2015-10-22
2015-10-22 521
521В этой главе мы узнали об указателях и о том, как можно применять их для конструирования структур данных. Рассмотрим, как указатели обрабатываются на машинном языке.
Предположим, что мы планируем написать программу на машинном языке, описанном в приложении В, которая выталкивает запись из стека, описанного ранее на рис. 7.10, и помещает эту запись в регистр общего назначения. Другими словами, мы хотим поместить в регистр содержимое ячейки памяти, находящейся на вершине стека. В нашем машинном языке есть две инструкции для записи в регистры — первая с кодом операции 2, и вторая с кодом операции 1. Вспомните, что в случае кода операции 2 поле операнда содержит данные, которые будут записаны, а в случае кода операции 1 в поле операнда содержится адрес данных, которые будут загружены в регистр.
Поскольку мы заранее не знаем содержимого записи стека, код операции 2 не подходит для выполнения нашей задачи. Более того, код операции 1 мы также использовать не можем, так как не знаем адреса данных, ведь адрес вершины стека изменяется по мере выполнения программы. Но мы знаем адрес указателя стека. Таким образом, нам известно расположение ячейки, содержащей адрес данных, которые мы хотим загрузить в регистр. Что нам требуется — это еще один код операции для записи в регистр, где операнд содержит адрес указателя на нужные данные.
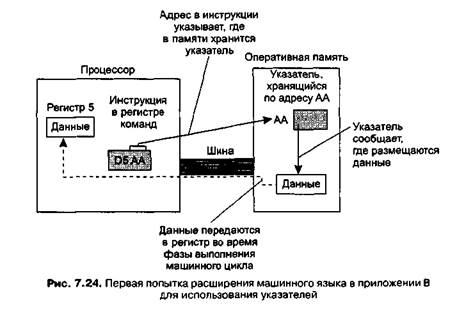
Для достижения этой цели разработчик машины из приложения В может воспользоваться кодом операции D. Язык можно дополнить так, чтобы инструкция вида ORXY означала запись в регистр R содержимого ячейки памяти, адрес которой находится по адресу XY (рис. 7.24). Так, если указатель стека находится в ячейке памяти по адресу АА, то при выполнении инструкции D5AA данные из вершины стека будут загружены в регистр 5.
Эта инструкция, однако, не выполняет операцию выталкивания полностью. От указателя стека необходимо отнять единицу, чтобы он теперь указывал на новую вершину стека. Инструкция должна выполняться следующим образом: программа на машинном языке загрузит указатель стека в регистр, отнимет от указателя единицу и запишет результат обратно в память.
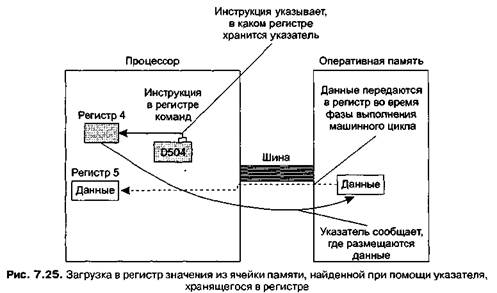
Используя в качестве указателя стека один из регистров вместо ячейки памяти, мы можем сократить количество перемещений указателя стека между регистрами и памятью. Однако это означает, что нам необходимо переопределить инструкцию загрузки, чтобы она искала указатель в регистре, а не в оперативной памяти. Таким образом, вместо предыдущего подхода разработчик машины может определить инструкции с кодом операции D в форме DR0S, что означает запись в регистр R содержимого ячейки памяти, на которую указывает регистр S (рис. 7.25). Тогда, выполнив эту инструкцию и команду вычитания единицы из значения в регистре S, мы выполним полную операцию выталкивания.
Похожая инструкция требуется для выполнения операции проталкивания. Разработчик машины может еще более расширить язык из приложения В, введя код операции Е. Инструкция в форме EROS будет означать запись содержимого регистра R в ячейку памяти, на которую указывает регистр S. И снова для завершения операции проталкивания за этой инструкцией будет следовать команда добавления единицы к значению в регистре S.
С этими расширениями машинного языка из приложения В будут реализованы три способа адресации. В первом операнд инструкции содержит данные (код операции 2). Во втором случае в операнде инструкции содержится адрес данных (коды операции 1 и 3). В третьем случае в операнде инструкции хранится адрес указателя на данные (коды операции D и Е). Эти способы называются непосредственной адресацией (immediate addressing), прямой адресацией (direct addressing) и косвенной адресацией (indirect addressing) соответственно. Все они часто встречаются в современных машинных языках.
ФАЙЛОВЫЕ СТРУКТУРЫ
В главе 7 мы познакомились с различными способами организации данных в оперативной памяти компьютера. В этой главе мы сосредоточимся на технологиях хранения данных на запоминающих устройствах. Основная мысль нашего обсуждения будет состоять в том, что способ доступа к информации играет важную роль при выборе способа ее хранения. Как и во время изучения структур данных, мы увидим, что форма, в которой пользователь в конечном итоге видит данные, не всегда соответствует организации этих данных в системах хранения. Таким образом, как и в главе 7, мы будем обсуждать и сравнивать абстрактные и фактические структуры данных.