 2015-07-04
2015-07-04 1231
1231Ентропія джерела повідомлень визначається формулою


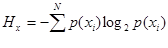
де: 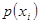 - ймовірність появи xi з N символів алфавіту джерела. N – об’єм алфавіту джерела.
- ймовірність появи xi з N символів алфавіту джерела. N – об’єм алфавіту джерела.
Теорема Шенона для каналу без завад: в каналі зв’язку без завад можна так перетворити послідовність символів джерела, що середня довжина символів коду буде як завгодно близька до ентропії джерела повідомлень.
Ентропія H(x) виступає кількісною мірою різноманітності повідомлень джерела і є його основною характеристикою. Ентропія джерела максимальна, якщо ймовірності повідомлень є рівними. Якщо одне повідомлення достовірне, а інші неможливі, то H(x)=0. Одиниця виміру ентропії – 1 біт. Це та невизначеність, коли джерело має однакову ймовірність двох можливих повідомлень (0 або 1).
Ентропія H(x) визначає середню кількість двійкових знаків, необхідних для кодування початкових символів джерела. Наприклад, для російських букв n=32=25. Якщо вони подаються рівномірно і незалежні між собою, то H(x)<5. Для російського літературного тексту H(x)=1.5 біт, для віршів H(x)=1 біт, а для телеграм H(x)=0.8 біт. Це означає, що при певному способі кодування на передачу букви може бути затрачено відповідно 1.5, 1, 0.8 двійкових символів.
Якщо символи нерівноімовірні і залежні, то ентропія буде менша від свого максимального значення Нmax(x)=log2N. При цьому можливе деяке більш економне (ефективне) кодування, при якому на кожен символ буде в середньому затрачено n*=H(x) символів коду. Коефіцієнт надлишковості визначається такою формулою
Кнадл=1-H(x)/Hmax(x)
Для характеристики досягнутого стиснення використовують коефіцієнт стиснення
Кстисн=Lпочат/Lстисн
Можна показати, що Кнадл>Кстисн.
Різні методи оптимального кодування базуються на зменшенні надлишковості викликаної неоднаковою апріорною ймовірностю символів або залежністю між порядком надходження символів.
В першому випадку для кодування використовується нерівномірний код - більш ймовірні символи мають коротший код, а менш ймовірні – довший.
В другому випадку переходять від кодування окремих символів до кодування їх груп. При цьому здійснюється укрупнення алфавіту джерела, через те N зростає. Загальна надлишковість укрупненого алфавіту при цьому не міняється. Однак, зменшення надлишковості обумовлене зменшенням різниці ймовірностей різних груп символів. Таким чином, процес кодування зводиться до двох операцій: укрупнення алфавіту і кодування оптимальним нерівномірним кодом.
Стиснення буває із втратами і без втрат. Втрати допустимі при стисненні аудіо-та відеоінформації (наприклад, MPEG - 20 до 1; MPEG3 - 100 до 1; TIFF - 10до 1 при 10% втрат, 100 до 1 при 20% втрат і т.д.).








