2015-10-22
2015-10-22 3925
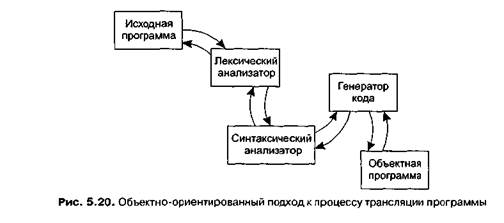
3925Процесс преобразования программы с одного языка на другой называется трансляцией программы (translation). Программа в первоначальной форме называется исходной программой (source program); преобразованная программа называется объектной (object program). Процесс трансляции включает в себя три стадии: лексический анализ, синтаксический анализ и генерация объектного кода. Эти стадии выполняются элементами транслирующей программы, которые называются лексическим анализатором (lexical analyzer), синтаксическим анализатором (parser) и генератор объектного кода (code generator) (рис. 5.15).

В процессе лексического анализа распознаются цепочки символов, которые представляют собой отдельные элементы, Например, три символа 153 интерпретируются программой не как три отдельных числа, а как одно. Точно так же слово, которое встречается в программе, хотя и состоит из отдельных букв, распознается как целый элемент. Для большинства людей лексический анализ не представляет особой трудности. Когда нас просят прочитать что-либо вслух, мы произносим слова, а не отдельные символы.
Таким образом, лексический анализатор символ за символом считывает исходную программу, определяет, какие группы символов представляют собой отдельные элементы, и классифицирует эти элементы согласно тому, являются ли они числовыми значениями, словами, арифметическими операторами и т. д. По мере классификации элементов лексический анализатор порождает цепочки битов, которые называются лексемами (tokens), и передает их синтаксическому анализатору. При этом лексический анализатор пропускает все комментарии.
Синтаксический анализатор рассматривает программу как совокупность лексических единиц (лексем), а не отдельных символов. Его задача состоит в том, чтобы сгруппировать эти элементы в отдельные высказывания. Синтаксический анализ представляет собой процесс определения грамматической структуры программы и роли каждого ее компонента. Эта техническая сторона анализа может вызвать задержку при чтении следующего предложения:
Человек, которого лошадь, проигравшая скачки, сбросила, не был ранен.
Для упрощения процесса синтаксического анализа в ранних языках программирования каждый оператор программы располагался в определенном месте листа. Такие языки называются языками с фиксированным форматом (fixed-format languages). Сейчас большинство языков программирования являются языками с произвольным форматом, то есть в них положение оператора не является существенным. Преимущество таких языков программирования состоит в том, что программист имеет возможность располагать записанную программу так, чтобы се было легче читать человеку. В этом случае принято использовать отступы, чтобы читателю было проще понять структуру оператора. Вместо того чтобы записать
if Cost < CashOnHand then заплатить наличными else использовать кредитную карту программист может записать
if Cost < CashOnHand
then заплатить наличными
else использовать кредитную карту
Для того чтобы машина могла обработать программу, написанную на языке с произвольным форматированием, синтаксис языка должен быть таким, что определение структуры программы не зависит от количества пробелов, используемых в исходной программе. С этой целью в большинстве языков программирования для обозначения конца высказывания используются пунктуационные знаки, например точка с запятой, и ключевые слова (key words), такие как if, then и else, для обозначения начала отдельных конструкций. Такие ключевые слойа часто называют зарезервированными словами (reserved words), поскольку программист не может использовать их в программе для каких-либо других целей.
Реализация java
В случае веб-страниц с анимацией программное обеспечение, которое управляет анимацией, передается по Интернету вместе со страницей. Если это программное обеспечение поставляется в форме исходной программы, то при просмотре страницы возникнут трудности, поскольку это программное обеспечение нужно преобразовать в машинный язык. Однако если записывать эти программы на машинном языке, то придется создавать разные версии страницы в зависимости от машинного языка, используемого в машине, пытающейся получить доступ к странице.
Компания Sun Microsystems решила эту проблему, создав универсальный «машинный язык», который называется байт-кодом. В этот код преобразуются все исходные программы, написанные на языке Java. Хотя байт-код — не совсем машинный язык, его может быстро выполнить любая машина с помощью соответствующей интерпретирующей программы. Сегодня такие интерпретирующие программы становятся частью программ браузера. Таким образом, если программное обеспечение, управляющее веб-страницей, написано на Java и преобразовано в байт-код, то этот код можно передать браузеру для более эффективного отображения анимации.
В основе процесса синтаксического анализа лежит набор синтаксических правил, которые определяют синтаксис языка программирования. Одним из способов представления этих правил является синтаксическая диаграмма (syntax diagram), то есть графическое изображение грамматической структуры программы. Синтаксическая диаграмма оператора if-then-else представлена на рис. 5.16. Она показывает, что структура if-then-else начинается со слова if, за ним следует Логическое выражение, слово then и Высказывание. После этой комбинации может находиться слово else и Высказывание. Обратите внимание на то, что элементы, которые действительно присутствуют в операторе if-then-else, заключены в овалы, а элементы, которые требуют дальнейшего описания, такие как Логическое выражение и Высказывание, заключены в прямоугольники. Элементы, требующие дальнейшего описания (в прямоугольниках), называются нетерминальными (nonterminals); элементы в овалах, называются терминальными (terminals).
В полном описании синтаксиса языка нетерминальные элементы определяются с помощью дополнительных диаграмм.

В качестве более сложного примера приведем несколько синтаксических диаграмм, описывающих синтаксис структуры Выражение, которая является простым арифметическим выражением (рис. 5.17). На первой диаграмме Выражение состоит из Элемента, за которым может следовать символ + или - и другое Выражение. Вторая диаграмма описывает Элемент, состоящий либо из одного Множителя, либо из Множителя, символов х или -5- и другого Элемента. И наконец, последняя диаграмма описывает Множитель, который является одним из символов х, у или z.

Отдельное арифметическое выражение можно представить с помощью дерева синтаксического анализа (parse tree). Дерево синтаксического анализа (рис. 5.18) для цепочки х + у х z
строится на базе синтаксических диаграмм (см. рис. 5.17). Обратите внимание на то, что в основании дерева находится нетерминальный элемент Выражение, и на каждом последующем уровне нетерминальные элементы разбиваются на составные части до тех пор, пока не будут получены символы цепочки. В частности, дерево
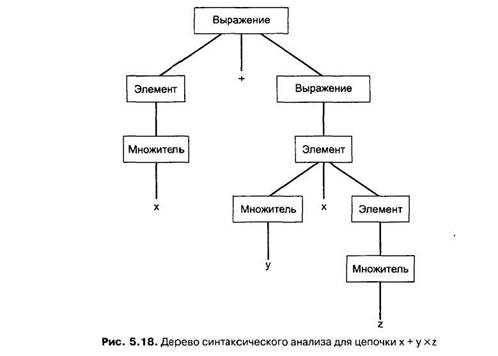
показывает, что цепочка к + у х z состоит из Элемента, который является Множителем х, символа + и Выражения, которое является Элементом у х г.
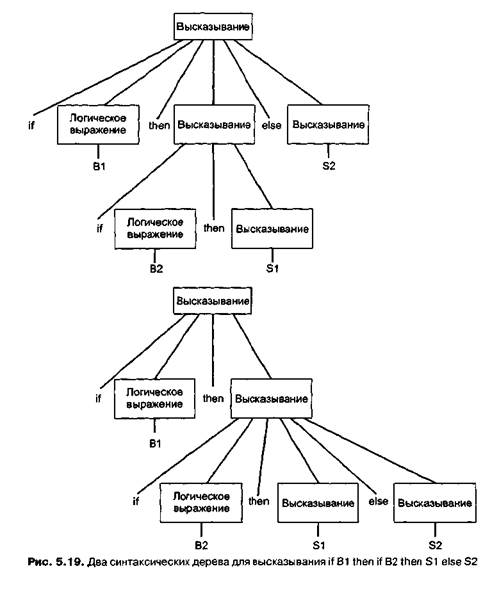
Процесс синтаксического анализа программы, в сущности, представляет собой построение дерева синтаксического анализа для исходного кода. Синтаксическое дерево отражает то, как синтаксический анализатор понимает грамматическое строение программы. Поэтому синтаксические правила, описывающие грамматическую структуру программы, должны исключать возможность построения двух синтаксических деревьев для одной цепочки, поскольку это приведет к неоднозначности. Ошибки такого рода трудно заметить. Например, диаграмма на рис. 5.16 содержит означенный дефект. Она позволяет построить два синтаксических дерева (рис. 5.19) для одного высказывания if Bl then if В2 then SI else S2
Обратите внимание на то, что эти деревья принципиально отличаются. Первое дерево предполагает, что выражение S2 выполняется, если условие В1 ложно; второе означает, что S2 выполняется, только если условие В1 истинно, а условие В2 ложно.
Синтаксические определения формальных языков программирования создаются так, чтобы избежать неоднозначности. В нашем псевдокоде для этого мы использовали скобки. Например, для того чтобы различать два возможных способа интерпретации приведенного выше выражения, можно записать:
if Bl
then (if B2 then SI)
else S2
и
if Bl
then (if B2 then SI else S2)
Когда синтаксический анализатор обрабатывает операторы описания, он записывает содержащуюся в них информацию в таблицу, которая называется таблицей имен (symbol table). Таблица имен содержит информацию о том, какие переменные объявлены в программе и какие типы данных или структур данных поставлены им в соответствие. С помощью этой информации синтаксический анализатор обрабатывает исполняемые операторы, такие как
Z <- X + Y;
Для того чтобы определить значение символа +, анализатору необходимо знать тип данных переменных X и Y. Если X — вещественная переменная, a Y — сим-иол, тогда их сложение просто бессмысленно, и следует сообщить об ошибке. 1хли X и Y — целочисленные переменные, тогда анализатор предпишет генератору кода создать команду машинного языка с кодом операции сложения двух целых чисел. Если оба слагаемых являются переменными вещественного типа, то генератор кода будет использовать код операции для сложения с плавающей точкой.
Приведенный выше оператор может включать в себя переменные разных типов. Например, если X — целочисленная переменная, a Y — вещественная, то операцию сложения все-таки можно выполнить. В таком случае генератор кода создает команду преобразования типа одного из значений, а затем выполняет сложение. Такое преобразование типа значения называется приведением типов (coercion).
Многие разработчики языков неодобрительно относятся к приведению типов. Они утверждают, что необходимость приведения типов свидетельствует о наличии недостатков в строении программы, и, следовательно, анализатор не должен предоставлять такую операцию. В результате большинство современных языков программирования являются языками со строгим контролем типов (strongly typed), то есть все операции, выполняемые программой, должны включать данные совместимых типов. Синтаксические анализаторы этих языков при возникновении конфликта типов всегда сообщают об ошибке.
Последняя стадия процесса трансляции программы — это генерация кода, то есть создание команд машинного языка, выполняющих выражения, распознанные синтаксическим анализатором. Во время генерации кода возникает множество трудностей, и одна нз них — это создание эффективного кода. Рассмотрим, например, трансляцию последовательности двух операторов
х <- у + z; w <— х + z;
Можно рассматривать эти операторы независимо друг от друга. Однако в этом случае мы не получим эффективного кода. Генератор кода должен распознать, что после выполнения первого оператора значения х и z уже будут находиться в регистрах центрального процессора, и, следовательно, их не нужно повторно загружать из памяти перед выполнением второго оператора. Этот процесс называется оптимизацией программы (code optimization) и является важной задачей генератора кода.
Лексический и синтаксический анализ и генерация кода не выполняются строго друг за другом. Вместо этого все эти процессы протекают одновременно. Лексический анализатор считывает первые символы и определяет первую лексему. Затем он передает эту лексему синтаксическому анализатору. Каждый раз, когда синтаксический анализатор получает лексему, он обрабатывает считываемую грамматическую конструкцию. На данном этапе он либо запрашивает у лексического анализатора еще одну лексему, либо, если он распознает оператор, вызывает генератор кода, чтобы тот создал последовательность соответствующих машинных команд. Затем эти машинные команды добавляются к объектной программе. Трансляция программы соответствует объектно-ориентированной парадигме программирования. Исходная программа, лексический анализатор, синтаксический анализатор, генератор кода и объектная программа являются объектами, которые взаимодействуют между собой, обмениваясь сообщениями, когда какой-либо из объектов приступает к выполнению своей задачи (рис. 5.20).