 2014-02-02
2014-02-02 755
755Блокировки
Блокировкой является ограничение доступа к ресурсу в многопользовательской среде Обобщенно:
• транзакция, действием которой на строку данных в таблице является чтение, обязана наложить блокировку чтения на эту строку;
• транзакция, предназначенная для модификации строки данных, накладывает на нее блокировку записи;
• если запрашиваемая блокировка на строку отвергается из-за уже имеющейся блокировки, то транзакция переводится в режим ожидания до тех пор, пока блокировка не будет снята;
• блокировка записи сохраняется до конца выполнения транзакции.
Если транзакции исполняются параллельно и осуществляют доступ к совместно используемым объектам базы данных, то при невысоком уровне изолирования транзакций могут возникать следующие ситуации:
• потеря последнего обновления, когда несколько пользователей изменяют, например, один и ту же строку, основываясь на начальном значении ее полей. Часть данных может быть потеряна, поскольку каждая последующая транзакция перезапишет изменения, сделанные предыдущей.
• проблема " грязного " чтения возможна при чтении незафиксированных данных в том случае, если пользователь выполняет совокупность операций обработки данных, требующих неоднократного изменения данных для получения окончательного значения. Если в ходе этих изменений другой пользователь выполнит считывание данных, то может оказаться, что он считал еще не являющиеся окончательными, т.е. неверные значения;
• проблема неповторяемого чтения возникает, если транзакция несколько раз считывает, например, одну и ту же строку, а другая транзакция изменяет эту строку в промежутках между считываниями. При повторном чтении первая транзакция получит уже иной набор данных, что означает нарушение целостности или логическую несогласованность данных;
• проблема фантомов возникает, если первая транзакция считывает данные из таблицы, а другая транзакция вставляет или удаляет строки в диапазоне, считанном до этого первой транзакцией, до завершения и фиксации первой транзакции.
Для решения перечисленных проблем в специально разработанном стандарте определены четыре уровня блокирования. Уровень изолирования транзакции определяет, могут ли другие (конкурирующие) транзакции вносить изменения в данные, измененные текущей транзакцией, а также может ли текущая транзакция видеть изменения, произведенные конкурирующими транзакциями, и наоборот. Каждый последующий уровень поддерживает требования предыдущего и налагает дополнительные ограничения:
• уровень 0 – запрещение "загрязнения" данных. Этот уровень требует, чтобы изменять данные могла только одна транзакция. Если другой транзакции необходимо изменить те же данные, она должна ожидать завершения первой транзакции;
• уровень 1 – запрещение " грязного " чтения. Если транзакция начала изменение данных, то никакая другая транзакция не сможет прочитать их до завершения первой;
• уровень 2 – запрещение неповторяемого чтения. Если транзакция считывает данные, то никакая другая транзакция не сможет их изменить. Таким образом, при повторном чтении данные будут находиться в первоначальном состоянии;
• уровень 3 – запрещение фантомов. Если транзакция обращается к данным, то никакая другая транзакция не сможет добавить новые или удалить имеющиеся строки, которые могут быть считаны при выполнении транзакции. Реализация этого уровня блокирования выполняется путем использования блокировок диапазона ключей. Подобная блокировка накладывается на строки, удовлетворяющие определенному логическому условию.
В зависимости от выполняемых действий сервер накладывает определенный тип блокировки из следующего перечня:
• Разделяемые блокировки (Shared lock, S ). Их называют также блокировками без монополизации. Они накладываются при выполнении операций чтения данных (например, SELECT). Если сервер установил на ресурс разделяемую блокировку, то изменять эти данные нельзя, а читать можно.
• Блокировка обновления (Update, U). Используется для ресурсов, который могут быть обновлены. Препятствует «взаимоблокировке» при множественных чтениях, блокировании и возможно обновлении ресурсов далее. Если на ресурс установлена разделяемая блокировка и для этого ресурса устанавливается блокировка обновления, то никакая транзакция не сможет наложить разделяемую блокировку или блокировку обновления.
• Монопольная блокировка (Exclusive, X). Этот тип блокировок используется для операций модификации данных INSERT, UPDATE, DELETE. Когда сервер устанавливает монопольную блокировку на ресурс, то никакая другая транзакция не может прочитать или изменить заблокированные данные в данный момент. Монопольная блокировка не совместима ни с какими другими блокировками, и ни одна блокировка, включая монопольную, не может быть наложена на ресурс.
• Блокировка массивного обновления. Накладывается сервером при выполнении операций массивного копирования в таблицу и запрещает обращение к таблице любым другим процессам. В то же время несколько процессов, выполняющих массивное копирование, могут одновременно вставлять строки в таблицу.
Блокировки намерений используются сервером в том случае, если транзакция намеревается получить доступ к данным вниз по иерархии и для других транзакций необходимо установить запрет на наложение блокировок, которые будут конфликтовать с блокировкой, накладываемой первой транзакцией.
Взаимоблокировка возникает, например, в случае если:
1. Транзакция А создает разделяемую блокировку строки 1.
2. Транзакция B создает разделяемую блокировку строки 2.
3. Транзакция А запрашивает монопольную блокировку строки 2 и блокируется до того, как транзакция B завершится и освободит разделяемую блокировку строки 2.
4. Транзакция B запрашивает монопольную блокировку строки 1 и блокируется до того, как транзакция A завершится и освободит разделяемую блокировку строки 1.
5. Транзакция А не может завершиться пока не завершится транзакция B, а транзакция B заблокирована транзакцией А. Такое условие также называется круговой зависимостью: транзакция А зависит от транзакции B, а транзакция B зависит от транзакции А. Транзакции находятся в состоянии бесконечного ожидания.
Существует два других типа блокировок: блокировка диапазона ключей и блокировка схемы (метаданных, описывающих структуру объекта).
Блокировка диапазона ключей решает проблему возникновения фантомов и обеспечивает требования сериализуемости транзакции. Блокировки этого типа устанавливаются на диапазон строк, соответствующих определенному логическому условию, по которому осуществляется выборка данных из таблицы.
Основная литература
| Учебник / Учебное пособие | Раздел | Страницы |
| 1. Таненбаум Э. Современные операционные системы. 3-е изд. - СПб.: Питер, 2010. - 1120 е.: ил. | 2.3.8, 6.7.2 | 176-180, 534-536 |
| 2. Карпова Т.С. Базы данных: модели, разработка, реализация. - СПб.: Питер, 2001.- 304 с.; ил. | Глава 11 | 216-247 |
Дополнительная литература
| Учебник / Учебное пособие | Раздел | Страницы |
| 1. Дейт К. Дж. Введение в системы баз данных, 6-е издание: Пер. с англ. – К.;М.; СПб.: Издательский дом “Вильямс”,. 1999. – 848 с.: ил. (7-е и 8-е издание). | 13.2 – 13.7, 14.2 – 14.9 | 376-384, 393-409 |
| 2. Коннолли Т., Бегг К., Страчан А. Базы данных: проектирование, реализация и сопровождение. Теория и практика, 2-е изд.: Пер. с англ. - М.: Издательский дом “Вильямс”,. 2001. – 1120 с.: ил. | 17.1 – 17.4 | 595-636 |
Тема 2. Структуры хранения и доступа к данным. Индексы
Лекция №2. Структуры хранения на примере SQL Server
В рамках данной лекции рассматриваются вопросы физических структур хранения данных.
В качестве иллюстрации рассматривается организация данных в SQL Server. Различают файлы трех типов.
Первичные файлы данных. Первичный файл данных является отправной точкой базы данных. Он указывает на остальные файлы базы данных. В каждой базе данных имеется один первичный файл данных. Для имени первичного файла данных рекомендуется использовать расширение MDF.
Вторичные файлы данных. Ко вторичным файлам данных относятся все файлы данных, за исключением первичного файла данных. Некоторые базы данных могут вообще не содержать вторичных файлов данных, тогда как другие содержат несколько вторичных файлов данных. Для имени вторичного файла данных рекомендуется использовать расширение NDF.
Файлы журналов. Файлы журналов содержат все сведения журналов, используемые для восстановления базы данных. В каждой базе данных должен быть по меньшей мере один файл журнала, но их может быть и больше. Для имен файлов журналов рекомендуется использовать расширение LDF.
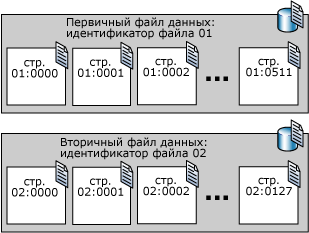
Первая страница каждого файла — это страница заголовка файла; она содержит сведения об атрибутах данного файла. Некоторые другие страницы, расположенные в начале файла, тоже содержат системные сведения, например карты размещения. Одна из системных страниц, хранимых как в первичном файле данных, так и в первом файле журнала, представляет собой загрузочную страницу базы данных, которая содержит сведения об атрибутах этой базы данных.
Основной единицей хранилища данных в SQL Server является страница. Место на диске, предоставляемое для размещения файла данных (MDF- или NDF-файл) в базе данных, логически разделяется на страницы с непрерывным перечислением от 0 до n. Дисковые операции ввода-вывода выполняются на уровне страницы. А именно, SQL Server считывает или записывает целые страницы данных.
Экстент — это коллекция, состоящая из восьми физически непрерывных страниц; они используются для эффективного управления страницами. Все страницы хранятся в экстентах.
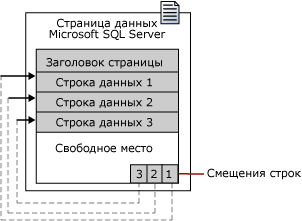
В SQL Server 2008 размер страницы составляет 8 КБ. Это значит, что в одном мегабайте базы данных SQL Server содержится 128 страниц. Каждая страница начинается с 96-байтового заголовка, который используется для хранения системных данных о странице. Эти данные включают номер страницы, тип страницы, объем свободного места на странице и идентификатор единицы распределения объекта, которому принадлежит страница.
Экстенты являются основными единицами организации пространства. Экстент состоит из восьми непрерывных страниц или 64 КБ. Это значит, что в одном мегабайте базы данных SQL Server содержится 16 экстентов.
Чтобы сделать распределение места эффективным, SQL Server имеет два типа экстентов.
Однородные э кстенты принадлежат одному объекту; все восемь страниц в кластере могут быть использованы только этим владеющим объектом.
Смешанны е экстенты могут находиться в общем пользовании у не более восьми объектов. Каждая из восьми страниц в экстенте может находиться во владении разных объектов.
Новая таблица или индекс — это обычно страницы, выделенные из смешанных экстентов. При увеличении размера таблицы или индекса до восьми страниц эти таблица или индекс переходят на использование однородных экстентов для последовательных единиц распределения. При создании индекса для существующей таблицы, в которой содержится достаточно строк, чтобы сформировать восемь страниц в индексе, все единицы распределения для индекса находятся в однородных экстентах.








