 2015-09-07
2015-09-07 221
221Число всех перестановок без повторений равно: Pn = n!
Число всех размещений без повторений равно:
А 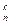 = n(n – 1)(n – 2)×××(n – m + 1).
= n(n – 1)(n – 2)×××(n – m + 1).
Число всех сочетаний без повторений равно: 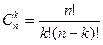 .
.
Классическое определение вероятности: Р(А) = 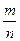 .
.
Свойства вероятности:
10. Р(W) = 1, где W - полная группа событий.
20. Вероятность невозможного события равна 0, а достоверного события равна 1. Следовательно, 0 £ Р(А) £ 1.
30. Р(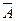 ) = 1 – Р(А), где и А – противоположные события.
) = 1 – Р(А), где и А – противоположные события.
Теорема сложения для двух несовместных событий: Р(А+В) = Р(А)+Р(В), для n попарно несовместных событий:
Р(А1+А2+…+Аn) = Р(А1)+Р(А2)+…+Р(Аn).
Теорема умножения для двух зависимых событий Р(АВ) = Р(А)×Р(А/В), для n зависимых: Р(А1А2×××Аn)=Р(А1)Р(А2/A1)P(A3/A1A2)×××Р(Аn/A1A2×××An-1).
Теорема умножения для двух независимых событий: Р(АВ) = Р(А)×Р(В), для n независимых: Р(А1А2×××Аn)=Р(А1)Р(А2)×××Р(Аn).
Вероятность появления хотя бы одного события из n независимых событий А1, А2, …, Аn равна: Р(А) = 1 - q1 q2 ×××qn, где рi = Р(Аi), q i = 1 – p i.
Формула полной вероятности: Р(А) = Р(Н1)Р(А/H1) + P(H2)P(A/H2) + … + +P(Hn)P(A/Hn), где Нi – попарно-несовместные, образующие полную группу события (гипотезы).
Формула Байеса: Р(А/H i) = 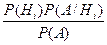 , где Р(А) вычисляют по формуле полной вероятности.
, где Р(А) вычисляют по формуле полной вероятности.
Формула Бернулли: Рn (k)=С 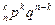 , где q = 1 – p.
, где q = 1 – p.
Наивероятнейшее число появлений k0 события А в n испытаниях:
np – q 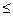 k0 np + p.
k0 np + p.
Локальная теорема Лапласа: Pn(k) 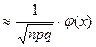 , где q = 1-p, х =
, где q = 1-p, х = 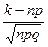 , значения функции j(х) см. в таблице приложения 1.
, значения функции j(х) см. в таблице приложения 1.
Интегральная теорема Лапласа: Рn(k1≤ k ≤ k2) ≈ Ф(х2) – Ф(х1), где х1 = 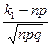 , х2 =
, х2 = 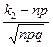 , значения функции Ф(х) см. в таблице приложения 2.
, значения функции Ф(х) см. в таблице приложения 2.
Законом распределения дискретной случайной величины:
| Х | x1 | x2 | … | хn |
| P(X) | p1 | p2 | … | pn |
причем р1 + р2 + … + рn = 1.
Математическое ожидание дискретной случайной величины:
М(Х)=х1р1 + х2р2 + … +хnpn.
Дисперсия дискретной случайной величины: D(X) = M(X – M(X))2 или более простая формула D(X) = M(X)2 – [M(X)]2.
Средне квадратическое отклонение: s(Х) = 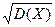 .
.
Функцией распределения непрерывной случайной величины (НСВ): F(x) = P (X < x), причем 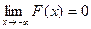 и
и 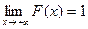 .
.
Плотность распределения непрерывной случайной величины: f(x)=F/(x), следовательно, 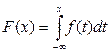 .
.
Свойства плотности распределения:
1. f (x) ≥ 0 для всех х.
2. 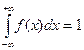 .
.
Математическое ожидание НСВ: 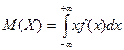 .
.
Дисперсия НСВ: D(X)= 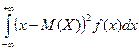 или D(X)=
или D(X)= 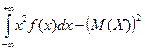
Среднее квадратическое отклонение НСВ: s(Х) = .
Вероятность того, что нормально распределенная случайная величина примет значение, принадлежащее интервалу (a; b), равна:
Р(a<x<b) = Ф 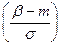 - Ф
- Ф 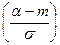 , а вероятность того, абсолютная величина отклонения меньше положительного числа d равна: Р(|x – m| < d) = 2Ф
, а вероятность того, абсолютная величина отклонения меньше положительного числа d равна: Р(|x – m| < d) = 2Ф 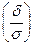 .
.
Выборочная средняя: 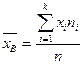 , где n=n1 + n2 +…+nk – объем выборки.
, где n=n1 + n2 +…+nk – объем выборки.
Выборочная дисперсия: 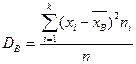 , n – объем выборки.
, n – объем выборки.
Выборочное среднее квадратическое отклонение: sВ = 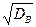 .
.
Теорема: DB= 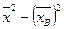 , где
, где 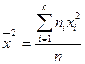 .
.
Доверительный интервал, покрывающий неизвестный параметр а (математического ожидания нормального распределения) при известном s, 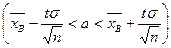 где
где 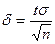 - точность оценки, n – объем выборки; t определяют из равенства Ф(t)=
- точность оценки, n – объем выборки; t определяют из равенства Ф(t)= 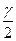 (по таблице приложения 2 находят аргумент t, которому соответствует значение функции Лапласа, равное g/2).
(по таблице приложения 2 находят аргумент t, которому соответствует значение функции Лапласа, равное g/2).
Если же s неизвестно, то доверительный интервал, покрывающий неизвестный параметр а с надежностью g, примет вид: 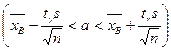 , где tg можно определить по таблице приложения 3 по заданным n и g, s =
, где tg можно определить по таблице приложения 3 по заданным n и g, s = 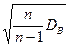 - «исправленное» среднее квадратическое отклонение.
- «исправленное» среднее квадратическое отклонение.
Метод произведений. Составляют расчетную таблицу вида:
| хi | ni | ui | niui | niu 
|
1. В 1ом столбце записывают выборочные (первоначальные) варианты в возрастающем порядке.
2. Во 2ом - записывают частоты этих вариант.
3. В 3ем – записывают условные варианты 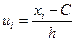 (практически, в клетках над ui=0 по порядку пишут числа -1, -2, -3, …, а в клетках под ним – числа 1, 2, 3, …
(практически, в клетках над ui=0 по порядку пишут числа -1, -2, -3, …, а в клетках под ним – числа 1, 2, 3, …
4. В 4ом – вычисляют произведения niui.
5. В 5ом – вычисляют произведения niu .
6. Далее суммируют вычисления по столбцам, записывая результаты снизу.
7. Вычисляют условные моменты 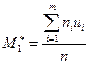 ,
, 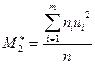 и выборочные среднюю
и выборочные среднюю 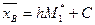 , дисперсию
, дисперсию 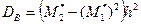 и среднее квадратическое отклонение sВ = .
и среднее квадратическое отклонение sВ = .
Для проверки нулевой гипотезы Н0={генеральная совокупность распределена нормально} при уровне значимости a с помощью критерия согласия Пирсона удобно пользоваться следующим алгоритмом:
1. Вычисляют теоретические частоты n 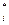 =
=  , где n – объем выборки; h – шаг выборки; sВ - выборочное среднее квадратическое отклонение; zi=
, где n – объем выборки; h – шаг выборки; sВ - выборочное среднее квадратическое отклонение; zi= 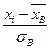 (
(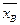 - выборочная средняя); j(z)=
- выборочная средняя); j(z)= 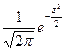 - плотность нормированного нормального распределения (значения см. приложение 1).
- плотность нормированного нормального распределения (значения см. приложение 1).
2. Вычисляют 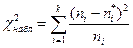 (
(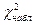 - значение критерия, вычисленное по данным наблюдений).
- значение критерия, вычисленное по данным наблюдений).
3. По таблице критических точек распределения 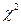 (см. приложение 4) по заданному уровню значимости a и числу степеней свободы k = s – 3 (s – число групп выборки) находим
(см. приложение 4) по заданному уровню значимости a и числу степеней свободы k = s – 3 (s – число групп выборки) находим 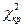 (a; k).
(a; k).
4. Если < , то нет оснований отвергнуть нулевую гипотезу Н0; если > , то нулевую гипотезу Н0 отвергают.
Выборочное уравнение прямой линии регрессии Y на Х по
сгруппированным данным имеет вид: 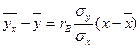 .
.
Здесь: 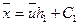 ,
, 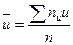 , h1 – шаг варианты Х;
, h1 – шаг варианты Х; 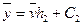 ,
, 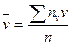 , h2 – шаг варианты Y, n – объем выборки; sх = suh1, su =
, h2 – шаг варианты Y, n – объем выборки; sх = suh1, su = 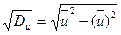 ,
, 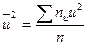 ; sy = svh2, sv =
; sy = svh2, sv = 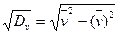 ,
, 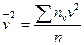 ; rB =
; rB = 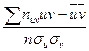 .
.
Метод нахождения 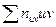
Для этого составляют корреляционную таблицу в условных вариантах, после чего составляют специальную таблицу:
1. В каждой клетке, в которой nuv ¹ 0, в правом верхнем углу записывают произведение nuv на u.
2. Складывают все числа, помещенные в этих правых верхних углах и их суммы записывают в столбец U.
3. Умножают варианту v на U по строкам и записывают результаты в последнем столбце vU.
4. Суммируют элементы последнего столбца. Полученная сумма и равна .
5. Для контроля аналогичные вычисления производят по столбцам (в левых нижних углах клеток, в которых nuv ¹ 0).








