 2015-05-10
2015-05-10 3014
3014Лабораторная работа № 4
МОДУЛЬ Basic Statistics / Tables
ПЕРВИЧНАЯ ОБРАБОТКА ОПЫТНЫХ ДАННЫХ
ВВЕДЕНИЕ
Расчет описательных статистик производится при помощи модуля Basic Statistic/Tables. В этом модуле объединены наиболее часто используемые на начальном этапе обработки данных процедуры.
В стартовой панели модуля приводится перечень статистических процедур этого модуля (рис. 1):
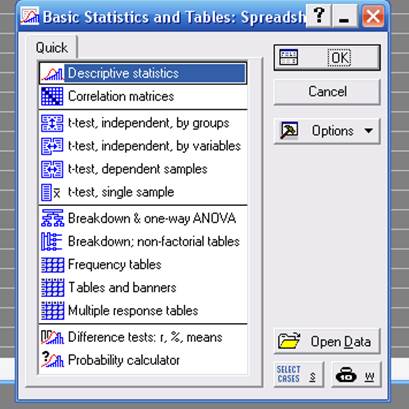
Рисунок - 1. Стартовое окно модуляBasic Statistic and Tables
с перечнем доступных статистических процедур:
Descriptive statistics - Описательные статистики;
Correlation matrices - Корреляционные матрицы;
t-test for independent samples - t-тест для независимых выборок;
t-test for dependent samples - t-тест для зависимых выборок;
Breakdown & one-way ANOVA - Классификация и однофакторный дисперсионный анализ данных;
и др.
Процедура Descriptive statistics (Описательные статистики)
Для начала работы в данном модуле необходимо создать или выбрать файл для анализа. Рассмотрим возможности этой процедуры на примере, приведенном в приложении 1. Имеется выборка объемом 50 измерений, представляющая собой результаты обмера 1-летних сеянцев сосны. Файл данных содержит 4 переменных:
VAR1 - длина надземной части сеянцев, см;
VAR2 - диаметр у корневой шейки, мм;
VAR3 - длина корней, см;
VAR4 - длина хвои, см;
После выбора процедуры Descriptive statistics на экране появится одноименное диалоговое окно (рис. 2).
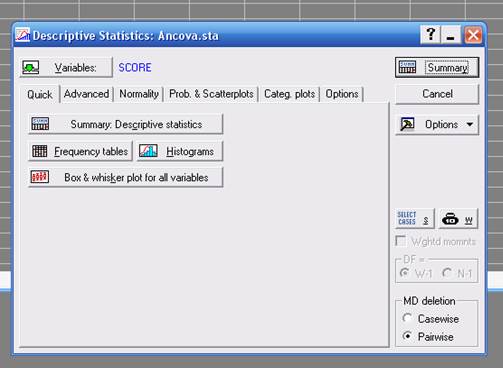
Рис. 2. Диалоговое окно "Descriptive statistics. Кнопки:
Variables – выбор переменных для анализа,
Quick – процедура первичного ускоренного анализа данных с вычислением минимального количества статистик и построением статистических графиков,
Advanced – процедура задания статистик и их вычисления,
Normality – процедура проверки нормального закона распределения выбранной переменной,
Prob.&Scatterplots – визуализация связей между двумя и более переменными,
Categ. Plots – дополнительные опции визуализации данных анализа,
Options – устанавливает дополнительные опции для расчета описательных статистик.
Рассмотрим содержание кнопок более подробно.
Переменные для анализа следует выбрать при помощи кнопки Variables (рис. 3);
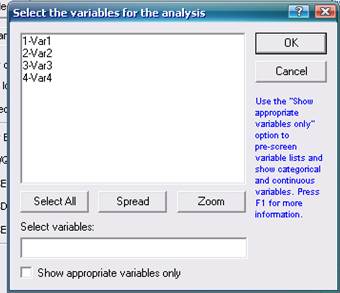
Рис. 3. Окно выбора переменных
Кнопка Select all выбирает все переменные для анализа из предлагаемого списка переменных. Кнопка Spread/Shrink позволяет вместо номеров переменных указать их полные имена. Кнопка Zoom позволяет открыть окно Values/Stats, в котором доступна информация по первой переменной из выбранного списка переменных (имя, объём данных для анализа, формат записи данных, числовые значения переменной, среднее, стандарт). Закладка Show appropriate variables only позволяет сделать доступным сортировку переменных (рис. 3).
Модуль Descriptive statistics позволяет проводить анализ данных любой сложности с представлением результатов в любой форме.
Кнопка Advanced открывает диалоговое окно (рис. 4), позволяющее запустить процедуру задания статистик и их вычисления.
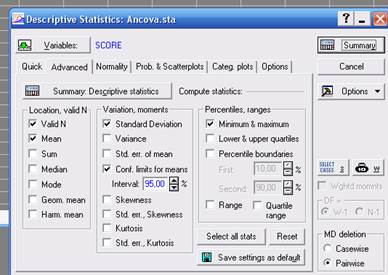
Рисунок 4. диалоговое окно при нажатой кнопке Advanced
Valid N - объем выборки;
Mean - средняя арифметическая;
Среднее значение случайной величины представляет собой наиболее типичное, наиболее вероятное ее значение, своеобразный центр, вокруг которого разбросаны все значения признака.
Sum - сумма;
Median - медиана;
Медианой является такое значение случайной величины, которое разделяет все случаи выборки на две равные по численности части.
Standard Deviation - стандартное отклонение;
Стандартное отклонение (или среднее квадратическое отклонение) является мерой изменчивости (вариации) признака. Оно показывает на какую величину в среднем отклоняются случаи от среднего значения признака. Особенно большое значение имеет при исследовании нормальных распределений. В нормальном распределении 68% всех случаев лежит в интервале + одного отклонения от среднего, 95% - + двух стандартных отклонений от среднего и 99,7% всех случаев - в интервале + трех стандартных отклонений от среднего.
Variance - дисперсия;
Дисперсия является мерой изменчивости, вариации признака и представляет собой средний квадрат отклонений случаев от среднего значения признака. В отличии от других показателей вариации дисперсия может быть разложена на составные части, что позволяет тем самым оценить влияние различных факторов на вариацию признака. Дисперсия - один из существеннейших показателей, характеризующих явление или процесс, один из основных критериев возможности создания достаточно точных моделей.
Standard error of mean - стандартная ошибка среднего;
Стандартная ошибка среднего это величина, на которую отличается среднее значение выборки от среднего значения генеральной совокупности при условии, что распределение близко к нормальному. С вероятностью 0,68 можно утверждать, что среднее значение генеральной совокупности лежит в интервале + одной стандартной ошибки от среднего, с вероятностью 0,95 - в интервале + двух стандартных ошибок от среднего и с вероятностью 0,99 - среднее значение генеральной совокупности лежит в интервале + трех стандартных ошибок от среднего.
95% confidence limits of mean - 95%-ый доверительный интервал для среднего;
Интервал, в который с вероятностью 0,95 попадает среднее значение признака генеральной совокупности.
Minimum, maximum - минимальное и максимальное значения;
Lower, upper quartiles - нижний и верхний квартили;
Верхний квартиль это такое значение случайной величины, больше которого по величине 25% случаев выборки. Верхний квартиль это такое значение случайной величины, меньше которого по величине 25% случаев выборки.
Range - размах;
Расстояние между наибольшим (maximum) и наименьшим (minimum) значениями признака.
Quartile range - интерквартильная широта;
Расстояние между нижним и верхним квартилями.
Skewness -асимметрия;
Асимметрия характеризует степень смещения вариационного ряда относительно среднего значения по величине и направлению. В симметричной кривой коэффициент асимметрии равен нулю. Если правая ветвь кривой, начиная от вершины) больше левой (правосторонняя асимметрия), то коэффициент асимметрии больше нуля. Если левая ветвь кривой больше правой (левосторонняя асимметрия), то коэффициент асимметрии меньше нуля. Асимметрия менее 0,5 считается малой.
Standard error of Skewness -стандартная ошибка асимметрии;
Kurtosis - эксцесс;
Эксцесс характеризует степень концентрации случаев вокруг среднего значения и является своеобразной мерой крутости кривой. В кривой нормального распределения эксцесс равен нулю. Если эксцесс больше нуля, то кривая распределения характеризуется островершинностью, т.е. является более крутой по сравнению с нормальной, а случаи более густо группируются вокруг среднего. При отрицательном эксцессе кривая является более плосковершинной, т.е. более пологой по сравнению с нормальным распределением. Отрицательным пределом величины эксцесса является число -2, положительного предела - нет.
Standard error of Kurtosis - стандартная ошибка эксцесса.
На против статистик, подлежащих вычислению (рис. 4) следует поставить флажок.
После нажатия на кнопку OK окна Descriptive statistics на экране появится таблица с результатами расчетов описательных статистик (рис. 5).
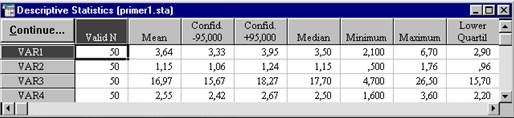
Рисунок- 5. Окно с результатами расчета описательных статистик
На первом этапе обработки данных часто возникает необходимость в их группировке. Кнопка Normality позволяет выполнить эту процедуру. Группировка позволяет представить первичные данные в компактном виде, выявить закономерности варьирования изучаемого признака. Количество классов можно приблизительно наметить, пользуясь следующими придержками (Лакин, 1990): при количестве наблюдений 25…40 - 5-6 классов, при количестве наблюдений 40…60 - 6-8 классов, 60…100 - 7-10, 100…200 наблюдений - 8-12, более 200 наблюдений - 10-15 классов (рис. 6).
 Рисунок - 6
Рисунок - 6
Для построения гистограмм и таблиц частот используется также кнопка Normality окна Descriptive statistics. Число классов (интервалов) группировки данных устанавливается при помощи счетчика переключателя Number of intervals окна Descriptive statistics (в подразделе Categorization (Группировка) раздела Distribution). Данная процедура позволяет задать число интервалов группировки или установить величину интервала равную целому числу. Если заактивировать переключатель Integer intervals (categories), то классы (интервалы) группировки будут представлять из себя целые числа.
Результаты группировки длины сеянцев (переменная Var1) представлены в табл. 1.
Таблица 1
Результаты группировки замеров высот
| Cumul. | Percent | Cumul % | % of all | ||
| Интервал | Count | Count | of Valid | of Valid | Cases |
| длин, м | (ко-во) | (ко-во с накоплением) | (%) | (% с накоплением) | (% от общего ко-ва) |
| 1,0 < x <= 2,0 | |||||
| 2,0 < x <= 3,0 | |||||
| 3,0< x <= 4,0 | |||||
| 4,0 < x <= 5,0 | |||||
| 5,0< x <= 6,0 | |||||
| 6,0 < x <= 7,0 |
В этом же разделе находятся кнопки, позволяющие представить распределение переменных на гистограммах. Для этого предназначена кнопка Histograms.
На гистограмму при необходимости можно наложить плотность нормального распределения, проверить близость распределения к нормальному виду при помощи критериев Колмогорова-Смирнова, Лилиефорса; вычислить статистику Шапиро-Уилкса. Для этого в группе опций Distribution необходимо установить флажок напротив соответствующих статистик. Значения статистик показываются прямо на гистограммах (рис. 7).
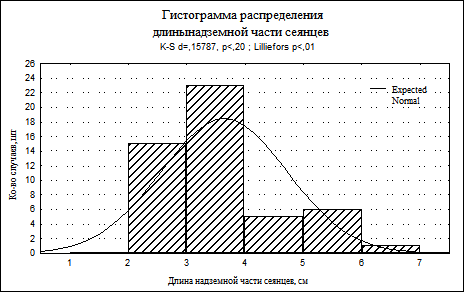
Рисунок - 7. Гистограмма распределения длины надземной части сеянцев
На гистограмме показана кривая плотности нормального распределения, а также критерий Колмогорова-Смирнова (d). Статистика Колмогорова-Смирнова оказалась равной 0,157. Чем меньше величина этой статистики, тем ближе распределение случайной величины к нормальному. Вероятность нулевой гипотезы (р) менее 0,20.
Кнопка Prob.&Scatterplots – визуализация связей между двумя и более переменными.
О нормальности распределения можно судить по графику на нормальной вероятностой бумаге. Его легко построить при помощи опции Normal probability plots окна "Descriptive statistics" (рис.8).
Рисунок – 8.
Чем ближе распределение к нормальному виду, тем лучше значения ложатся на прямую линию (рис. 9). Этот метод оценки является фактически глазомерным. В сомнительных случаях проверку на нормальность можно продолжить с использованием специальных статистических критериев (Колмогорова-Смирнова, Омега-квадрат (ω2)). Однако детальная проверка гипотезы о нормальности выборки требует довольно значительных объемов выборки (по мнению некоторых авторов не менее 100 наблюдений).
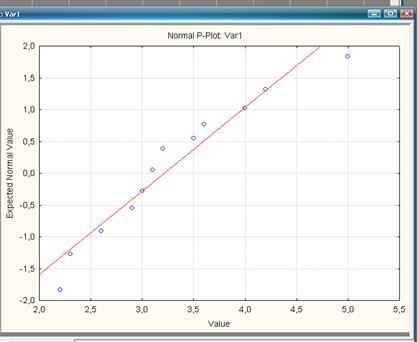
Рис. 9. График на нормальной вероятностной бумаге для
выборки длин надземной части сеянцев
К сожалению, пакет Statistica не рассчитывает такие часто применяемые статистики, как коэффициент вариации и относительная ошибка среднего значения (точность опыта). Но их определение не представляет большого труда. Коэффициент вариации (%) есть отношение стандартного отклонения к среднему значению, умноженное на 100%:
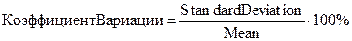 |
Коэффициент вариации, как дисперсия и стандартное отклонение, является показателем изменчивости признака. Коэффициент вариации не зависит от единиц измерения, поэтому удобен для сравнительной оценки различных статистических совокупностей. При величине коэффициента вариации до 10% изменчивость оценивается как слабая, 11-25% - средняя, более 25% - сильная (Лакин, 1990).
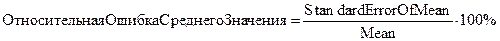 |
Относительная ошибка среднего значения (%) - отношение стандартной ошибки среднего к среднему значению, умноженное на 100% (для вероятности 0,68):
Это процент расхождения между генеральной и выборочной средней, показывает на сколько процентов можно ошибиться, если утверждать, что генеральная средняя равна выборочной средней. Если относительная ошибка не превышает 5%, то точность исследований (точность опыта) оценивается как хорошая, до 10% - удовлетворительная.
Точность 3-5% при вероятности 0,95, а в некоторых случаях и при вероятности 0,68, является вполне достаточной для большинства задач лесного хозяйства.
При необходимости обработки сгруппированных данных нужно воспользоваться кнопкой Weight окна Descriptive statistics. В появляющемся диалоговом окне следует указать переменную, являющуюся весами для других переменных (Weight variables), а переключатель Status установить в положение ON. Необходимо иметь в виду, что весы действуют сразу для всех переменных. Поэтому обрабатывать сгруппированные и не сгруппированные данные нужно отдельно.
При помощи опции Alpha error выбирается уровень доверительной вероятности статистического анализа. В большинстве исследований наиболее часто используется вероятность 0,95 (95%). Вероятности 0,95 соответствует уровень значимости 0,05 (5%).
Кнопка Select cases позволяет установить условия включения (include if) или исключения (exclude if) случаев (строк файла данных) из статистической обработки. Операторы, которые могут использоваться при написании выражений, а также примеры самих выражений имеются непосредственно на самом диалоговом окне Case Selection Conditions в нижней его части (рис. 10).
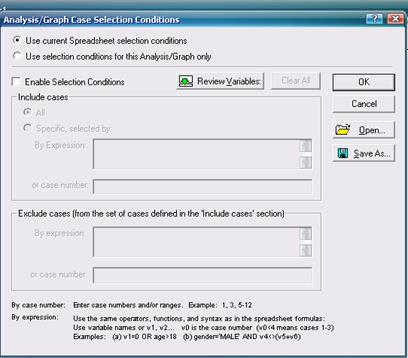
Рисунок – 10 Диалоговое окно Case Selection Conditions
Для визуализации описательных статистик можно построить статистические графики типа "коробок" (или "ящиков с усами"). Это легко можно сделать при помощи кнопки Box & Whisker plot for all variable окна Descriptive statistics. При выполнении процедур под кнопкой Quick. «Коробка» указывает на положение квартилей, медианы, минимума и максимума.
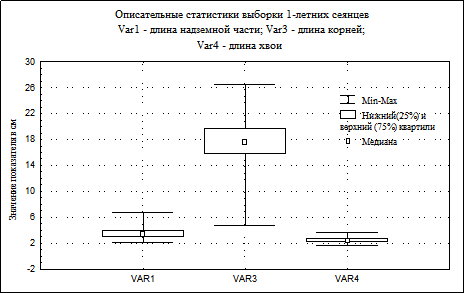 |
Визуализация описательных статистик переменных VAR1, VAR3 и VAR4 рассматриваемого примера при помощи графика коробок представлена на рис. 11.
Рисунок - 11 Описательные статистики в графическом виде
Приложение 1
Выборка объемом 50 измерений, представляющая собой результаты обмера 1-летних сеянцев сосны. Файл данных содержит 4 переменных:
VAR1 - длина надземной части сеянцев, см;
VAR2 - диаметр у корневой шейки, мм;
VAR3 - длина корней, см;
VAR4 - длина хвои, см;
| 3,6 | 1,33 | 20,5 | 3,1 |
| 2,3 | 19,5 | 2,5 | |
| 2,9 | 1,54 | 14,2 | 2,6 |
| 2,6 | 1,1 | 14,9 | 2,5 |
| 3,1 | 1,45 | 14,5 | 2,6 |
| 3,2 | 1,33 | 15,8 | 2,5 |
| 3,5 | 1,25 | 11,4 | 2,8 |
| 4,2 | 1,65 | 17,6 | 3,3 |
| 1,42 | 19,4 | 2,6 | |
| 1,36 | 21,4 | 2,7 | |
| 3,1 | 1,2 | 17,6 | 2,8 |
| 2,9 | 1,17 | 18,3 | 2,7 |
| 1,75 | 17,5 | 2,3 | |
| 2,2 | 1,62 | 21,9 | 3,5 |
| 3,1 | 1,24 | 2,4 | |
| 3,6 | 1,33 | 20,5 | 3,1 |
| 2,3 | 19,5 | 2,5 | |
| 2,9 | 1,54 | 14,2 | 2,6 |
| 2,6 | 1,1 | 14,9 | 2,5 |
| 3,1 | 1,45 | 14,5 | 2,6 |
| 3,2 | 1,33 | 15,8 | 2,5 |
| 3,5 | 1,25 | 11,4 | 2,8 |
| 4,2 | 1,65 | 17,6 | 3,3 |
| 1,42 | 19,4 | 2,6 | |
| 1,36 | 21,4 | 2,7 | |
| 3,1 | 1,2 | 17,6 | 2,8 |
| 2,9 | 1,17 | 18,3 | 2,7 |
| 1,75 | 17,5 | 2,3 | |
| 2,2 | 1,62 | 21,9 | 3,5 |
| 3,1 | 1,24 | 2,4 | |
| 3,6 | 1,33 | 20,5 | 3,1 |
| 2,3 | 19,5 | 2,5 | |
| 2,9 | 1,54 | 14,2 | 2,6 |
| 2,6 | 1,1 | 14,9 | 2,5 |
| 3,1 | 1,45 | 14,5 | 2,6 |
| 3,2 | 1,33 | 15,8 | 2,5 |
| 3,5 | 1,25 | 11,4 | 2,8 |
| 4,2 | 1,65 | 17,6 | 3,3 |
| 1,42 | 19,4 | 2,6 | |
| 1,36 | 21,4 | 2,7 | |
| 3,1 | 1,2 | 17,6 | 2,8 |
| 2,9 | 1,17 | 18,3 | 2,7 |
| 1,75 | 17,5 | 2,3 | |
| 2,2 | 1,62 | 21,9 | 3,5 |
| 3,1 | 1,24 | 2,4 | |
| 3,6 | 1,33 | 20,5 | 3,1 |
| 2,3 | 19,5 | 2,5 | |
| 2,9 | 1,54 | 14,2 | 2,6 |
| 2,6 | 1,1 | 14,9 | 2,5 |
| 3,1 | 1,45 | 14,5 | 2,6 |
Приложение 2
Результаты статистического анализа.
| Valid N | Mean | Confidence | Confidence | Geometric | Harmonic | Median | Mode | Frequency | Sum | Minimum | |||
| Var1 | 3,21200 | 3,01280 | 3,41120 | 3,14218 | 3,07676 | 3,10000 | 3,100000 | 160,6000 | 2,20000 | ||||
| Var2 | 1,35300 | 1,29359 | 1,41241 | 1,33714 | 1,32129 | 1,33000 | 1,330000 | 67,6500 | 1,00000 | ||||
| Var3 | 17,30200 | 16,48980 | 18,11420 | 17,06011 | 16,80743 | 17,60000 | 17,60000 | 865,1000 | 11,40000 | ||||
| Var4 | 2,72000 | 2,62940 | 2,81060 | 2,70299 | 2,68720 | 2,60000 | Multiple | 136,0000 | 2,30000 | ||||
| Maximum | Lower | Upper | Percentile | Percentile | Quartile | Variance | Std.Dev. | Standard | Skewness | Std.Err. | Kurtosis | Std.Err. |
| 5,00000 | 2,90000 | 3,60000 | 2,30000 | 4,20000 | 0,700000 | 0,491282 | 0,700915 | 0,099124 | 0,895125 | 0,336601 | 0,757946 | 0,661908 |
| 1,75000 | 1,20000 | 1,54000 | 1,10000 | 1,65000 | 0,340000 | 0,043703 | 0,209053 | 0,029565 | 0,178172 | 0,336601 | -0,744058 | 0,661908 |
| 21,90000 | 14,90000 | 19,50000 | 14,20000 | 21,40000 | 4,600000 | 8,167547 | 2,857892 | 0,404167 | -0,176792 | 0,336601 | -0,712074 | 0,661908 |
| 3,50000 | 2,50000 | 2,80000 | 2,40000 | 3,30000 | 0,300000 | 0,101633 | 0,318799 | 0,045085 | 1,164480 | 0,336601 | 0,573469 | 0,661908 |








