2015-08-21
2015-08-21 392
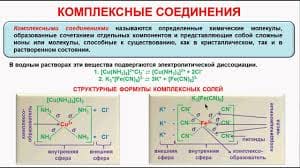
392Таблицыпредназначены для сбора и регистрации различного рода статистической информации. Каждая таблица объявляется следующей командой:
<Имя таблицы> TABLE A,B,C,D
A- имя СЧА, распределение которого по диапазонам требуется показать в таблице (аргумент таблицы, табулируемая величина);
Возможно использование следующих СЧА:
Q – длина очереди;
QA – средняя длина очереди;
QM – максимальная длина очереди;
QT – время пребывания транзакта в очереди, включая нулевые входы;
QX – время пребывания транзакта в очереди без нулевых входов.
B- верхняя граница первого диапазона аргумента таблицы;
C- шаг таблицы (разность между верхней и нижней границей каждого диапазона);
D- количество диапазонов.

Рис. 4. Ось действительных значений и ее разделение на ряд интервалов таблицы.
Регистрация значения СЧА, заданного в операнде А при объявлении таблицы, производится при прохождении транзакта через следующий оператор:
TABULATE A
A – имя таблицы.
Данный оператор указывается в тексте модели в том месте, где требуется получить данные о значении табулируемой величины. В файле стандартной статистики информация будет представлена в таком виде:
· TABLE – имя таблицы
· MEAN – среднее значение табулируемой величины
· STD. DEV. – среднеквадратическое отклонение
· RANGE – границы интервалов; нижний и верхний пределы частотного класса
· RETRY –количество транзактов, ожидающих выполнения специальных условий
· FREQUENCY – количество попаданий; суммарная величина, формируемая при попадании табулируемого аргумента в указанные границы
· CUM, % - накопленная часть; величина частоты в процентах к общему количеству значений табулируемого аргумента