 2015-10-22
2015-10-22 1956
1956Цель работы: изучить способы сортировки и поиска в массивах структур и файлах.
Краткие теоретические сведения
При обработке баз данных часто применяются массивы структур. Обычно база данных накапливается и хранится на диске в файле. К ней часто приходится обращаться, обновлять, перегруппировывать. Работа с базой может быть организована двумя способами.
1. Внесение изменений и поиск осуществляется прямо на диске, используя специфическую технику работы со структурами в файлах. При этом временные затраты на обработку данных (поиск, сортировку) значительно возрастают, но нет ограничений на использование оперативной памяти.
2. Считывание всей базы (или необходимой ее части) в массив структур. При этом обработка производится в оперативной памяти, что значительно увеличивает скорость, однако требует больших затрат памяти.
Наиболее частыми операциями при работе с базами данных являются «поиск» и «сортировка». При этом алгоритмы решения этих задач существенно зависят от того, организованы структуры в массивы или размещены на диске.
Обычно элемент данных (структура) содержит некое ключевое поле (ключ), по которому его можно найти. Ключом может служить любое поле структуры, например, фамилия, номер телефона или адрес. Основное требование к ключу в задачах поиска состоит в том, чтобы операция проверки на равенство была корректной, поэтому при поиске данных по ключу, имеющему вещественное значение, следует указывать не его конкретное значение, а интервал, в который это значение попадает.
Алгоритмы поиска
Предположим, что у нас имеется следующая структура:
struct Ttype {
type key; // Ключевое поле типа type
... // Описание других полей структуры
} * a; // Указатель для динамического массива структур
Задача поиска требуемого элемента в массиве структур a (размер n – задается при выполнении программы) заключается в нахождении индекса i_key, удовлетворяющего условию a [ i_key ]. key = f_key, key – интересующее нас поле структуры данных, f_key – искомое значение того же типа что и key. После нахождения индекса i_key обеспечивается доступ ко всем другим полям найденной структуры a [ i_key ].
Линейный поиск используется, когда нет никакой дополнительной информации о разыскиваемых данных, и представляет собой последовательный перебор всех элементов массива. Если поле поиска является уникальным, то поиск выполняется до обнаружения требуемого ключа или до конца, если ключ не обнаружен. Если же поле поиска не уникальное, приходится перебирать все данные до конца массива:
int i_key = 0, kod = 0;
for (i = 1; i < n; i++)
if (a[i].key == f_key) {
kod = 1;
// Обработка найденного элемента, например, вывод
i_key = i;
// break; – если поле поиска уникальное
}
if(kod == 0) // Вывод сообщения, что элемент не найден
Поиск делением пополам используется, если данные упорядочены по возрастанию (по убыванию) ключа key. Алгоритм поиска осуществляется следующим образом:
– берется средний элемент m;
– если элемент массива a [ m ]. key < f _ key, то все элементы i 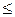 m исключаются из дальнейшего поиска, иначе – исключаются все элементы с индексами i>m.
m исключаются из дальнейшего поиска, иначе – исключаются все элементы с индексами i>m.
Приведем пример, реализующий этот алгоритм
int i_key = 0, j = n–1, m;
while(i_key < j) {
m = (i_key + j)/2;
if (а[m].key < f_key) i_key = m+1;
else j = m;
}
if (a[i_key].key!= key) return -1; // Элемент не найден
else return i;
Проверка совпадения a [ m ]. k = f _ key в этом алгоритме внутри цикла отсутствует, т.к. тестирование показало, что в среднем выигрыш от уменьшения количества проверок превосходит потери от нескольких «лишних» вычислений до выполнения условия i_key = j,
Алгоритмы сортировки
Под сортировкой понимается процесс перегруппировки элементов массива, приводящий к их упорядоченному расположению относительно ключа.
Цель сортировки – облегчить последующий поиск элементов. Метод сортировки называется устойчивым, если в процессе перегруппировки относительное расположение элементов с равными ключами не изменяется. Основное условие при сортировке массивов – это не вводить дополнительных массивов, т.е. все перестановки элементов должны выполняться в исходном массиве. Сортировку массивов принято называть внутренней, а сортировку файлов – внешней.
Методы внутренней сортировки классифицируются по времени их работы. Хорошей мерой эффективности может быть число операций сравнений ключей и число пересылок (перестановок) элементов.
Прямые методы имеют небольшой код и просто программируются, быстрые, усложненные методы требуют меньшего числа действий, но эти действия обычно более сложные, чем в прямых методах, поэтому для достаточно малых значений n (n £ 50) прямые методы работают быстрее. Значительное преимущество быстрых методов начинает проявляться при n ³ 100.
Среди простых методов наиболее популярны следующие.
1. Метод прямого обмена (пузырьковая сортировка):
for (i = 0; i < n–1; i++)
for (j = i+1; j < n; j++)
if (a[i].key > a[j].key) { // Переставляем элементы
r = a[i];
a[i] = a[j];
a[j] = r;
}
2. Метод прямого выбора:
for (i = 0; i < n–1; i++) {
m = i;
for (j = i+1; j < n; j++)
if (a[j].key < a[m].key) m = j;
r = a[m]; // Переставляем элементы
a[m] = a[i];
a[i] = r;
}
Реже используются: 3) сортировка с помощью прямого (двоичного) включения; 4) шейкерная сортировка (модификация пузырьковой).
К улучшенным методам сортировки относятся следующие.
1. Метод Д. Шелла (1959), усовершенствование метода прямого включения.
2. Сортировка с помощью дерева, метод HeapSort, Д.Уильямсон (1964).
3. Сортировка с помощью разделения, метод QuickSort, Ч.Хоар (1962), улучшенная версия пузырьковой сортировки, являющийся на сегодняшний день самым эффективным методом.
Идея метода разделения QuickSort в следующем. Выбирается значение ключа среднего m -го элемента x = a [ m ]. key. Массив просматривается слева – направо до тех пор, пока не будет обнаружен элемент a [ i ]. key > x. Затем массив просматривается справа – налево, пока не будет обнаружен элемент a [ j ]. key < x. Элементы a [ i ] и a [ j ] меняются местами. Процесс просмотра и обмена продолжается до тех пор, пока i не станет больше j. В результате массив оказывается разбитым на левую часть a [ L ],0 £ L £ j с ключами меньше (или равными) x и правую a [ R ], i £ R < n с ключами больше (или равными) x.
Алгоритм такого разделения очень прост и эффективен:
i = 0; j = n – 1; x = a[(L + R)/2].key;
while (i <= j) {
while (a[i].key < x) i++;
while (a[j].key > x) j--;
if (i <= j) {
r = a[i]; // Переставляем элементы
a[i] = a[j];
a[j] = r;
i++; j--;
}
}
Чтобы отсортировать массив, остается применять алгоритм разделения к левой и правой частям, затем к частям частей и так до тех пор, пока каждая из частей не будет состоять из одного единственного элемента. Алгоритм получается итерационным, на каждом этапе которого стоят две задачи по разделению. К решению одной из них можно приступить сразу, для другой следует запомнить начальные условия (номер разделения, границы) и отложить ее решение до момента окончания сортировки выбранной половины.
Сравнение методов сортировок показывает, что при n > 100 наихудшим является метод пузырька, метод QuickSort в 2-3 раза лучше, чем HeapSort, и в 3-7 раз, чем метод Шелла.

