 2015-10-13
2015-10-13 960
960где (address, count, datatype) описывают буфер приемника, как в случае MPI_Send; sourse- номер процесса-отправителя сообщения в группе, определяемой коммуникатором comm; status- содержит информацию относительно фактического размера сообщения, источника и тэга. Sourse, tag, countфактически полученного сообщения восстанавливаются на основе status.
Передача и прием сообщений процессами - это базовый коммуникационный механизм MPI. Основными операциями парного обмена являются операции send (послать) и receive (получить). Их использование иллюстрируется следующим примером:
#include "mpi.h"
main(argc, argv) {
int argc;
char **argv;
{ char message[20];
int myrank;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
if (myrank == 0) /* код для процесса 0 */
{ strcpy (message, "Hello, there");
MPI_Send(message,strlen(message),MPI_CHAR, 1,99, MPI_COMM_WORLD);
}
else /* код для процесса 1 */
{ MPI_Recv(message, 20, MPI_CHAR, 0, 99, MPI_COMM_WORLD, &status);
printf("received:%s:\n", message);
} MPI_Finalize();
}
В этом примере процесс с номером 0 (myrank = 0) посылает сообщение процессу с номером 1, используя операцию посылки MPI_Send. Эта операция описывает буфер посылающего процесса, из которого извлекаются посылаемые данные. В приведенном примере посылающий буфер состоит из накопителя в памяти процесса 0, содержащего переменную message. Размещение, размер и тип буфера посылающего процесса описываются первыми тремя параметрами операции send. Посланное сообщение будет содержать 13 символов этой переменной. Операция посылки также связывает с сообщением его атрибуты. Атрибуты определяют номер процесса-получателя сообщения и содержат различную информацию, которая может быть использована операцией receive, чтобы выбрать определенное сообщение среди других. Последние три параметра операции посылки описывают атрибуты посланного сообщения. Процесс 1 (myrank = 1) получает это сообщение, используя операцию приема MPI_Recv, и данные сообщения записываются в буфер процесса-получателя. В приведенном примере буфер получателя состоит из накопителя в памяти процесса один, содержащего строку message. Первые три параметра операции приема описывают размещение, размер и тип буфера приема. Следующие три параметра необходимы для выбора входного сообщения. Последний параметр необходим для возврата информации о только что полученном сообщении.
Ранее говорилось, что для написания большинства программ достаточно 6 функции, среди которых основными являются функции обмена сообщениями типа "точка-точка" (в дальнейшем - функции парного обмена). Программу вычисления можно написать с помощью функций парного обмена, но функции, относящиеся к классу коллективных обменов, как правило, будут эффективнее. В MPI используются коллективные операции, которые можно разделить на два вида:
• операции перемещения данных между процессами. Самый простой из них - широковещание (broadcasting), MPI имеет много и более сложных коллективных операций передачи и сбора сообщений;
• операции коллективного вычисления (минимум, максимум, сумма и другие, в том числе и определяемые пользователем операции).
В обоих случаях библиотеки функций коллективных операций строятся с использованием знания о преимуществах структуры машины, чтобы увеличить параллелизм выполнения этих операций.
В качестве примера параллельной программы, написанной в стандарте MPI для языка С, рассмотрим программу вычисления числа π. Число π можно определить следующим образом:
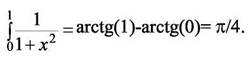
Вычисление интеграла затем заменяют вычислением суммы
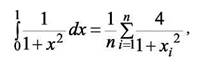
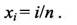
#include "mpi.h"
#include <math.h>
int main (int argc, char *argv[ ])
{ int n, myid, numprocs, i;
double mypi, pi, h, sum, x, t1, t2, PI25DT = 3.141592653589793238462643;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
while (1)
{
if (myid == 0) { printf ("Enter the number of intervals: (0 quits)");
scanf("%d",&n);
t1 = MPI_Wtime();
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
if(n == 0) break;
else
{ h =1.0/(double) n;
sum = 0.0;
for (i = myid +1; i <= n; i+= numprocs)
{ x = h * ((double)i - 0.5); sum+=(4.0/(1.0 + x*x));
}
mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0,
MPI_COMM_WORLD); if (myid == 0) { t2 = MPI_Wtime();
printf ("pi is approximately %.16f. Error is %.16f\n",pi, fabs(pi - PI25DT)); printf ("'time is %f seconds \n", t2-t1);
} } }
MPI_Finalize(); return 0; }
В программе после нескольких строк определения переменных следуют три строки, которые есть в каждой MPI-программе:
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
Обращение к MPI_Init должно быть первым обращением в MPI-программе, оно устанавливает "среду" MPI. В каждом выполнении программы может выполняться только один вызов MPI_Init.
Коммуникатор MPI_COMM_WORLD описывает состав процессов и связи между ними. Вызов MPI_Comm_size возвращает в numprocs число процессов, которые пользователь запустил в этой программе. Значение numprocs − размер группы процессов, связанной с коммуникатором MPI_COMM_WORLD. Процессы в любой группе нумеруются последовательными целыми числами, начиная с 0. Вызывая MPI_ Comm_rank, каждый процесс выясняет свой номер (rank) в группе, связанной с коммуникатором. Затем главный процесс (который имеет myid=0) получает от пользователя значение числа прямоугольников n:
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
Первые три параметра соответственно обозначают адрес, количество и тип данных. Четвертый параметр указывает номер источника данных (головной процесс), пятый параметр - название коммуникатора группы. Таким образом, после обращения к MPI_Bcast все процессы имеют значение n и собственные идентификаторы, что является достаточным для каждого процесса, чтобы вычислить mypi − свой вклад в вычисление π. Для этого каждый процесс вычисляет область каждого прямоугольника, начинающегося с myid +l.
Затем все значения mypi, вычисленные индивидуальными процессами, суммируются с помощью вызова Reduce:
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
Первые два параметра описывают источник и адрес результата. Третий и четвертый параметр описывают число данных и их тип, пятый параметр - тип арифметико-логической операции, шестой – номер процесса для размещения результата.
Затем по метке 10 управление передается на начало цикла. Этим пользователю предоставляется возможность задать новое n и повысить точность вычислений. Когда пользователь печатает нуль в ответ на запрос о новом n, цикл завершается, и все процессы выполняют:
MPI_Finalize();
после которого любые операции MPI выполняться не будут.
Функция MPI_Wtime() используется для измерения времени исполнения участка программы, расположенного между двумя включениями в программу этой функции.
Коллективные функции Bcast и Reduce можно выразить через парные операции Send и Recv. Например, для той же программы вычисления числа π операция Bcast для рассылки числа интервалов выражается через цикл следующим образом:
for (i=0; i<numprocs; i++)
MPI_Send(&n, 1, MPI_INT, i, 0, MPI_COMM_WORLD);
Параллельная MPI программа может содержать различные исполняемые файлы. Этот стиль параллельного программирования часто называется MPMD (множество программ при множестве данных) в отличие от программ SPMD (одна программа при множестве данных). SPMD не следует путать с SIMD. Вышеприведенная программа вычисления числа π относится к классу программ SPMD. Такие программы значительно легче писать и отлаживать, чем программы MPMD. В общем случае системы SPM и MPI могут имитировать друг друга:
1. Посредством организации единого адресного пространства для физически разделенной по разным процессорам памяти.
2. На SMP-машинах вырожденным каналом связи для передачи сообщений служит разделяемая память.
3. Путем использования компьютеров с разделяемой виртуальной памятью. Общая память как таковая отсутствует. Каждый процессор имеет собственную локальную память и может обращаться к локальной памяти других процессоров, используя "глобальный адрес". Если "глобальный адрес" указывает не на локальную память, то доступ к памяти реализуется с помощью сообщений, пересылаемых по коммуникационной сети.
Операции блокирующей передачи и блокирующего приема.
Блокирующая передача:








