 2015-10-22
2015-10-22 2159
2159Основные этапы в истории создания двуядерных процессоров таковы:
· 1999 год – анонс первого двуядерного процессора в мире (IBM Power4 для серверов);
· 2001 год – начало продаж двуядерного IBM Power4;
· 2002 год – почти одновременно AMD и Intel объявляют о перспективах создания своих двуядерных процессоров;
· 2002 год – выход процессоров Intel Xeon и Intel Pentium 4 с технологией Hyper-Threading, обеспечивающей виртуальную двухпроцессорность на одном кристалле;
· 2004 год – свой двуядерный процессор выпустила Sun (UltraSPARC IV);
· 2004 год – IBM выпустила второе поколение своих двуядерных процессоров (IBM Power5). Каждое процессорное ядро Power5 поддерживает аналог технологии Hyper-Threading;
· 2005 год, 18 марта – Intel выпустила первый в мире двуядерный процессор архитектуры x86;
· 2005 год, 21 марта – AMD анонсировала полную линейку серверных двуядерных процессоров Opteron, анонсировала десктопные двуядерные процессоры Athlon 64 X2 и начала поставки двуядерных Opteron 8xx;
· 2005 год, 20-25 мая – AMD начинает поставки двуядерных Opteron 2xx;
· 2005 год, 26 мая – Intel выпускает двуядерные Pentium D для массовых ПК;
· 2005 год, 31 мая – AMD начинает поставки Athlon 64 X2.
Идея многоядерного процессора выглядит на первый взгляд совершенно тривиальной: просто упаковываем два-три (или более) процессора в один корпус - и компьютер получает возможность исполнять несколько программных потоков одновременно. Конкретные её реализации в недавно вышедших настольных процессорах AMD и Intel заметно различаются. Различаются настолько, что сугубо «количественные» мелочи в конечном итоге переходят в качественные различия между процессорами этих двух компаний.
Проанализируем различия в подходах при создании этих микропроцессоров и оценим предполагаемую производительность.
Intel Smithfield
При создании многоядерных процессоров для настольных ПК фирма Intel предпочла пойти на первых порах по пути наименьшего сопротивления, продолжив традиции создания привычных для себя SMP-систем с общей шиной. Выглядит подобная MP-система чрезвычайно просто: один чипсет, к которому подключается вся оперативная память, и одна процессорная шина, к которой подключены все процессоры:
 |
В случае двуядерных процессоров Smithfield два обычных ядра, аналогичных Prescott, просто расположены рядом на одном кристалле кремния и электрически подключены к одной (общей) системной шине. Никакой общей схемотехники у этих ядер нет.
 |
У каждого «ядра» Smithfield – свой APIC, вычислительное ядро, кэш-память второго уровня и (что особенно важно) – свой интерфейс процессорной шины (Bus I/F). Последнее обстоятельство означает, что двуядерный процессор Intel с точки зрения любой внешней логики будет выглядеть в точности как два обыкновенных процессора (типа Intel Xeon).
Сегодняшнее ядро Smithfield является «монолитным» (два ядра образуют единый кристалл процессора), однако следующее поколение настольных процессоров Intel (Presler, изготавливаемый по 65-нм технологии) будет еще тривиальнее – два одинаковых кристалла одноядерных процессоров (Cedar Mill) просто будут упакованы в одном корпусе.
 |  |
| Presler | Cedar Mill |
Точно таким же будет и первый серверный процессор Intel данной микроархитектуры, известный сейчас под именем Dempsey. Но если у Smithfield на каждое из ядер приходится по 1 Мбайт кэш-памяти второго уровня, то у Presler и Dempsey это будет уже по 2 Мбайт на ядро.
Между тем, позднее у Intel пойдут другие, более сложные в плане микроархитектуры варианты двуядерных процессоров, среди которых стоит отметить Montecito (двуядерный Itanium), Yonah (двуядерный аналог Pentium M) и Paxville для многопроцессорных серверов на базе Intel Xeon MP. Еще в марте 2005 года фирма Intel объявила, что в разработке находятся 15 различных многоядерных CPU, и пять из них корпорация даже демонстрировала в работе.
Если еще в середине 2004 года официальные лица Intel отмечали, что многоядерные процессоры – это не «очередная гонка за производительностью». Поскольку программная инфраструктура была тогда еще не очень готова поддержать такие процессоры оптимизированными приложениями, то теперь многоядерность у Intel поставлена во главу угла во всех базовых направлениях деятельности, в том числе – в разработке и отладке приложений (кроме коммуникаций и сенсорных сетей – пока).
Тактовую частоту процессоров стало наращивать все труднее и труднее, и, стало быть, надо искать что-то на смену гонки за тактовой частотой. Добавляя ядра, производительность в ряде современных приложений уже можно заметно поднять, не повышая частоты.
Собственно, мультиядерность в текущем понимании Intel – это один из трех возможных вариантов:
1. Независимые процессорные ядра, каждое со своей кэш-памятью, расположены на одном кристалле и просто используют общую системную шину. Это - 90-нанометровый Pentium D на ядре Smithfield.
2. Похожий вариант – когда несколько одинаковых ядер расположены на разных кристаллах, но объединены вместе с одном корпусе процессора (многочиповый процессор). Таким будет 65-нанометровое поколение процессоров семейств Pentium и Xeon на ядрах Presler и Dempsey.
3. Наконец, ядра могут быть тесно переплетены между собой на одном кристалле и использовать некоторые общие ресурсы кристалла (скажем, шину и кэш-память). Таким является ближайший Itanium на ядре Montecito, а также мобильный Yonah.

Попутно отметим, что Montecito, изготавливаемый по 90-нм техпроцессу, будет иметь по сравнению с предшественником на 130-нм ядре Madison и ряд других преимуществ: наличие Hyper-Threading (то есть он будет виден в системе как 4 логических процессора), заметно меньшее энергопотребление, более высокую производительность (в 1,5 раза и выше), вчетверо больший размер кэш-памяти (свыше 24 Мбайт: 2x1 Мбайт L2 инструкций, 2x12 Мбайт L3 данных), 1,72 миллиарда транзисторов против 410 миллионов и прочее. Выпуск этого процессора ожидается в четвертом квартале 2005 года.
Не менее интересным ожидается и первый двуядерный мобильный процессор Yonah, который должен появиться в начале 2006 года в рамках новой мобильной платформы Napa. Yonah будет иметь два вычислительных ядра, использующих общую 2-мегабайтную кэш-память второго уровня и общий же контроллер системной шины QPB с частотой 667 МГц. Он будет выпускаться по 65-нм технологии в форм-факторах PGA 478 и BGA 479, содержать 151,6 млн. транзисторов, поддерживать технологию XD-bit и, судя по предварительной информации, поддерживать некоторые механизмы прямого взаимодействия ядер между собой.
Более того, Intel не исключают и того, что процессоры на «мобильном» ядре Yonah будут использоваться не только в определенных сегментах рынка настольных компьютеров (для этого уже разработаны и демонстрируются соответствующие мини-концепты домашнего и офисного ПК), но даже в компактных экономичных серверах.
Первым восьмиядерным процессором Intel станет, по всей видимости, Tukwila в 2007 году, продолжающая линейку Intel Itanium.
Intel Smithfield, к сожалению, несовместим со всеми уже существующими чипсетами самой Intel, ибо чипсеты, рассчитанные на однопроцессорную шину, теперь вынуждены будут работать фактически с «дуальными» системами, а двухпроцессорным чипсетам (напомним, что Intel четко разделяет процессоры для дуал и для многопроцессорных систем) придется научиться работать с «квадами» - четверками процессоров. То есть нагрузка на системную шину существенно возрастет, и прежние чипсеты на нее просто не рассчитаны. В Intel пробовали запускать Smithfield на чипсетах серии i925/915, но работа такой связки не всегда была достаточно стабильной, поэтому от нее было решено официально отказаться и даже предусмотреть меры, исключающие запуск двуядерных процессоров на платах со старыми чипсетами.
Такой подход Intel, несмотря на все свои «подводные камни», в конечном счете, позволит обеспечить пользователей дешевыми и доступными каждому двуядерными CPU. Intel планирует, что в 2006 году 85% серверных и более 70% клиентских компьютеров (ноутбуков и десктопов) будут иметь двуядерные процессоры, а в 2007 году эти цифры возрастут до 100% и 90% соответственно.
 |
| «Классическая» двухпроцессорная SMP-система с двуядерными процессорами |
Организация «системы в целом» у Intel столь же традиционна, сколь и устройство двуядерного процессора. В ней есть несколько «равноправных» центральных процессоров (как правило, разделяющих общую шину); есть оперативная память и есть разной степени быстродействия периферия. Весь этот комплект объединяется в единое целое специальным коммуникационным процессором – «северным мостом» (Northbridge) чипсета. Через него проходят буквально все потоки данных, которые только зарождаются в компьютере. Подобный «централизованный» подход, во-первых, отличается относительной простотой, а во-вторых, удобен тем, что в нём каждый компонент компьютера получается узкоспециализированным и поддающимся модернизации независимо от других компонентов. То есть с одним и тем же Northbridge можно использовать, например, совершенно различные по своей производительности процессоры и наоборот – меняя Northbridge, можно, например, использовать с одним и тем же процессором совершенно разные типы оперативной памяти.
| Терминология · APIC (Advanced Programmable Interrupt Controller) – один из важнейших узлов любого компьютера. Это небольшая схема, занимающаяся сбором и обработкой возникающих в компьютере прерываний. Нажал пользователь клавишу на клавиатуре – контроллер клавиатуры зафиксировал это событие, занес код нажатой клавиши в свою встроенную память и сгенерировал прерывание – выдал по специальной линии сигнал-запрос с просьбой прервать выполнение текущей программы и обработать событие «нажата клавиша на клавиатуре». Это - «классическая» задача контроллеров обработки прерываний: они позволяют процессору не терять время на регулярный опрос каждого из устройств с целью не пропустить возникающие запросы на обслуживание. Но задачи IC не ограничиваются только этим: помимо аппаратных, существуют еще и программные прерывания (exceptions), которые генерирует не периферия, а сам процессор – в случае возникновения какой-либо нештатной ситуации. Типичные примеры: в программе встретилась непонятно какая или просто запрещенная «простому пользователю» инструкция (#GP, General Protection Exception), произошло деление на ноль (#DE, Divide-by-Zero Error Exception), программа обратилась к несуществующему адресу в памяти (#PF, Page Fault Exception). Некоторые прерывания может генерировать сама программа (INTn), а, скажем, прерывание #BP (BreakPoint Exception) используется операционной системой для отладки программ. Реакция на каждое из прерываний задается так называемым вектором прерываний – набором адресов в памяти, описывающих «что делать дальше» процессору в случае возникновения прерывания: какие функции (обработчики прерывания) ему в этом случае необходимо выполнять. В общем, PIC были, есть и будут одной из ключевых компонент компьютера. Причем, в случае многопроцессорных, многоядерных (и даже в случае процессоров с Hyper-Threading), требуется обеспечить по одному APIC на каждое ядро процессора (включая каждое виртуальное ядро в Pentium 4 supporting Hyper-Threading), обрабатывающих программные прерывания, и еще один, «синхронизирующий» APIC в чипсете, который обеспечивает обработку аппаратных прерываний и занимается «рассылкой» программных прерываний в тех случаях, когда возникшее на одном процессоре прерывание почему-то затрагивает и остальные процессоры. · DMA (Direct Memory Access) – это своеобразный «альтернативный процессор», который занимается в чипсете обработкой «фоновых» задач, связанных с периферией. Скажем, если процессору требуется прочитать несколько килобайт данных с жесткого диска, то ему вовсе не обязательно ждать несколько миллисекунд (очень много – по сравнению с быстродействием процессора), пока эти самые данные ему не будут предоставлены. Вместо этого он может запрограммировать DMA-контроллер, чтобы тот выполнил эту задачу за него, и переключиться, пока этот запрос выполняется, на какую-нибудь другую задачу. · GART (Graphical Address Relocation Table) появился в компьютерах одновременно с шиной AGP: это небольшая схема, которая обеспечивает графическому ускорителю доступ к системной памяти процессора. Её задачи – реализация механизма виртуальной памяти для GPU, то есть отображение «линейного» адресного пространства, с которым работает ускоритель, на «реальное», произвольным образом «перетасованное» с обычными данными. Позволяет современным 3D-ускорителям использовать не только внутреннюю видеопамять, но и основную системную память компьютера. |
AMD Toledo
Архитектура AMD K8 не просто отличается от Intel: она концептуально иная, поскольку в ней нет какого-то выделенного центра. Каждый из процессоров архитектуры AMD64 является независимой и «самодостаточной» единицей, объединяющей в себе почти всю функциональность северного моста традиционных наборов системной логики. Это началось с одноядерных процессоров, а с появлением двуядерных CPU «обросло» новыми отличиями. Обратим внимание на блок-схему двухпроцессорной системы на двуядерных AMD Opteron.
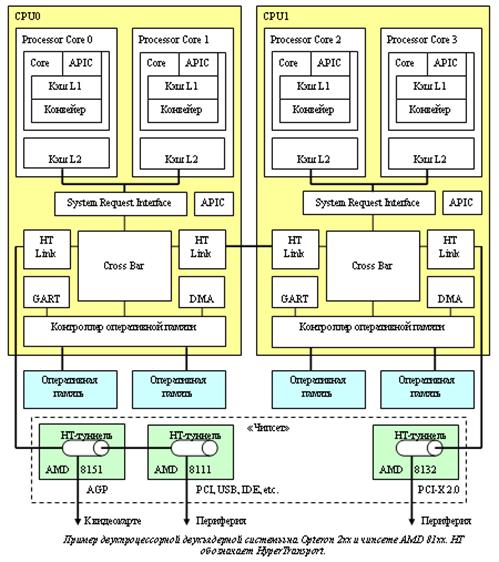 |
| Пример двухпроцессорной двуядерной системы на Opteron 2xx и чипсете AMD 81xx. HT обозначает HyperTransport |
Если смотреть на этот вопрос с чисто технической стороны, то AMD попросту интегрировала практически всю функциональность северного моста в центральный процессор, что хорошо видно на блок-схемах. Но «небольшая» технологическая уловка приводит к совсем иной архитектуре компьютера – SUMA, в отличие от традиционной SMP. Перечислим кратко основные преимущества SUMA над «классической» SMP:
· Основа SUMA – последовательная шина HyperTransport. В серверных вариантах процессоров AMD может быть интегрировано до трех независимых линков HT, работающих на частотах до 1 ГГц (2 ГГц с учетом режима передачи данных DDR) и шириной по 16 бит (4 Гбайт/с) в каждом из направлений. Часть HT-линков используется для соединений точка-точка между процессорами, часть задействуется для подключения периферийных устройств (через внешний чипсет, поскольку HT связывает один из процессоров с чипсетом тоже как точка-точка). Для программиста HT полностью совместима с традиционной программной моделью PCI; при этом с «логической» точки зрения весь компьютер напрямую подключаются к единой шине HT, объединяющей все устройства, от центрального процессора и до любой PCI-карты, вставленной в обычный PCI-слот.
· В каждый процессор интегрируется контроллер «локальной» оперативной памяти (собственно, по сравнению с одноядерными процессорами AMD64 контроллер памяти почти не изменился). На сегодняшний момент в зависимости от процессора это может быть одно- или двухканальный (у двуядерников – пока только двухканальный) контроллер памяти DDR 200/266/333/400 (небуферизованной или регистровой, с поддержкой ECC и без неё). Обращения к памяти «чужих» процессоров происходят по шине HyperTransport, причем делается эта «переадресация» запросов абсолютно прозрачно для собственно вычислительного ядра процессора – ее осуществляет встроенный в Northbridge коммутатор (CrossBar), работающий на полной частоте процессора. Этот же самый CrossBar обеспечивает «автоматическую» маршрутизацию проходящих через процессор сообщений от периферийных устройств и других процессоров, включая обслуживание «чужих» запросов к оперативной памяти.
· Шина HT специально оптимизировалась для подобного режима работы с множеством «служебных» сообщений и обеспечивает крайне низкую латентность обращения (задержку распространения) в «чужую» память и высокую (до 4 Гбайт/с) пропускную способность при обращении к памяти «соседей». Шина является полнодуплексной, т.е. шина позволяет одновременно передавать данные на этой скорости в «обе стороны» (до 8 Гбайт/с суммарно). Модель памяти получается неоднородной (NUMA), но различия в скорости «своих» и «чужих» участков оперативной памяти получаются относительно небольшими.
· Чипсет сильно упрощается: всё, что от него требуется – это просто обеспечивать «мосты» (туннели) между HT и другими типами шин. Ну и, возможно, заодно обеспечивать какое-то количество интегрированных контроллеров. Особенно ярко этот принцип проявляется в серверном чипсете AMD 81xx, поскольку это просто набор из двух чипов – «переходников» на шины AGP и PCI-X и чипа, интегрирующего туннель на «обычную» PCI и стандартный набор периферийных контроллеров (IDE, USB, LPC и проч.). Впрочем, традиционные «большие» чипсеты тоже совместимы: к примеру, NVIDIA успешно выпускает Force3 и nForce4, объединяющие все необходимые туннели и контроллеры в единственном кристалле. Но зато можно, к примеру, установить на плату чип nForce Professional 2200 (решение «всё-в-одном» от NVIDIA для рабочих станций) и добавить к нему «в напарники» AMD 8132, который обеспечит материнской плате поддержку шины PCI-X, которой в nForce Pro 2200 нет. Или использовать несколько чипов nForce Pro 2200, чтобы обеспечить, к примеру, вдвое большее число линий PCI Express. Здесь всё совместимо со всем: любые современные чипсеты для микроархитектуры AMD64, теоретически, должны работать и с любыми процессорами AMD и любыми «правильно» сделанными «напарниками». В частности, все двуядерные процессоры AMD должны работать со всеми ранее выпущенными чипсетами для процессоров архитектуры K8.
AMD сейчас любит подчеркивать, что её процессоры «специально проектировались в расчёте на двуядерность», но, строго говоря, правильнее было бы говорить, что двуядерность очень удачно ложится на её архитектуру. Каждый процессор K8 является «системой в миниатюре», со своим «процессором» и Northbridge; а двуядерный K8 – «двухпроцессорная SMP-система в миниатюре».
Второе ядро подключается к кросс-бару через общую шину SRI; оба ядра идентичны и фактически являются полноценными процессорами; общего кэш L2 нет. То есть если мы, скажем, рассматриваем однопроцессорную двуядерную систему, то вся разница между реализациями AMD и Intel с «технологической» точки зрения заключается в том, что у Intel Northbridge реализован отдельным кристаллом, а у AMD он просто интегрирован в центральный процессор.
Интеграция Northbridge в процессор и SUMA-архитектура K8 не просто обеспечивает «более быстрый контроллер оперативной памяти» - она заодно позволяет очень эффективно решать и ряд свойственных многопроцессорным системам проблем.








