 2018-01-08
2018-01-08 774
774МЕТОДИЧНІ ВКАЗІВКИ
ДО ВИКОНАННЯ ЛАБОРАТОРНИХ РОБІТ
Постановка задачі
| Техніко-економічні показники об'єктів приватизації | |||||||
| № п/п | x1 | x2 | x3 | x4 | x5 | x6 | x7 |
| 90,2 | 458,9 | 1285,8 | 1,9 | ||||
| 48,7 | 237,6 | 608,9 | |||||
| 24,1 | 181,5 | 487,3 | 2,7 | ||||
| 66,7 | 364,4 | 908,6 | |||||
| 205,7 | 1,4 | ||||||
| 43,9 | 394,9 | 1023,7 | 1,3 | ||||
| 260,1 | 743,8 | 1,2 | |||||
| 355,3 | 1806,8 | 0,4 | |||||
| 66,6 | 366,9 | 1106,1 | 0,41 | ||||
| 65,6 | 245,2 | 745,7 | 0,58 | ||||
| 27,6 | 154,7 | 508,9 | 0,85 | ||||
| 69,1 | 291,9 | 734,2 | 1,3 | ||||
| 63,2 | 584,1 | 1651,8 | 1,5 | ||||
| 258,9 | 711,7 | 1,6 | |||||
| 25,7 | 576,3 | 1,1 |
X1 – середньорічна вартість основних виробничих фондів, млн.грн.;
X2 – продуктивність праці, тис.грн.;
X3 – витрати на виробництво, тис.грн.;
X4 – кредиторська заборгованість, тис.грн.;
X5 – дебіторська заборгованість, тис.грн.;
X6 – собівартість одиниці продукції, грн.;
X7 – питома вага на ринку даної продукції, %.
Завдання 1
Побудова:
1) матриці стандартизованих ознак Z;
2) матриці відстаней між об’єктами приватизації на основі метрик:
- лінійної відстані D1;
- евклідової відстані D2;
- супремум-норми(метрики Чебишова) D∞;
- квадрата евклідової норми (D2)2 ;
- степеневої відстані для різних можливих пар параметрів P та r;
3) матриці схожості між об’єктами приватизації за побудованими матрицями відстаней.
Виконання:
Запуск системи STATISTICA
1) Вихідні дані:

2) Стандартизація даних – приведення змінних до одного безрозмірного вигляду. Така процедура виражається формулою:

Cluster Analysis: Виділяємо масив вихідних даних, клацаємо правою кнопкою миші. Вибираємо Fill(Standardize Block →Standardize Columns);

3) Матриця коефіцієнтів парної кореляції:
 .
.
Multiple Regression: Analysis Startup Panel→ вказуємо одну залежну зміну, а решта незалежних →Input File(Rave Date-OK)→ Multiple Regression Results(Correlation desc. stats)→Review Descriptive Statistics(Correlations)→матриця r
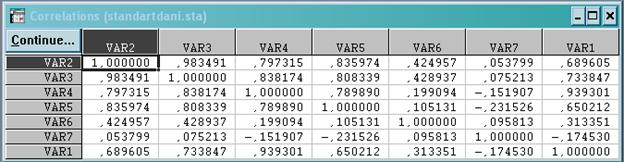
4) Матриці відстаней між об’єктами приватизації на основі метрик. Матриці схожості між об’єктами приватизації за побудованими матрицями відстаней:
Cluster Analysis: Analysis→Startup Panel→Clustering Method(Jaining(tree clustering))→ Jaining (вказуємо метрику відстані)→ Jaining Results (Distance matrix).
А) Евклідова відстань –  і відповідна метрика схожості;
і відповідна метрика схожості;


Б) Квадрат евклідової норми – 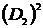 ; і відповідна метрика схожості
; і відповідна метрика схожості


В) Лінійна відстань –  ; і відповідна метрика схожості
; і відповідна метрика схожості

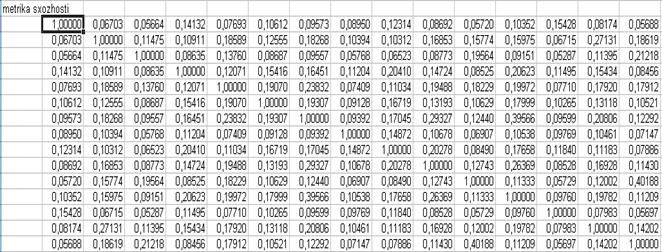
Г) Степенева відстань і відповідна метрика схожості;


Д) Супремум – норма (Метрика Чебишова) –  і відповідна метрика схожості;
і відповідна метрика схожості; 

Висновок:
На основі даних обчислень, можна визначити близькість (віддаленість) між об’єктами, встановити однорідність(неоднорідність) досліджуваної сукупності.
За допомогою матриць схожостей, можна сказати, що чим більше віддаленні об’єкти в багатовимірному просторі ознак, тим менше вони є схожими і навпаки.
Завдання 2
Здійснити оцінку латентного показника «Інвестиційна привабливість» об’єктів приватизації на базі метрик відстані та схожості, використовуючи;
А) класичний алгоритм;
Б) модифікований алгоритм;
Здійснити ранжування об’єктів приватизації у відповідності зі знайденими оцінками за кожним методом, здійснити їх порівняльний аналіз. Виділити серед об’єктів досліджуваної сукупності групи лідерів, посередніх об’єктів, аутсайдерів і зробити короткі статистичні висновки.
Виконання:
Класичний алгоритм
1) Утворення матриці вихідних даних

2) Розділення ознак на:
x1, x2, x7 – стимулятори;
x3, x4, x5, x6 – де стимулятори;
3) Зважування ознак-симптомів не проводиться.
4) Перехід до матриці стандартизованих ознак Z. Задання еталону(точка додається до матриці в якості 16 об’єкта (рядок 16)).
Серед x1, x2, x7 визначається максимальне значення ознак, а серед x3, x4, x5, x6 - мінімальне.
z٭(1,872; 2,364; -1,160; -1,632; -1,047; -1,792; 2,280) – точка еталону.

5) Вибір метрики відстані – Евклідова метрика.

6) Розрахунок міри схожості (в Excel) за формулою:

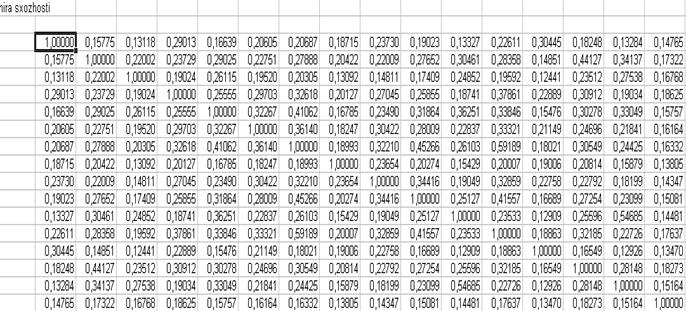
7) Результати
m – оцінки латентного показника;
Лідери (4, 14 підприємства) мають найближчу відстань до еталону.
Аутсайдери (8, 13 підприємства) мають мінімальну схожість з еталоном.
Середняки – підприємства, які займають проміжне значення.
Результати оцінки «Інвестиційна привабливість» об’єктів приватизації за класичним алгоритмом:

Модифікований алгоритм
1) Утворення матриці вихідних даних
2) Розділення ознак на:
x1, x2, x7 – стимулятори;
x3, x4, x5, x6 – де стимулятори;
Всі ознаки-симптоми, які є де стимуляторами, необхідно перетворити таким чином:
 .
.

3) Зважування ознак-симптомів не проводиться.
4) Перехід до матриці стандартизованих ознак Z. Задання анти еталону(точка додається до матриці в якості 16 об’єкта (рядок 16)).
Серед усіх стандартизованих ознак-симптомів визначають найменше значення – z٭(-1,579; -1,579; -1,579; -1,579; -1,579; -1,579; -1,579) – точка анти еталону.
Стандартизовані дані та точка антиеталону:

5) Вибір метрики відстані – Евклідова метрика.

6) Розрахунок міри схожості (в Excel) за формулою:
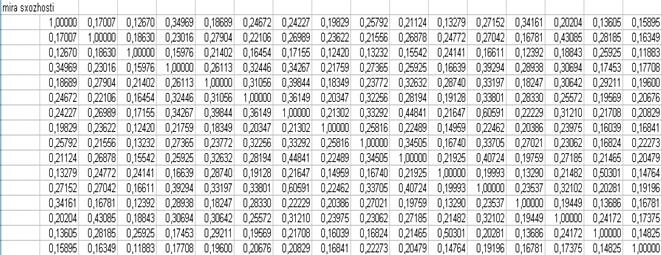
7) Нормування за формулою

значень відстаней(в Excel) і присвоєння відповідних їм рангів.
Значения  можна розглядати в якості шуканого латентного показника «Інвестиційна привабливість» об’єктів приватизації на досліджуваній сукупності підприємств.
можна розглядати в якості шуканого латентного показника «Інвестиційна привабливість» об’єктів приватизації на досліджуваній сукупності підприємств.
Лідери (3, 11, 15 підприємства) мають найближчу відстань до еталону.
Аутсайдери (7, 9 підприємства) мають мінімальну схожість з еталоном.
Середняки – підприємства, які займають проміжне значення.
Результати оцінки «Інвестиційна привабливість» об’єктів приватизації за модифікованим алгоритмом:
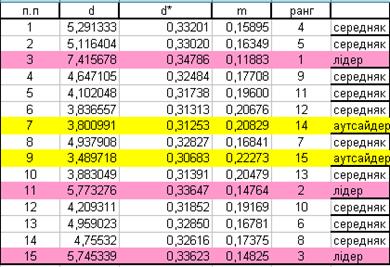
Порівняння результатів багатовимірної оцінки «Інвестиційна привабливість» об’єктів приватизації:
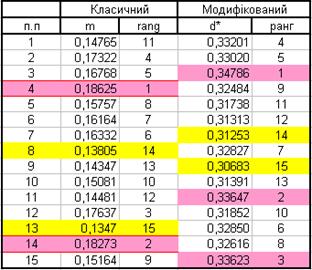
Висновок:
Порівняння оцінок показує, що вони різні. В класичному алгоритмі ті що були лідерами та аутсайдерами стали посередніми. В модифікованому алгоритмі ми бачимо нових лідерів та нових аутсайдерів.
Завдання 3:
Здійснити багатовимірне групування вихідної статистичної сукупності об’єктів за допомогою кластерного аналізу на основі:
1) ієрархічного агломеративного алгоритму;
2) методу k-середніх, вважаючи, що k=R з попереднього пункту;
3) алгоритму «Форель».
Проаналізувати одержані результати й поглибити зроблені висновки за допомогою методу подвійного об’єднання та оптимізаційних процедур.
Зробити порівняльний аналіз використаних алгоритмів кластерного аналізу й перевірити статистичні гіпотези відносно однорідності досліджуваної сукупності об’єктів.
Виконання:
Запуск системи STATISTICA
2) Вихідні дані:

5) Стандартизація даних – приведення змінних до одного безрозмірного вигляду. Така процедура виражається формулою:
Cluster Analysis: Виділяємо масив вихідних даних, клацаємо правою кнопкою миші. Вибираємо Fill(Standardize Block →Standardize Columns);









