 2014-02-12
2014-02-12 1844
1844Секция управления процессора
Команды выбираются из ОП блоками и заносятся в буфера команд, откуда они затем выбираются для исполнения. Если необходимой для исполнения команды нет в буферах команд, то происходит выборка очередного блока.
Команды имеют различный формат и могут занимать 1 пакет (16 разрядов), 2 пакета или 3 пакета (в одном слове 64 разряда, следовательно, в слове содержится 4 пакета). Максимальная длина программы на CRAY C90 равна 1 Гигаслову.
Конвейеризация выполнения команд
Все основные операции, выполняемые процессором: обращения в память, обработка команд и выполнение инструкций являются конвейерными.
Независимость функциональных устройств
Большинство ФУ в CRAY C90 являются независимыми, поэтому несколько операций могут выполняться одновременно. Для операции A=(B+C)*D*E порядок выполнения может быть следующим (все аргументы загружены в S регистры). Генерируются три инструкции: умножение D и E, сложение B и C и умножение результатов двух предыдущих операций. Первые две операции выполняются одновременно, затем третья.
Векторная обработка
Векторная обработка увеличивает скорость и эффективность обработки за счет того, что обработка целого набора (вектора) данных выполняется одной командой. Скорость выполнения операций в векторном режиме приблизительно в 10 раз выше скорости скалярной обработки. Для фрагмента типа
Do i = 1, n A(i) = B(i)+C(i) End Do
в скалярном режиме потребуется сгенерировать целую последовательность команд: прочитать элемент B(I), прочитать элемент C(I), выполнить сложение, записать результат в A(I), увеличить параметр цикла, проверить условие цикла. В векторном режиме этот фрагмент преобразуется в: загрузить порцию массива B, загрузить порцию массива C (эти две операции будут выполняться со сдвигом в один такт, т.е. практически одновременно), векторное сложение, запись порции массива в память, если размер массивов больше длины векторных регистров, то повторить эту последовательность некоторое число раз.
Перед тем, как векторная операция начнет выдавать результаты, проходит некоторое время (startup), связанное с заполнением конвейера и подкачкой аргументов. Чем больше длина векторов, тем менее заметным оказывается влияние данного начального промежутка времени на все время выполнения программы.
Векторные операции, использующие различные ФУ и регистры, могут выполняться параллельно.
Зацепление функциональных устройств
Архитектура CRAY C90 позволяет использовать регистр результатов векторной операции в качестве входного регистра для последующей векторной операции, т.е. выход сразу подается на вход. Это называется зацеплением векторных операций. Вообще говоря, глубина зацепления может быть любой, например, чтение векторов, выполнение операции сложения, выполнение операции умножения, запись векторов.
Многопроцессорная обработка: multiprogramming, multitasking
Пиковая производительность CRAY Y-MP C90
Пиковая производительность компьютера CRAY Y-MP C90 вычисляется так: функциональные устройства выдают два результата каждый такт (сдвоенные конвейеры), зацепление сложения и умножения дает четыре операции за такт, что составляет почти 1 Гфлопс (109 опер/с). Если работают все 16 процессоров, то 16 Гфлопс.
При подготовке лекции использованы материалы сайта https://parallel.ru
Хорошевский, В. Архитектура вычислительных систем / В.Г. Хорошевский. Москва: МГТУ им. Баумана, 2008. - 520 с.
Цилькер, Б. Организация ЭВМ и систем / Б.Я. Цилькер, С.А. Орлов. СПб.: Питер - 2007, 672 c.
Лекция 11. Матричные вычислительные системы
Назначение матричных вычислительных систем - обработка больших массивов данных (во многом схоже с назначением векторных ВС). В основе матричных систем лежит матричный процессор (array processor), состоящий из регулярного массива процессорных элементов (ПЭ).
Организация систем подобного типа на первый взгляд достаточно проста. Они имеют общее управляющее устройство, генерирующее поток команд, и большое число ПЭ, работающих параллельно и обрабатывающих каждый свой поток данных.
Между матричными и векторными системами есть существенная разница. Матричный процессор интегрирует множество идентичных функциональных блоков (ФБ), логически объединенных в матрицу и работающих в SIMD-стиле. Не столь существенно, как конструктивно реализована матрица процессорных элементов — на едином кристалле или на нескольких. Важен сам принцип - ФБ логически скомпонованы в матрицу и работают синхронно, то есть присутствует только один поток команд для всех. Векторный процессор имеет встроенные команды для обработки векторов данных, что позволяет эффективно загрузить конвейер из функциональных блоков. В свою очередь, векторные процессоры проще использовать, потому что команды для обработки векторов — это более удобная для человека модель программирования, чем SIMD.
Структуру матричной вычислительной системы можно представить в следующем виде.
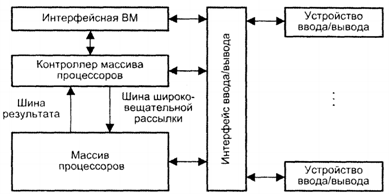
Обобщенная модель матричной ВС
Рассмотрим компоненты обобщенной модели матричной ВС.
· Массив процессоров (МПр) осуществляет параллельную обработку множественных элементов данных.
· Контроллер массива процессоров (КМП) генерирует единый поток команд, управляющий обработкой данных в массиве процессоров, выполняет последовательный программный код, реализует операции условного и безусловного переходов, транслирует в МПр команды, данные и сигналы управления. Команды обрабатываются процессорами в режиме жесткой синхронизации.
· Сигналы управления используются для синхронизации команд и пересылок, а также для управления процессом вычислений, в частности определяют, какие процессоры массива должны выполнять операцию, а какие - нет.
· Шина широковещательной рассылки служит для передачи команд, данных и сигналов управления из КМП в массив процессоров.
· Шина результата служит для трансляции результатов вычислений из МПр в КМП (это требуется, поскольку выполнение операций условного перехода зависит от результатов вычислений).
· Интерфейсная ВМ (front-end computer)
служит для обеспечения пользователя удобным интерфейсом при создании и отладке программ. В роли такой ВМ выступает универсальная вычислительная машина, на которую дополнительно возлагается задача загрузки программ и данных в КМП. Кроме того, загрузка программ и данных в КМП может производиться и напрямую с устройств ввода/вывода, например с магнитных дисков. После загрузки КМП приступает к выполнению программы, транслируя в МПр по широковещательной шине соответствующие SIMD-команды.
Рассматривая массив процессоров, следует учитывать, что для хранения множественных наборов данных в нем, помимо множества процессоров, должно присутствовать и множество модулей памяти. Кроме того, в массиве должна быть реализована сеть взаимосвязей, как между процессорами, так и между процессорами и модулями памяти.
Таким образом, под термином массив процессоров понимают блок, состоящий из процессоров, модулей памяти и сети соединений. Дополнительную гибкость при работе с рассматриваемой системой обеспечивает механизм маскирования, позволяющий привлекать к участию в операциях лишь определенное подмножество из входящих в массив процессоров. Маскирование реализуется как на стадии компиляции, так и на этапе выполнения, при этом процессоры, исключенные путем установки в ноль соответствующих битов маски, во время выполнения команды простаивают.
Интерфейсная ВМ
Интерфейсная ВМ (ИВМ) соединяет матричную SIMD-систему с внешним миром, используя для этого какой-либо из сетевых интерфейсов, например Ethernet, как это имеет место в системе MasPar MP-1. Интерфейсная ВМ работает под управлением операционной системы, чаще всего ОС UNIX. На ИВМ пользователи подготавливают, компилируют и отлаживают свои программы. В процессе выполнения программы сначала загружаются из интерфейсной ВМ в контроллер управления массивом процессоров, который выполняет программу и распределяет команды и данные по процессорным элементам массива. В некоторых ВС, например в Massively Parallel Computer MPP, при создании, компиляции и отладке программ КМП и интерфейсная ВМ используются совместно.
На роль ИВМ подходят различные вычислительные машины. Так, в системе СМ-2 в этом качестве выступает рабочая станция SUN-4, в системе MasPar — DECstation 3000, а в системе МРР - DEC VAX-11/78
Контроллер массива процессоров
Функции контроллера массива процессоров:
· выполняет последовательный программный код,
· реализует команды ветвления программы,
· транслирует команды и сигналы управления в процессорные элементы.
Рисунок иллюстрирует одну из возможных реализаций КМП, в частности принятую в устройстве управления системы PASM (Partitioned SIMD/MIMD computer).
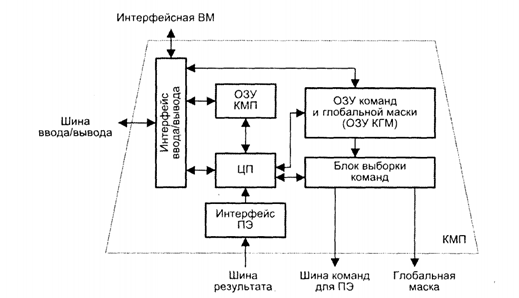
Контроллер массива процессоров
При загрузке из ИВМ программа через интерфейс ввода/вывода заносится в оперативное запоминающее устройство КМП (ОЗУ КМП). Команды для процессорных элементов и глобальная маска, формируемая на этапе компиляции, также через интерфейс ввода/вывода загружаются в ОЗУ команд и глобальной маски (ОЗУ КГМ). Затем КМП начинает выполнять программу, извлекая либо одну скалярную команду из ОЗУ КМП, либо множественные команды из ОЗУ КГМ. Скалярные команды - команды, осуществляющие операции над хранящимися в КМП скалярными данными, выполняются центральным процессором (ЦП) контроллера массива процессоров. В свою очередь, команды, оперирующие параллельными переменными, хранящимися в каждом ПЭ, преобразуются в блоке выборки команд в более простые единицы выполнения - нанокоманды. Нанокоманды совместно с маской пересылаются через шину команд для ПЭ на исполнение в массив процессоров. Например, команда сложения 32-разрядных слов в КМП системы МРР преобразуется в 32 нанокоманды одноразрядного сложения, которые каждым ПЭ обрабатываются последовательно,
В большинстве алгоритмов дальнейший порядок вычислений зависит от результатов и/или флагов условий предшествующих операций. Для обеспечения такого режима в матричных системах статусная информация, хранящаяся в процессорных элементах, должна быть собрана в единое слово и передана в КМП для выработки решения о ветвлении программы. Например, в предложении
IF A (условиеA) THEN DO В
оператор В будет выполнен, если условие А справедливо во всех ПЭ. Для корректного включения/отключения процессорных элементов КМП должен знать результат проверки условия А во всех ПЭ. Такая информация передается в КМП по однонаправленной шине результата. В системе СМ-2 эта шина названа GLOBAL. В системе МРР для той же цели организована структура, называемая деревом SUM - OR. Каждый ПЭ помещает содержимое своего одноразрядного регистра признака на входы дерева, которое с помощью операции логического сложения комбинирует эту информацию и формирует слово результата, используемое в КМП для принятия решения.
Массив процессоров
В матричных SIMD-системах распространение получили два основных типа архитектурной организации массива процессорных элементов.
В первом варианте, известном как архитектура типа «процессорный элемент - процессорный элемент»(«ПЭ-ПЭ»):
· N процессорных элементов (ПЭ) связаны между собой сетью соединений.
· Каждый ПЭ - это процессор с локальной памятью.
· Процессорные элементы выполняют команды, получаемые из КМП по шине широковещательной рассылки, и обрабатывают данные как хранящиеся в их локальной памяти, так и поступающие из КМП.
· Обмен данными между процессорными элементами производится по сети соединений, в то время как шина ввода/вывода служит для обмена информацией между ПЭ и устройствами ввода/вывода.
· Для трансляции результатов из отдельных ПЭ в контроллер массива процессоров служит шина результата.
· Благодаря использованию локальной памяти аппаратные средства ВС рассматриваемого типа могут быть построены весьма эффективно. Во многих алгоритмах действия по пересылке информации по большей части локальны, то есть происходят между ближайшими соседями. По этой причине архитектура, где каждый ПЭ связан только с соседними, очень популярна. В качестве примеров вычислительных систем с рассматриваемой архитектурой можно упомянуть MasPar MP-1, Connection Machine CM-2, GF11, DAP, МРР, STARAN, PEPE, ILLIAC IV.
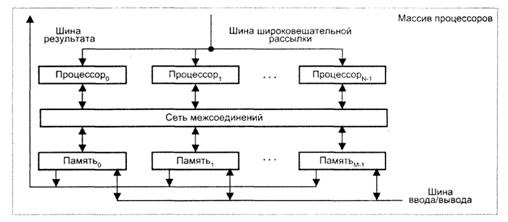
Архитектура типа «процессорный элемент - процессорный элемент»
Второй вид архитектуры — «процессор-память» В такой конфигурации двунаправленная сеть соединений связывает N процессоров с М модулями памяти. Процессоры управляются КМП через широковещательную шину. Обмен данными между процессорами осуществляется как через сеть, так и через модули памяти. Пересылка данных между модулями памяти и устройствами ввода/вывода обеспечивается шиной ввода/вывода. Для передачи данных из конкретного модуля памяти в КМП служит шина результата. Примерами ВС с рассмотренной архитектурой могут служить Burroughs Scientific Processor (BSP), Texas Reconfigurable Array Computer (TRAC).
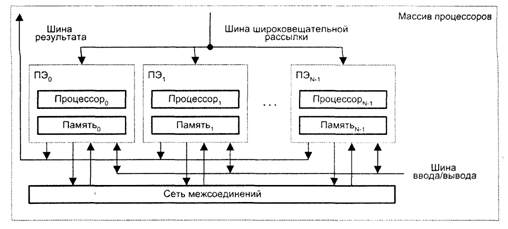
Архитектура типа «процессор-память»
Структура процессорного элемента
В большинстве матричных SIMD-систем в качестве процессорных элементов применяются простые RISC-процессоры с локальной памятью ограниченной емкости.
Например, каждый ПЭ системы MasPar MP-1 состоит из четырехразрядного процессора с памятью емкостью 64 Кбайт. В системе МРР используются одноразрядные процессоры с памятью 1 кбит каждый, а в СМ-2 процессорный элемент представляет собой одноразрядный процессор с 64 Кбит локальной памяти. Благодаря простоте ПЭ массив может быть реализован в виде одной сверхбольшой интегральной микросхемы (СБИС). Это позволяет сократить число связей между микросхемами и, следовательно, габариты ВС. Так, одна СБИС в системе СМ-2 содержит 16 процессоров (без блоков памяти), а в системе MasPar MP-1 СБИС состоит из 32 процессоров (также без блоков памяти). В системе МР-2 просматривается тенденция к применению более сложных микросхем, в частности 32-разрядных процессоров с 256 Кбайт памяти в каждом.
Неотъемлемыми компонентами ПЭ (рис.) в большинстве вычислительных систем являются:
· арифметико-логическое устройство (АЛУ);
· регистры данных;
· сетевой интерфейс (СИ), который может включать в свой состав регистры пересылки данных;
· номер процессора;
· регистр флага разрешения маскирования (F);
· локальная память.
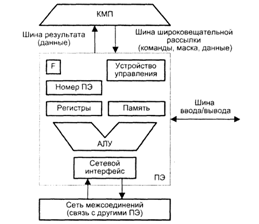
Структура процессорного элемента
Процессорные элементы, управляемые командами, поступающими по широковещательной шине из КМП, могут выбирать данные из своей локальной памяти и регистров, обрабатывать их в АЛУ и сохранять результаты в регистрах и локальной памяти. ПЭ могут также обрабатывать те данные, которые поступают по шине широковещательной рассылки из КМП. Кроме того, каждый процессорный элемент вправе получать данные из других ПЭ и отправлять их в другие ПЭ по сети соединений, используя для этого свой сетевой интерфейс. В некоторых матричных системах, в частности в MasParМР-1, элемент данных из ПЭ-источника можно передавать в ПЭ-приемник непосредственно, в то время как в других, например в МРР, - данные предварительно должны быть помещены в специальный регистр пересылки данных, входящий в состав сетевого интерфейса. Пересылка данных между ПЭ и устройствами ввода/вывода осуществляется через шину ввода/вывода ВС. В ряде систем (MasParMP-1) ПЭ подключены к шине ввода/вывода посредством сети соединений и канала ввода/вывода системы. Результаты вычислений любое ПЭ выдает в КМП через шину результата.
Каждому из N ПЭ в массиве процессоров присваивается уникальный номер, называемый также адресом ПЭ, который представляет собой целое число от 0 до N- 1. Чтобы указать, должен ли данный ПЭ участвовать в общей операции, в его составе имеется регистр флага разрешения F. Состояние этого регистра определяют сигналы управления из КМП, либо результаты операций в самом ПЭ, либо и те и другие совместно.
Еще одной существенной характеристикой матричной системы является способ синхронизации работы ПЭ. Так как все ПЭ получают и выполняют команды одновременно, их работа жестко синхронизируется. Это особенно важно в операциях пересылки информации между ПЭ. В системах, где обмен производится с четырьмя соседними ПЭ, передача информации осуществляется в режиме «регистр- регистр».
Подключение и отключение процессорных элементов
В процессе вычислений в ряде операций должны участвовать только определенные ПЭ, в то время как остальные ПЭ остаются бездействующими. Разрешение и запрет работы ПЭ могут исходить от контроллера массива процессоров (глобальное маскирование) и реализуются с помощью схем маскирования ПЭ. В этом случае решение о необходимости маскирования принимается на этапе компиляции кода. Решение о маскировании может также приниматься во время выполнения программы (маскирование, определяемое данными), при этом опираются на хранящийся в ПЭ флаг разрешения маскирования F.
При маскировании, определяемом данными, каждый ПЭ самостоятельно объявляет свой статус «подключен/не подключен». В составе системы команд имеются наборы маскируемых и немаскируемых команд. Маскируемые команды выполняются в зависимости от состояния флага F, в то время как немаскируемые флаг просто игнорируют. Процедуру маскирования рассмотрим на примере предложения IF-THEN-ELSE, Пусть х - локальная переменная (хранящаяся в локальной памяти каждого ПЭ). Предположим, что процессорные элементы массива параллельно выполняют, ветвление:
if(х > 0) then < оператор А > else < оператор В >
и каждый ПЭ оценивает условие IF. Т.е. ПЭ, для которых условие х > 0 справедливо, установят свой флаг F в единицу, тогда как остальные ПЭ - в ноль. Далее КМП распределяет оператор А по всем ПЭ. Команды, реализующие этот оператор, должны быть маскируемыми. Оператор А будет выполнен только теми ПЭ, где флаг F установлен в единицу. Далее КМП передает во все ПЭ немаскируемую команду ELSE, которая заставит все ПЭ инвертировать состояние своего флага F. Затем КМП транслирует во все ПЭ оператор В, который также должен состоять из маскируемых команд. Оператор будет выполнен теми ПЭ, где флаг F после инвертирования был установлен в единицу, то есть где результат проверки условия х > 0 был отрицательным.
При использовании схемы глобального маскирования контроллер массива процессоров вместе с командами посылает во все ПЭ глобальную маску. Каждый ПЭ декодирует эту маску и по результату выясняет, должен ли он выполнять данную команду или нет. Глобальные и локальные схемы маскирования могут комбинироваться. В таком случае активность ПЭ в равной мере определяется как флагом F, так и глобальной маской.
Сети взаимосвязей процессорных элементов
Эффективность сетей взаимосвязей процессорных элементов во многом определяет возможную производительность всей матричной системы. Применение находят самые разнообразные топологии сетей.
Поскольку процессорные элементы в матричных системах функционируют синхронно, обмениваться информацией они также должны по согласованной схеме, причем необходимо обеспечить возможность синхронной передачи от нескольких ПЭ-источников к одному ПЭ-приемнику. Когда для передачи информации в сетевом интерфейсе задействуется только один регистр пересылки данных, это может привести к потере данных, поэтому в ряде ВС для предотвращения подобной ситуации предусмотрены специальные механизмы. Так, в системе СМ-2 используется оборудование, объединяющее сообщения, поступившие к одному ПЭ.
В некоторых SIMD-системах, например МР-1, имеется возможность записать одновременно пришедшие сообщения в разные ячейки локальной памяти.
Хотя пересылки данных по сети инициируются только активными ПЭ, пассивные процессорные элементы также вносят вклад в эти операции. Если активный ПЭ инициирует чтение из другого ПЭ, операция выполняется вне зависимости от статуса ПЭ, из которого считывается информация. То же самое происходит и при записи.
Наиболее распространенными топологиями в матричных системах являются решетчатые и гиперкубические. Так, в ILLIAC IV, МРР и СМ-2 каждый ПЭ соединен с четырьмя соседними. В МР-1 и МР-2 каждый ПЭ связан с восьмью смежными ПЭ. В ряде систем реализуются многоступенчатые динамические сети соединений (МР-1, МР-2, GF11).
ВС ILLIAC IV
Матричная система ILLIAC IV (ILLInois Automated Computer) создана Иллинойским университетом и корпорацией Бэрроуз (Burroughs Corporation). Она разрабатывалась с 1966 и в 1972 система эксплуатировалась в Научно-исследовательском центре НАСА (NASA – National Aeronautics and Space Administration – Национальное управление аэронавтики и космоса).
Количество процессоров в системе – 64; быстродействие – 2*108 опер./с; емкость оперативной памяти – 1 М байт; полезное время составляет 80-85% общего времени работы ILLIAC IV, стоимость 40 000 000 долл., вес 75 т, занимаемая площадь 930 м2.
Система ILLIAC IV была включена в вычислительную сеть ARPA (Advanced Research Projects Agency – Управление перспективных исследований и разработок Министерства обороны США) и успешно эксплуатировалось до 1981г.
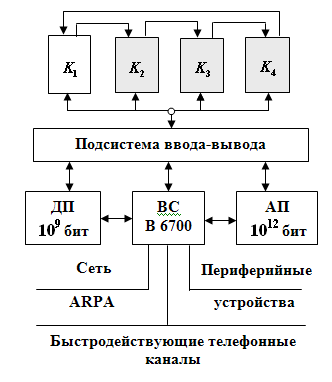
Функциональная структура системы ILLIAC IV
Матричная вычислительная система ILLIAC IV должна была состоять из 4 квадрантов (К1–К4), подсистемы ввода-вывода информации, ведущей ВС B 6700 (или B 6500), дисковой памяти (ДП) и архивной памяти (АП). Планировалось, что ВС обеспечит быстродействие 109 опер./с. В реализованном варианте ILLIAC IV содержался только один квадрант, что обеспечило быстродействие 2*108 опер./с. При этом ILLIAC IV оставалась самой быстродействующей вычислительной системой вплоть до 80-х годов 20 столетия.
Квадрант – матричный процессор, включавший в себя устройство управления и 64 элементарных процессора. Устройство управления представляло собой специализированную ЭВМ, которая использовалась для выполнения операций над скалярами и формировала поток команд на матрицу ЭП. Элементарные процессоры матрицы регулярным образом были связаны друг с другом. Структура квадранта системы ILLIAC IV представлялась двумерной решеткой, в которой граничные ЭП были связаны по канонической схеме (циркулянтным графом), которую можно изобразить в виде плоской решетки, где узлы в каждом столбце замкнуты в кольцо, а узлы в последовательных рядах соединены в замкнутую спираль. Второй вариант представления – хордальное кольцо с шагом хорды равном 4.
Каждый ЭП имел:
· накапливающий сумматор (64 разряда),
· регистр второго операнда (64 разряда),
· регистр передаваемой информации (из данного ЭП в соседний ЭП) (64 разряда),
· регистр, использовавшийся как временная память (64 разряда),
· регистр модификации адресного поля команды (16 разрядов),
· регистр состояния данного ЭП (8 разрядов).
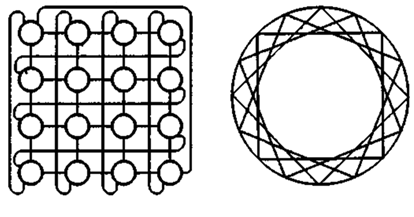
Структура межпроцессорных связей в ILLIACIV
ЭП мог находиться в одном из двух состояний – активном или пассивном. В первом состоянии ему разрешалось, а во втором запрещалось выполнять команды, поступавшие из устройства управления. Состояние ЭП задавалось при помощи специальных команд. Накапливающий сумматор и все регистры ЭП были программно адресуемы.
Память каждого ЭП – 16 Кб. К каждой памяти непосредственный доступ имел собственный ЭП. Обмен информацией между памятями различных ЭП осуществляется по сети связи при помощи специальных команд пересылок.
Подсистема ввода-вывода состояла из устройства управления, буферного запоминающего устройства и коммутатора. Комплекс этих устройств обеспечивал обмен информацией между квадрантами ILLIAC IV и средствами ввода-вывода: ЭВМ В 6700, дисковой и архивной памятью, периферийными устройствами, сетью ARPA.
Ведущая ВС В 6700 – это мультипроцессорная система корпорации Burroughs, которая могла иметь в своем составе от 1 до 3 центральных процессоров и от 1 до 3 процессоров ввода-вывода информации и обладала быстродействием 1–3 млн. операций в секунду. Она использовалась для реализации функций операционной системы (включая ввод-вывод информации, операции по компиляции и компоновке программ, распределение аппаратных ресурсов, исполнение служебных программ и т.п.).
Дисковая память (ДП) состояла из двух дисков и обрамляющих электронных схем.
Эта память имела емкость порядка 109 бит и была снабжена двумя каналами, по каждому из которых можно было параллельно передавать и принимать информацию со скоростью 0,5*109 бит/с. Среднее время обращения к диску 20 мс.
Архивная память (АП) – постоянная лазерная память с однократной записью, разработанная фирмой Precision Instrument Company.
В системе ILLIAC IV насчитывалось более 6*106 электронных компонентов. Отказы компонентов или соединений могли происходить через несколько часов. По этой причине в систему была включена обширная библиотека контрольных и диагностических тестов.
Средства программирования ILLIAC IV включали язык ассемблера (Assembler Language) и три языка высокого уровня: Tranquil, Glynpir, FORTRAN. Языки высокого уровня в силу архитектурных особенностей ILLIAC IV отличались от соответствующих языков ЭВМ в части распределения двумерной памяти, операций над векторами и пересылок данных.
Ассоциативная память
Обычно в запоминающих устройствах доступ к информации требует указания адреса ячейки. Однако значительно удобнее искать информацию не по адресу, а опираясь на какой-нибудь характерный признак, содержащийся в самой информации. Такой принцип лежит в основе ЗУ, известного как ассоциативное запоминающее устройство (АЗУ). В литературе встречаются и иные названия подобного ЗУ: память, адресуемая по содержанию (content addressable memory); память, адресуемая по данным (data addressable memory); память с параллельным поиском (parallel search memory); каталоговая память (catalog memory); информационное ЗУ (information storage); тегированная память (tag memory).
Ассоциативное ЗУ – это устройство, способное хранить информацию, сравнивать ее с некоторым заданным образцом и указывать на их соответствие или несоответствие друг другу.
В отличие от обычной машинной памяти (памяти произвольного доступа или RAM), в которой пользователь задает адрес памяти и ОЗУ возвращает слово данных, хранящееся по этому адресу, АП разработана таким образом, чтобы пользователь задавал слово данных, и АП ищет его во всей памяти, чтобы выяснить, хранится ли оно где-нибудь в нем. Если слово данных найдено, АП возвращает список одного или более адресов хранения, где слово было найдено (и в некоторых архитектурах, также возвращает само слово данных, или другие связанные части данных). Таким образом, АП - аппаратная реализация того, что в терминах программирования назвали бы ассоциативным массивом.
Ассоциативный признак – признак, по которому производится поиск информации.
Признак поиска – кодовая комбинация, выступающая в роли образца для поиска.
Ассоциативный признак может быть частью искомой информации или дополнительно придаваться ей. В последнем случае его принято называть тегом или ярлыком.
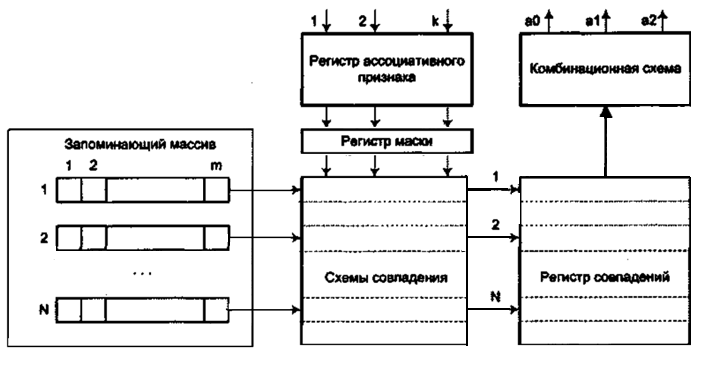
Структура ассоциативного ЗУ
АЗУ включает в себя:
· запоминающий массив для хранения N m-разрядных слов, в каждом из которых несколько младших разрядов занимает служебная информация;
· регистр ассоциативного признака, куда помещается код искомой информации (признак поиска). Разрядность регистра k обычно меньше длины слова т;
· схемы совпадения, используемые для параллельного сравнения каждого бита всех хранимых слов с соответствующим битом признака поиска и выработки сигналов совпадения;
· регистр совпадений, где каждой ячейке запоминающего массива соответствует один разряд, в который заносится единица, если все разряды соответствующей ячейки совпали с одноименными разрядами признака поиска;
· регистр маски, позволяющий запретить сравнение определенных битов;
· комбинационную схему, которая на основании анализа содержимого регистра совпадений формирует сигналы, характеризующие результаты поиска информации.
При обращении к АЗУ сначала в регистре маски обнуляются разряды, которые не должны учитываться при поиске информации. Все разряды регистра совпадений устанавливаются в единичное состояние. После этого в регистр ассоциативного признака заносится код искомой информации (признак поиска) и начинается ее поиск, в процессе которого схемы совпадения одновременно сравнивают первый бит всех ячеек запоминающего массива с первым битом признака поиска. Те схемы, которые зафиксировали несовпадение, формируют сигнал, переводящий соответствующий бит регистра совпадений в нулевое состояние. Так же происходит процесс поиска и для остальных незамаскированных битов признака поиска. В итоге единицы сохраняются лишь в тех разрядах регистра совпадений, которые соответствуют ячейкам, где находится искомая информация. Конфигурация единиц в регистре совпадений используется в качестве адресов, по которым производится считывание из запоминающего массива. Из-за того что результаты поиска могут оказаться неоднозначными, содержимое регистра совпадений подается на комбинационную схему, где формируются сигналы, извещающие о том, что искомая информация:
· а0 – не найдена;
· а1 – содержится в одной ячейке;
· а2 – содержится более чем в одной ячейке.
Формирование содержимого регистра совпадений и сигналов a0, a1, а2 носит название операции контроля ассоциации. Она является составной частью операций считывания и записи, хотя может иметь и самостоятельное значение.
При считывании сначала производится контроль ассоциации по аргументу поиска. Затем, при а0=1 считывание отменяется из-за отсутствия искомой информации, приa1 =1 считывается слово, на которое указывает единица в регистре совпадений, а при а2= 1 сбрасывается самая старшая единица в регистре совпадений и извлекается соответствующее ей слово. Повторяя эту операцию, можно последовательно считать все слова.
Запись в АП производится без указания конкретного адреса, в первую свободную ячейку. Для отыскания свободной ячейки выполняется операция считывания, в которой не замаскированы только служебные разряды, показывающие, как давно производилось обращение к данной ячейке, и свободной считается либо пустая ячейка, либо та, которая дольше всего не использовалась.
Главное преимущество ассоциативных ЗУ определяется тем, что время поиска информации зависит только от числа разрядов в признаке поиска и скорости опроса разрядов и не зависит от числа ячеек в запоминающем массиве.
Общность идеи ассоциативного поиска информации отнюдь не исключает разнообразия архитектур АЗУ. Конкретная архитектура определяется сочетанием четырех факторов:
1. вида поиска информации;
2. техники сравнения признаков;
3. способа считывания информации при множественных совпадениях;
4. способа записи информации.
В каждом конкретном применении АЗУ задача поиска информации может формулироваться по-разному.
Виды поиска информации:
· Простой (требуется полное совпадение всех разрядов признака поиска с одноименными разрядами слов, хранящихся в запоминающем массиве).
· Сложный:
o Поиск всех слов, больших или меньших заданного. Поиск слов в заданных пределах.
o Поиск максимума или минимума. Многократное выборка из АЗУ слова с максимальным или минимальным значением ассоциативного признака (с исключением его из дальнейшего поиска), по существу, представляет собой упорядоченную выборку информации. Упорядоченную выборку можно обеспечить и другим способом, если вести поиск слов, ассоциативный признак которых по отношению к признаку опроса является ближайшим большим или меньшим значением.
Очевидно, что реализация сложных методов поиска связана с соответствующими изменениями в архитектуре АЗУ, в частности с усложнением схемы ЗУ и введением в нее дополнительной логики.
Техника сравнения признаков:
При построении АЗУ выбирают из четырех вариантов организации опроса содержимого памяти. Варианты эти могут комбинироваться параллельно по группе разрядов и последовательно по группам. В плане времени поиска наиболее эффективным можно считать параллельный опрос как по словам, так и по разрядам, но не все виды запоминающих элементов допускают такую возможность.
Способ считывания информации при множественных совпадениях:
· С цепью очередности (с помощью достаточно сложного устройства, где фиксируются слова, образующие многозначный ответ. Цепь очередности позволяет производить считывание слов в порядке возрастания номера ячейки АЗУ независимо от величины ассоциативных признаков).
· Алгоритмически (в результате серии опросов).
Способ записи информации:
1. По адресу.
2. C сортировкой информации на входе АЗУ по величине ассоциативного признака (местоположение ячейки, куда будет помещено новое слово, зависит от соотношения ассоциативных признаков вновь записываемого слова и уже хранящихся в АЗУ слов).
3. По совпадению признаков.
4. С цепью очередности.
Из-за относительно высокой стоимости АЗУ редко используется как самостоятельный вид памяти.
Ассоциативные ВС
Ассоциативный процессор (АП) – это ассоциативная память, допускающая параллельную запись во все ячейки, для которых было зафиксировано совпадение с ассоциативным признаком. Эта особенность АП, носящая название мультизаписи, является первым отличием ассоциативного процессора от традиционной ассоциативной памяти. Считывание и запись информации могут производиться по двум срезам запоминающего массива — либо это все разряды одного слова, либо один и тот же разряд всех слов. При необходимости выделения отдельных разрядов среза лишние позиции допустимо маскировать. Каждый разряд среза в АП снабжен собственным процессорным элементом, что позволяет между считыванием информации и ее записью производить необходимую обработку, то есть параллельно выполнять операции арифметического сложения, поиска, а также эмулировать многие черты матричных ВС.
Ассоциативные ВС – ВС класса SIMD, в основе которой лежит ассоциативный процессор. Таким образом, ассоциативные ВС представляют собой n процессорных элементов ПЭ (вертикальный разрядный срез памяти), как правило, последовательной поразрядной обработки для каждой из ячеек памяти. Операция осуществляется одновременно всемиnПЭ. Все или часть элементарных последовательных ПЭ могут синхронно выполнять операции над всеми ячейками или над выбранным множеством слов ассоциативной памяти.
Пример ассоциативной ВС – система STARAN, разработанная Goodyear Aerospace Corporation в 1972 году.
Систолические структуры
В фон-неймановских машинах данные, считанные из памяти, однократно обрабатываются в процессорном элементе, после чего снова возвращаются в память. В систолических структурах данные на своем пути, от считывания из памяти до возвращения обратно, пропускаются через как можно большее число ПЭ.
Если провести параллель в физиологии, то систолы больше всего напоминают систему сосудов и сердце, которое постоянно посылает кровь во все артерии, сосуды и капилляры тела.
Систолические системы являются очень специализированными вычислителями и производятся в основном под конкретную задачу. Фактически, задача построения систолического вычислителя сводится к построению аппаратного конвейера, имеющего достаточно большое время получения результата (т.е. большое количество ступеней) но при этом сравнительно маленькое время между последовательной выдачей результатов, так как значительное количество промежуточных значений обрабатывается на разных ступенях конвейера.
Рассмотрим в качестве примера систолическую структуру, выполняющую процесс векторного умножения матриц. В основе схемы лежит ритмическое прохождение двух потоков данных xi и уj навстречу друг другу. Последовательные элементы каждого потока разделены одним тактовым периодом, чтобы любой из них мог встретиться с любым элементом встречного потока. Вычисления выполняются параллельно в процессорных элементах, каждый из которых реализует один шаг в операции вычисления скалярного произведения (IPS, Inner Product Step) и носит название IPS-элемента.
Значение увх, поступающее на вход ПЭ, суммируется с произведением входных значений xвх и авх. Результат выходит из ПЭ как увых. 3начение хвх, кроме того, для возможного последующего использования остальной частью массива транслируется через ПЭ без изменений и покидает его в виде xвых.
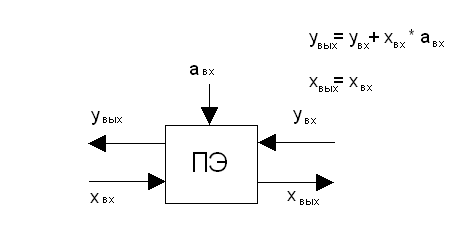
Функциональная схема IPS-элемента
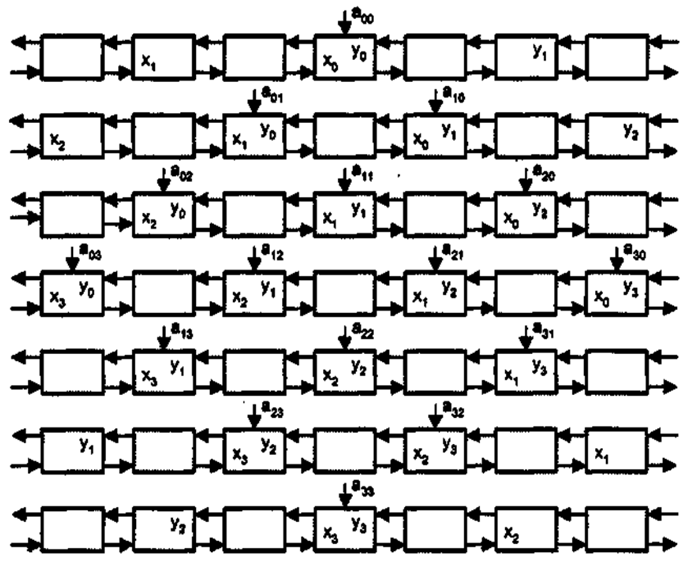
Процесс векторного умножения матриц
Систолическая структура — это однородная вычислительная среда из процессорных элементов, совмещающая в себе свойства конвейерной и матричной обработки и обладающая следующими особенностями:
· вычислительный процесс в систолических структурах представляет собой непрерывную и регулярную передачу данных от одного ПЭ к другому без запоминания промежуточных результатов вычисления;
· каждый элемент входных данных выбирается из памяти однократно и используется столько раз, сколько необходимо по алгоритму, ввод данных осуществляется в крайние ПЭ матрицы;
· образующие систолическую структуру ПЭ однотипны и каждый из них может быть менее универсальным, чем процессоры обычных многопроцессорных систем;
· потоки данных и управляющих сигналов обладают регулярностью, что позволяет объединять ПЭ локальными связями минимальной длины;
· алгоритмы функционирования позволяют совместить параллелизм с конвейерной обработкой данных;
производительность матрицы можно улучшить за счет добавления в нее определенного числа ПЭ, причем коэффициент повышения производительности при этом линеен.
В настоящее время достигнута производительность систолических процессоров порядка 1000 млрд операций/с.

