 2014-01-31
2014-01-31 799
799Случайные погрешности.
Лекция №4
 Присутствие случайных погрешностей в результатах измерений легко обнаруживается из-за их разброса относительно некоторого значения.
Присутствие случайных погрешностей в результатах измерений легко обнаруживается из-за их разброса относительно некоторого значения.
Из теории вероятности известно, что наиболее универсальным способом описания случайных величин является отыскание их интегральных или дифференциальных функций распределения.
Интегральной функцией распределения F(x) называют функцию, каждое значение которой для каждого х является вероятностью события, заключающегося в том, что случайная величина хi; в i -м опыте принимает значение, меньшее х:
F(x)=P{xi<x}=P{-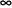 <xi≤x}
<xi≤x}
График интегральной функции распределения показан на рис. 1. Она имеет следующие свойства:
· неотрицательная, т.е. F(x) ≥0;
· неубывающая, т.е. F(x2)≥ F(x1), если х2 ≥х1;
· диапазон ее изменения простирается от 0 до 1, т.е. F(-) = 0; F(+) = 1;
· вероятность нахождения случайной величины х в диапазоне от x1 до х2 Р{х1< х < х2} = F(x2) - F(x1).
Более наглядным является описание свойств результатов измерений и случайных погрешностей с помощью дифференциальной функции распределения, иначе называемой плотностью распределения вероятностей р(х)=dF(x)/dx. Она всегда неотрицательна и подчиняется условию нормирования в виде:
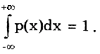
Учитывая взаимосвязь F(x) и р(х), легко показать, что вероятность попадания случайной величины в заданный интервал (х1; х2)
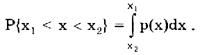
Следовательно, рассмотренное выше условие нормирования означает, что вероятность попадания величины х в интервал [-; + ] равна единице, т.е. представляет собой достоверное событие.
Из последнего уравнения следует, что вероятность попадания случайной величины х в заданный интервал (x1;х2) равна площади, заключенной под кривой р(х) между абсциссами х1 и х2 (рис. 1).
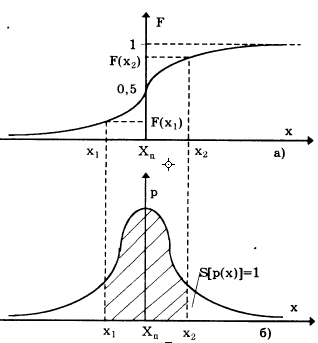
Рис. 1.
Поэтому по форме кривой плотности вероятности p(x) можно судить о том, какие значения случайной величины х наиболее вероятны, а какие наименее.








