2015-09-06
2015-09-06 231
231В ряде экономических и производ. задач необходимо учитывать изменение моделируемого процесса во времени и влияние времени на критерий оптимальности. Для решения подобных задач используется динамическое программирование (дп).
Дп – это метод оптимизации многошаговых или многоэтапных процессов, критерий эффективности которых обладает свойством:
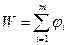
где W – показатель эффективности задачи в целом,
ji (i=1,…,m) – показатели эффективности отдельных шагов задачи.
Переменная xi, от которой зависит управление на i-шаге (i=1,…,m) и, следовательно, выигрыш в целом, называется шаговым управлением.
Управлением процессом в целом (х) называется последовательность шаговых управлений х=(х1,…,хm).
Оптимальное управление х* - это значение управления х, при котором значение W(x*) является максимальным (или минимальным, если требуется уменьшить проигрыш): W*=W(x*)=max{W(x)}, xÎX, где Х – область допустимых управлений.
Оптимальное управление определяется последовательностью шаговых управлений: х*=(х1*,…,хm*).
В основе метода динамического программирования лежит принцип оптимальности Беллмана: управление на каждом шаге надо выбирать так, чтобы оптимальной была сумма выигрышей на всех оставшихся до конца процесса шагах, включая выигрыш на данном шаге.
Введем следующие обозначения:
s – состояние процесса.
Si – множество возможных состояний процесса перед i-м шагом.
Wi – выигрыш с i-го шага до конца процесса, (i=1,…,m).
Математическая модель динамического программирования составляется в следующем порядке:
1. Разбиение задачи на шаги (этапы). Шаг не должен быть мелким (чтобы не увеличивать число расчетов) и не д.б. слишком большим (чтобы не усложнять процесс оптимизации).
2. Выбор переменных, характеризующих состояние s моделируемого процесса перед каждым шагом, и выявление накладываемых на них ограничений.
3. Определение множества шаговых управлений xi, (i=1,…,m) и налагаемых на них ограничений, т.е. области допустимых управлений Х.
4. Определение выигрыша ji(s, xi), который принесет на каждом шаге управление xi, если система перед этим находилась в состоянии s.
5. Определение состояния s’, в которое переходит система из состояния s под влиянием управления xi
s’=fi(s, xi), где fi – функция перехода на i-м шаге из состояния s в s’.
6. Составление уравнения, определяющего условный оптимальный выигрыш на последнем шаге, для состояния s моделируемого процесса 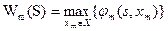 .
.
7. Составление основного функционального уравнения динамического программирования, определяющего условный оптимальный выигрыш для данного состояния s с i-го шага и до конца процесса через уже известный условный оптимальный выигрыш с (i+1)-го шага и до конца:
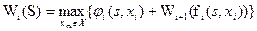
В данном уравнении уже известную функцию Wi+1(s), характеризующую условный оптимальный выигрыш c (i+1)-го шага до конца процесса, вместо состояния s подставлено новое состояние s’=fi(s,xi), в которое система переходит на i-м шаге под влиянием управления xi.
Структура модели динамического программирования отличается от статической модели ЛП. В ЛП управляющие переменные – это одновременно и переменные состояния моделируемого процесса, а динамических моделях отдельно вводятся переменные управления xi, и переменные, характеризующие состояние s под влиянием управления.