 2015-07-14
2015-07-14 2920
2920Введение
Анализ различных видов информационных технологий позволяет выявить наиболее часто встречающиеся при обработке данных алгоритмы, использующие основные алгоритмические структуры. Эти алгоритмы обработки данных названы производными алгоритмическими структурами.
Каждая производная алгоритмическая структура обладает свойствами стандартного алгоритма:
– имеет один вход;
– имеет один выход;
– не имеет бесконечных циклов;
– не содержит бесполезных (недостижимых в процессе выполнения) блоков;
– имеет определённое функциональное назначение.
Такие алгоритмы, построенные на основе принципов структурного программирования, обладают большими функциональными возможностями по сравнению с основными алгоритмическими структурами и, следовательно, при их использовании упрощается процесс конструирования сложных алгоритмов.
При обработке массивов и баз данных используются производные алгоритмические структуры, которые отображают следующие вычислительные процессы:
Заполнение – для заполнения вычислительной среды конкретными данными. Этот процесс может быть представлен двумя структурами – Формирование и Пересчёт,– каждая из которых имеет свои особенности заполнения вычислительной среды и поэтому выделена в самостоятельную структуру.
Поиск – для поиска данных, имеющих максимальное или минимальное значение, а также данных, зависящих от значения ключа поиска.
Ключом поиска называется переменная, значение которой заранее (до работы алгоритма) определяется пользователем информационной технологии.
Так как каждый из перечисленных процессов поиска имеет свои особенности, то различают три структуры – Поиск максимума, Поиск минимума, Поиск по ключу.
Накопление – для накопления сумм и произведений. Здесь различают три структуры: Сумма, Произведение, Счётчик.
Использование основных и производных алгоритмических структур позволяет реализовать на практике структурный подход к программированию, в основе которого лежат принципы модульного программирования и нисходящего проектирования алгоритмов.
Массивы данных
Массив – это совокупность структурированных данных одного типа, расположенных в вычислительной среде последовательно друг за другом и обозначенных одним именем. Различают одно-, двух-, трёхмерные и т.д. массивы.
В одномерных массивах данные располагаются последовательно друг за другом. Одномерные массивы соответствуют математическому понятию вектор и обозначаются следующим образом:
A = [ai], 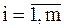 ,
,
где А – имя массива;
ai – элемент массива;
m – размерность массива;
i – индекс, определяющий местоположение элемента в массиве.
Правомерна и такая запись массива:
А={a1, a2, a3,…ai,…am},
где а1 – первый элемент массива;
а i – i-й элемент массива;
аm – последний элемент массива.
Двухмерный массив соответствует математическому понятию матрица, имеющей m строк и n столбцов. Элементы двухмерного массива располагаются в вычислительной среде следующим образом: элементы первой строки матрицы – их количество равно n, затем элементы второй строки матрицы – их количество также равно n и т.д.
Двухмерные массивы обозначаются следующим образом:
A = [aij]; ; 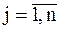 ,
,
где А – имя массива;
aij – элемент массива;
i – индекс, определяющий номер строки;
j – индекс, определяющий номер столбца;
m´n – размерность массива;
m – количество строк;
n – количество столбцов.
Правомерна и такая форма записи массива:
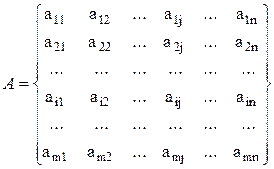
Матрица называется квадратной, если m = n, в остальных случаях матрица называется прямоугольной.
Квадратная матрица имеет следующие свойства:
– одинаковое количество строк и столбцов (m = n);
– индексы элементов, расположенных на главной диагонали, равны (значение индекса i равно значению индекса j).
В любой системе программирования массивы должны быть объявлены.

