в обучении.
Отсечение ветвей или замену некоторых ветвей поддеревом следует проводить там, где эта процедура не приводит к возрастанию ошибки. Процесс проходит снизу вверх, т.е. является восходящим. Это более популярная процедура, чем использование правил остановки. Деревья, получаемые после отсечения некоторых ветвей, называют усеченными.
Если такое усеченное дерево все еще не является интуитивным и сложно для понимания, используют извлечение правил, которые объединяют в наборы для описания классов. Каждый путь от корня дерева до его вершины или листа дает одно правило. Условиями правила являются проверки на внутренних узлах дерева.
Алгоритмы. На сегодняшний день существует большое число алгоритмов, реализующих деревья решений: CART, C4.5, CHAID, CN2, NewId, ITrule и другие.
Алгоритм C 4.5. Алгоритм C4.5 строит дерево решений с неограниченным количеством ветвей у узла. Данный алгоритм может работать только с дискретным зависимым атрибутом и поэтому может решать только задачи классификации. C4.5 считается одним из самых известных и широко используемых алгоритмов построения деревьев классификации.
Для работы алгоритма C4.5 необходимо соблюдение следующих требований:
· каждая запись набора данных должна быть ассоциирована с одним из предопределенных классов, т.е. один из атрибутов набора данных должен являться меткой класса;
· классы должны быть дискретными. Каждый пример должен однозначно относиться к одному из классов;
· количество классов должно быть значительно меньше количества записей в исследуемом наборе данных.
Последняя версия алгоритма - алгоритм C4.8 - реализована в инструменте Weka как J4.8 (Java). Коммерческая реализация метода: C5.0, разработчик RuleQuest, Австралия.
Алгоритм C4.5 медленно работает на сверхбольших и зашумленных наборах данных.
Оба алгоритма являются робастными, т.е. устойчивыми к шумам и выбросам данных.
Алгоритмы построения деревьев решений различаются следующими характеристиками:
• вид расщепления - бинарное (binary), множественное (multi-way);
• критерии расщепления - энтропия, Gini, другие;
• возможность обработки пропущенных значений;
• процедура сокращения ветвей или отсечения;
• возможности извлечения правил из деревьев.
Ни один алгоритм построения дерева нельзя априори считать наилучшим или совершенным, подтверждение целесообразности использования конкретного алгоритма должно быть проверено и подтверждено экспериментом.

