 2015-09-06
2015-09-06 998
998Сжатие Хаффмана - статистический метод сжатия, который уменьшает среднюю длину кодового слова для символов алфавита. Код Хаффмана является примером кода, оптимального в случае, когда все вероятности появления символов в сообщении - целые отри- цательные степени двойки. Код Хаффмана может быть построен по следующему алгоритму:
1. Выписываем в ряд все символы алфавита в порядке возрастания или убывания вероятности их появления в тексте;
2. Последовательно объединяем два символа с наименьшими вероятностями появления в новый составной символ, вероятность появления которого полагается равной сумме вероятностей составляющих его символов. В конце концов, мы построим дерево, каждый узел которого имеет суммарную вероятность всех узлов, находящихся ниже него;
3. Прослеживаем путь к каждому листу дерева помечая направление к каждому узлу (например, направо - 1, налево - 0).
Поясним создание дерева с использованием иллюстраций:
A B C D E10 5 8 13 10 B C A E D5 8 10 10 13 A E BC D10 10 13 13 BC D AE13 13 20 AE BCD20 26 AEBCD46Таким образом, построено дерево
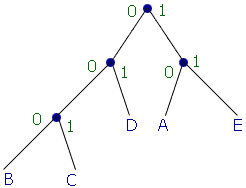
Теперь, если в тексте встречается, например, символ "d", то вместо того, чтобы выделять этому символу байт, после сжатия символ займет всего 2 бита (01).
При использовании адаптивного кодирования Хаффмена усложнение алгоритма состоит в необходимости постоянной корректировки дерева и кодов символов основного алфавита в соответствии с изменяющейся статистикой входного потока.
Методы Хаффмена дают достаточно высокую скорость и умеренно хорошее качество сжатия. Эти алгоритмы давно известны и широко применяется как в программных (всевозможные компрессоры, архиваторы и программы резервного копирования файлов и дисков), так и в аппаратных (системы сжатия "прошитые" в модемы и факсы, сканеры) реализациях.
Эвристические (словарные) алгоритмы сжатия (типу LZ, LZW), как правило, ищут в файле строки, что повторяются и строят словарь фраз, которые уже встречались. Обычно такие алгоритмы имеют целый ряд специфических параметров (размер буфера, максимальная длина фразы и т.п.), подбор которых зависит от опыта автора работы, и эти параметры добираются таким образом, чтобы достичь оптимального соотношения времени работы алгоритма, коэффициента сжатия и перечня файлов, которые хорошо сжимаются.








