 2015-08-21
2015-08-21 1289
1289В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева).
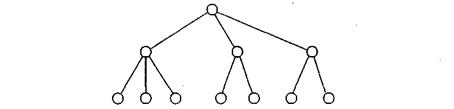 Рис.2. Иерархическая модель
Рис.2. Иерархическая модель
Для описания структуры (схемы) иерархической БД на некотором языке программирования используется тип данных «дерево». Тип «дерево» является составным. Он включает в себя подтипы («поддеревья»), каждый из которых, в свою очередь, является типом «дерево». Каждый из типов «дерево» состоит из одного «корневого» типа и упорядоченного набора (возможно, пустого) подчиненных типов. Каждый из элементарных типов, включенных в тип «дерево», является простым или составным типом «запись».
Корневым называется тип, который имеет подчиненные типы и сам не является подтипом. Подчиненный тип (подтип) является потомком по отношению к типу, который выступает для него в роли предка (родителя). Потомки одного и того же типа являются близнецами по отношению друг к другу.
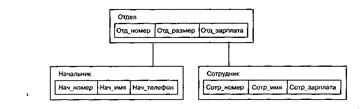 |
Рис. 3. Пример типа «дерево»
В целом тип «дерево» представляет собой иерархически организованный набор типов «запись».
Иерархическая БД представляет собой упорядоченную совокупность экземпляров данных типа «дерево» (деревьев), содержащих экземпляры типа «запись» (записи). Поля записей хранят собственно числовые или символьные значения, составляющие основное содержание БД. Данные в базе с приведенной схемой (рис. 3) могут выглядеть, например, как показано на рис.4.
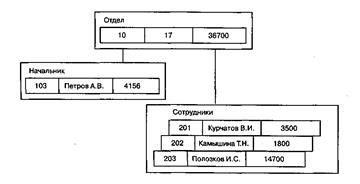
Рис. 4. Данные в иерархической базе
Основные операции манипулирования иерархически организованных данных:
- поиск указанного экземпляра БД (например, дерева со значением 10 в поле Отд_номер);
- переход от одного дерева к другому;
- переход от одной записи к другой внутри дерева (например, к следующей записи типа «Сотрудники»);
- вставка новой записи в указанную позицию;
- удаление текущей записи и т. д.
К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией.
Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя.
На иерархической модели данных основано сравнительно ограниченное количество СУБД, в числе которых можно назвать зарубежные системы IMS, PC/Focus, Team-Up и Data Edge, а также отечественные системы Ока, ИНЭС и МИРИС.

