 2015-09-06
2015-09-06 470
470База даних опитування студентів 2007 р.
Наприклад:
- змінна v2 з розподілом років народжень респондентів (ряд натуральних чисел);
- змінна v5 з розподілом настанов респондентів щодо економічних змін протягом останнього року в Україні, проміряних шкалою від 1 до 5; тощо.
Проте буває співвідношення:
змінна = 2 або більша кількість числових вибірок.
Сортуємо базу даних за змінною v3 (стать).
Бачимо, що в середовищі, наприклад, змінної v5 (оцінка економічних змін) утворилися, фактично, дві числові вибірки, розподіл значень в межах кожної з них має свої особливості, наприклад, кожна з них може мати відмінні одна від одної середні значення.
ЗАЛЕЖНІ ЧИСЛОВІ ВИБІРКИ.
Залежні числові вибірки утворюються в середовищі 2-х або більшої кількості змінних при виконанні двох умов:
1. Значення змінних є виміряні ідентичними шкалами вимірювання.
2. Зміст змінних стосується єдиного для них соціального факту (явища).
Приклад:
змінна v5 (загальна оцінка суспільних змін в Україні: економічних);
змінна v6 (загальна оцінка суспільних змін в Україні: політичних).
ВПРАВА. Студенти розбиваються на підгрупи. Кожна з них конструює і презентує приклад 2-х залежних числових вибірок.
НЕЗАЛЕЖНІ ЧИСЛОВІ ВИБІРКИ.
Незалежні числові вибірки.
Якщо здійснити сортування бази даних за значеннями/ категоріями фактора (незалежної змінної), то в середовищі показника (залежної змінної) утвориться декілька незалежних між собою числових вибірок.
Приклад:
За результатами сортування бази даних за змінною v3 (стать – факторна/ незалежна змінна) в середовищі змінної v5 (оцінка економічних змін – показникова/ залежна змінна) утворилися дві незалежні числові вибірки, розподіл значень в межах кожної з них має свої особливості, наприклад, кожна з них може мати відмінні одна від одної середні значення.
ВПРАВА. Студенти розбиваються на підгрупи. Кожна з них конструює і презентує приклад 2-х незалежних числових вибірок.
Коли порівнюються між собою середні значення певних числових вибірок, то спочатку висувається Гіпотеза 0: "Вибірки є подібними одна до одної (їхні значення, зокрема, середні, розподіляються подібно, тт. за певними подібними для них законами)".
Потім формулюється Гіпотеза 1 (альтернативна) „Вибірки відрізняються одна від одної (їхні значення, зокрема, середні, розподіляються відмінно, тт. за певними відмінними для них законами)”.
Потім обчислюються середні піддослідних числових вибірок та проводиться тест на значущість помилки для некоректного заперечення Гіпотези 0 (ймовірність помилки, здійснюючи інтерпретацію Гіпотези 0 як хибної, в той час, коли вона є коректною (помилка 1-го роду, типу alfa)).
| Порівняння середніх двох залежних вибірок | Paired-Samples T Test |
ВЗІРЕЦЬ ДЛЯ ВИКОНАННЯ САМОСТІЙНОЇ РОБОТИ № 4
База даних: Kyiv-91
Змінна v73: в якості кого респонденти готові допустити в Київ – білоруси
Змінна v74: в якості кого респонденти готові допустити в Київ – росіяни
А. Аналіз структури шкали вимірювання.
Шкала вимірювання для обидвох змінних:

1. Дослідницьке запитання: “Чи відрізнялося ставлення киян 1991 р. до білорусів і росіян в контексті готовності допустити представників зазначених національностей в Київ?”
2. РГД: “Ставлення киян 1991 р. до білорусів і росіян було однаковим в контексті готовності допустити представників зазначених національностей в Київ.”
3. Емпірична апробація РГД.
3.1. Гіпотеза-0. Середні значення відповідних числових вибірок є однаковими. М1 = М2.
3.2. Гіпотеза-1. Середні значення відповідних числових вибірок статистично значимо відрізняються одне від одного. М1 ≠ М2.
3.3. Перевірка статистичних гіпотез.
Analyze – Compare Means – Paired-Samples T Test. Вибираємо по черзі змінні v73 та v74 зі загального списку змінних – переводимо їх до тестового вікна – OK.
Отримали 2 звітні таблиці.
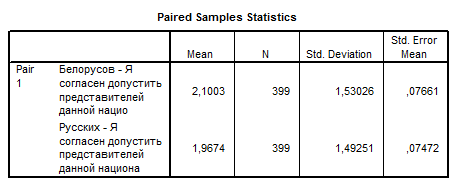
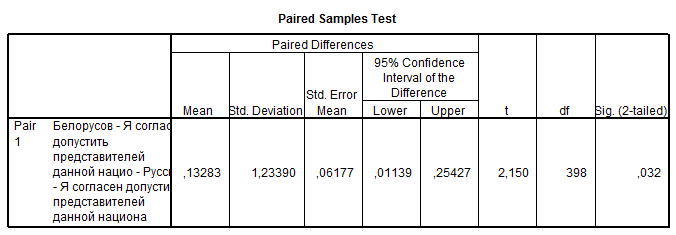
M1 – M2 = 0,13283.
q (Sig. (2-tailed)) = 0,032. 95% довірчий інтервал: [0,01139; 0,25427].
| Інтервали | Ймовірність помилки (q) | ДІЯ: | Різниця між середніми вибірок | |
| формулювання | символ | |||
| 0.00 ≤ q < 0.01 | Ймовірність помилки при відхилянні Гіпотези-0 є дуже малою (значимою на рівні 0.01) | відкидаємо Гіпотезу-0 | Середні значення вибірок статистично значимо відрізняються одна від одної (різниця є значущою на рівні 0.01) | ** |
| 0.01 ≤ q < 0.05 | Ймовірність помилки при відхилянні Гіпотези-0 є малою (значимою на рівні 0.05) | Середні значення вибірок статистично значимо відрізняються одна від одної (різниця є значущою на рівні 0.05) | * | |
| 0.05 ≤ q ≤ 1.00 | Ймовірність помилки при відхилянні Гіпотези-0 є великою | приймаємо Гіпотезу-0 | Різниця між середніми значеннями вибірок є статистично незначимою | ns |
Ймовірність помилки при відхилянні Гіпотези 0 є малою (значимою на рівні 0.05). Отже, Гіпотезу-0 відхиляємо як фальшиву, а Гіпотезу-1 приймаємо як коректну. Середні значення вибірок статистично значимо відрізняються одна від одної (різниця є значущою на рівні 0.05).
3.4. РГД – фальшива.
4. Відповідь на дослідницьке запитання: “Отже, за результатами аналізу емпіричних даних можна з довірчою ймовірністю 0,95 зробити висновок, що у Киян в 1991 р. соціальна дистанція до білорусів була статистично значущо більшою, ніж соціальна дистанція до росіян (різниця між відповідними середніми була значимою на рівні 0,05), але ця відмінність була досить невеликою – не менше ніж 0,011 та не більше ніж 0,254 за загальною шкалою, що вимірює соціальну дистанцію від 1 до 7.
| Порівняння середніх двох незалежних вибірок | Independent-Samples T Test |
ВЗІРЕЦЬ ДЛЯ ВИКОНАННЯ САМОСТІЙНОЇ РОБОТИ № 5
База даних: Kyiv-91
Змінна v172: партійність респондентів;
Змінна v173: Середньомісячний дохід в сім’ї респондента з розрахунку на одну людину.
А. Аналіз структури шкал вимірювання.
Шкала вимірювання для змінної v172:

Для вимірювання змінної v173 було використано універсальну метричну шкалу вимірювання грошових доходів людей, яка має початкове значення “0”.
1. Дослідницьке запитання: “Як відрізнявся середньомісячний дохід киян, які 1991 року були членами КПРС або кандидатами в члени КПРС, від середньомісячного доходу киян, які 1991 року були безпартійними?”
2. РГД: “Середньомісячний дохід киян, які 1991 року були членами КПРС або кандидатами в члени КПРС, був значно вищим від середньомісячного доходу киян, які 1991 року були безпартійними.”
3. Емпірична апробація РГД.
3.1. Гіпотеза-0. Середні значення відповідних числових вибірок є однаковими. М1 = М4.
3.2. Гіпотеза-1. Середні значення відповідних числових вибірок значимо відрізняються одне від одного. М1 ≠ М4.
3.3. Перевірка статистичних гіпотез.
Analyze – Compare Means – Independent-Samples T Test. Groupping Variable – v172; Define Groups – Use specified values (1 – члени КПРС або кандидати, 4 – безпартійні) – Continue. Test Variable – v2. OK
Отримуємо 2 звітні таблиці.
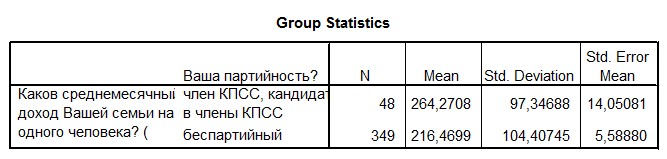
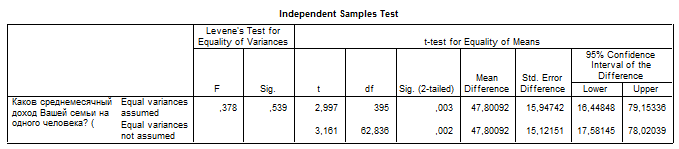
M1 – M4 = 47,80092. Для визначення ступеня відмінності між середніми вибірок використовуємо нижній рядок таблиці Independent Samples Test – Equal variances not assumed (однаковість дисперсій не передбачена).
q (Sig. (2-tailed) = 0,002. 95% довірчий інтервал: [17,6; 78,0].
| Інтервали | Ймовірність помилки (q) | ДІЯ: | Різниця між середніми вибірок | |
| формулювання | символ | |||
| 0.00 ≤ q < 0.01 | Ймовірність помилки при відхилянні Гіпотези-0 є дуже малою (значимою на рівні 0.01) | відкидаємо Гіпотезу-0 | Середні значення вибірок статистично значимо відрізняються одна від одної (різниця є значущою на рівні 0.01) | ** |
| 0.01 ≤ q < 0.05 | Ймовірність помилки при відхилянні Гіпотези-0 є малою (значимою на рівні 0.05) | Середні значення вибірок статистично значимо відрізняються одна від одної (різниця є значущою на рівні 0.05) | * | |
| 0.05 ≤ q ≤ 1.00 | Ймовірність помилки при відхилянні Гіпотези-0 є великою | приймаємо Гіпотезу-0 | Різниця між середніми значеннями вибірок є статистично незначимою | ns |
Ймовірність помилки при відхилянні Гіпотези-0 є дуже малою (значимою на рівні 0.01). Отже, Гіпотезу-0 відхиляємо як фальшиву, а Гіпотезу-1 приймаємо як коректну. Середні значення вибірок статистично значимо відрізняються одна від одної (різниця є значущою на рівні 0.01).
3.4. РГД – коректна.
4. Відповідь на дослідницьке запитання: “На основі отриманих емпіричних даних можна з довірчою ймовірністю 0,95 стверджувати, що середньомісячний дохід киян, які 1991 року були членами КПРС або кандидатами в члени КПРС, був значно вищим від середньомісячного доходу киян, які 1991 року були безпартійними. Зазначена відмінність була значимою на рівні 0,01, і була не меншою ніж 17,6 крб., але не більшою ніж 78,0 крб.”








