2018-02-14
2018-02-14 226
226Цель моделирования.
Целью моделирования является решение приоритетной проблемы, связанной с повышением валовой продукции предприятия по сравнению с лучшими аналогичными предприятиями.
Методика выявления приоритетной проблемы изложена в «методе наименьших квадратов».
Выбор переменных.
Величина валовой продукции зависит от шести основных факторов:
1. сырье и материалы (качество сырья и материалов);
2. машины (техническое оборудование предприятия);
3. методы (технология производства);
4. люди (количество рабочих, уровень квалификации, и т.д.);
5. физическая и абстрактная среда (температура, влажность);
6. время (в данной задаче не оказывает влияние на Y).
Выделение входных и выходных переменных.
В соответствии с возникшей проблемой, связанной с низким уровнем валовой продукции по сравнению с конкурентами, возникла потребность изучить зависимость и прогноз прироста валовой продукции от количества реализованных рационализаторских предложений.
Следовательно, входными переменными будет количество поданных рационализаторских предложений (Х), выходными показателями прирост валовой продукции (Y).
График зависимости Y от Х представлен на рисунке 1.

Рисунок 1. График зависимости Y от Х
Анализ графика зависимости Y от Х показывает, что с ростом числа поданных рационализаторских предложений происходит прирост валовой продукции предприятия. В тоже время эта зависимость является стохастической.
Выдвижение гипотез.
Предположим, что прирост валовой продукции линейно зависит от количества поданных рационализаторских предложений.
Формулировка допущений.
Прирост валовой продукции в большей степени зависит от количества поданных рационализаторских предложений, чем от других мер совершенствования процессов.
Спецификация модели.
Предположим, что фактическая зависимость Y от Х для всех предприятий генеральной совокупности можно представить в виде классической нормальной линейной модели парной регрессии, спецификация которой представлена соотношениями:
Yi = f(Хi )+e = a + b Хi +e, при i=1,2,…,n.
Идентифицируемость модели.
Классическая нормальная линейная модель парной регрессии соответствует объекту исследования и может быть применена к изучению зависимости Y от Х.
Идентификация модели.
Для оценки параметров и характеристик истинной зависимости Y от Х используется регрессионное уравнение, коэффициенты и характеристики которого определяются по выборочной совокупности объемом n.
1.2.Расчет коэффициентов a, b.
Таблица 2
Расчет коэффициентов a, b
| i | Xi | Yi | Xi-X ̅ | Yi-Y ̅ | (Xi-X ̅)*(Yi-Y ̅) | (Xi-X ̅)2 |
| 1 | 2300 | 760 | -3642,5 | -391 | 1424218 | 13267806 |
| 2 | 3400 | 750 | -2542,5 | -401 | 1019543 | 6464306 |
| 3 | 3600 | 800 | -2342,5 | -351 | 822217,5 | 5487306 |
| 4 | 4000 | 860 | -1942,5 | -291 | 565267,5 | 3773306 |
| 5 | 4250 | 880 | -1692,5 | -271 | 458667,5 | 2864556 |
| 6 | 4500 | 1020 | -1442,5 | -131 | 188967,5 | 2080806 |
| 7 | 5000 | 1040 | -942,5 | -111 | 104617,5 | 888306,3 |
| 8 | 5600 | 1050 | -342,5 | -101 | 34592,5 | 117306,3 |
| 9 | 5800 | 1170 | -142,5 | 19 | -2707,5 | 20306,25 |
| 10 | 6000 | 1210 | 57,5 | 59 | 3392,5 | 3306,25 |
| 11 | 6100 | 1250 | 157,5 | 99 | 15592,5 | 24806,25 |
| 12 | 6500 | 1240 | 557,5 | 89 | 49617,5 | 310806,3 |
| 13 | 6800 | 1300 | 857,5 | 149 | 127767,5 | 735306,3 |
| 14 | 7000 | 1290 | 1057,5 | 139 | 146992,5 | 1118306 |
| 15 | 7200 | 1280 | 1257,5 | 129 | 162217,5 | 1581306 |
| 16 | 7500 | 1350 | 1557,5 | 199 | 309942,5 | 2425806 |
| 17 | 7800 | 1400 | 1857,5 | 249 | 462517,5 | 3450306 |
| 18 | 8000 | 1450 | 2057,5 | 299 | 615192,5 | 4233306 |
| 19 | 8500 | 1450 | 2557,5 | 299 | 764692,5 | 6540806 |
| 20 | 9000 | 1470 | 3057,5 | 319 | 975342,5 | 9348306 |
| Сумма | 118850 | 23020 |
|
| 8248650 | 64736375 |
| Среднее | 5942,5 | 1151 |
|
|
|
|
1. Расчет коэффициент модели b:

0,12741909
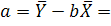 2. Расчет коэффициент модели a:
2. Расчет коэффициент модели a:
393,812057
 8248650- ковариация переменных Y и X
8248650- ковариация переменных Y и X
 64736375-вариация переменной Х
64736375-вариация переменной Х
 5942,5-среднее значение Х
5942,5-среднее значение Х
 1151-среднее значение Y
1151-среднее значение Y
1.3. Вычисление ошибки модели E
Таблица 3
Расчет ошибки модели
| i | Xi | Yi | (Yi) ̂ | Yi-(Yi) ̂ | (Yi-(Yi) ̂)^2 |
| 1 | 2300 | 760 | 686,8759642 | 73,12403575 | 5347,124605 |
| 2 | 3400 | 750 | 827,0369634 | -77,0369634 | 5934,693726 |
| 3 | 3600 | 800 | 852,5207814 | -52,5207814 | 2758,432479 |
| 4 | 4000 | 860 | 903,4884174 | -43,4884174 | 1891,242452 |
| 5 | 4250 | 880 | 935,34319 | -55,34319 | 3062,868677 |
| 6 | 4500 | 1020 | 967,1979625 | 52,80203749 | 2788,055164 |
| 7 | 5000 | 1040 | 1030,907508 | 9,092492436 | 82,67341869 |
| 8 | 5600 | 1050 | 1107,358962 | -57,3589616 | 3290,05048 |
| 9 | 5800 | 1170 | 1132,84278 | 37,15722034 | 1380,659024 |
| 10 | 6000 | 1210 | 1158,326598 | 51,67340232 | 2670,140507 |
| 11 | 6100 | 1250 | 1171,068507 | 78,93149331 | 6230,180636 |
| 12 | 6500 | 1240 | 1222,036143 | 17,96385726 | 322,7001676 |
| 13 | 6800 | 1300 | 1260,26187 | 39,73813022 | 1579,118994 |
| 14 | 7000 | 1290 | 1285,745688 | 4,254312201 | 18,0991723 |
| 15 | 7200 | 1280 | 1311,229506 | -31,2295058 | 975,2820339 |
| 16 | 7500 | 1350 | 1349,455233 | 0,544767142 | 0,296771239 |
| 17 | 7800 | 1400 | 1387,68096 | 12,31904011 | 151,7587492 |
| 18 | 8000 | 1450 | 1413,164778 | 36,83522208 | 1356,833586 |
| 19 | 8500 | 1450 | 1476,874323 | -26,874323 | 722,2292354 |
| 20 | 9000 | 1470 | 1540,583868 | -70,583868 | 4982,082427 |
| Сумма | 118850 | 23020 | 23020 |
| 45544,5223 |
| Среднее | 5942,5 | 1151 | 1151 |
|
|
Расчетное значение Ŷi рассчитывается по формуле: Ŷi = a + b Xi.
Теперь рассчитаем ошибку модели Е по формуле:
Е =  , при n = 20; k = 2.
, при n = 20; k = 2.

50,3016
Е(%) = 50,301/1151*100% = 0,043 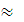 0,04*100%
0,04*100%  4 %, поэтому Е (%) имеет тесную обратную связь с критерием Фишера.
4 %, поэтому Е (%) имеет тесную обратную связь с критерием Фишера.
Следовательно, ошибка модели не превышает 15 %, поэтому можно считать, что модель хорошая.
Для того, чтобы вычислить коэффициент Стьюдента
 = (
= (
необходимо воспользоваться функцией FРАСПОБР( =0,95;
=0,95;  =20- 2)= =0,286301.
=20- 2)= =0,286301.
1.4. Расчет ошибок коэффициентов а и b
Таблица 4
Расчет ошибок коэффициентов а и b
| i | Xi | X_i^2 | (Xi-X ̅)2 |
| 1 | 2300 | 5290000 | 13267806,25 |
| 2 | 3400 | 11560000 | 6464306,25 |
| 3 | 3600 | 12960000 | 5487306,25 |
| 4 | 4000 | 16000000 | 3773306,25 |
| 5 | 4250 | 18062500 | 2864556,25 |
| 6 | 4500 | 20250000 | 2080806,25 |
| 7 | 5000 | 25000000 | 888306,25 |
| 8 | 5600 | 31360000 | 117306,25 |
| 9 | 5800 | 33640000 | 20306,25 |
| 10 | 6000 | 36000000 | 3306,25 |
| 11 | 6100 | 37210000 | 24806,25 |
| 12 | 6500 | 42250000 | 310806,25 |
| 13 | 6800 | 46240000 | 735306,25 |
| 14 | 7000 | 49000000 | 1118306,25 |
| 15 | 7200 | 51840000 | 1581306,25 |
| 16 | 7500 | 56250000 | 2425806,25 |
| 17 | 7800 | 60840000 | 3450306,25 |
| 18 | 8000 | 64000000 | 4233306,25 |
| 19 | 8500 | 72250000 | 6540806,25 |
| 20 | 9000 | 81000000 | 9348306,25 |
| Сумма | 118850 | 771002500 | 64736375 |
| Среднее | 5942,5 |
 Рассчитаем ошибку b (стандартное отклонение) по формуле:
Рассчитаем ошибку b (стандартное отклонение) по формуле:
0,006251837
где Е =50,3016 – вариация переменной Х.
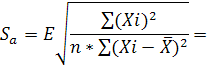 Рассчитаем ошибку а по формуле:
Рассчитаем ошибку а по формуле:
38,81687151
где n= 20.
1.5. Вычисление критерия Стьюдента для коэффициентов а и b
Теперь мы вычислим коэффициент Стьюдента а:
Tb =  =0,12741909 / 0,006251837 = 20,3810
=0,12741909 / 0,006251837 = 20,3810
При b=0,12741909 и Sb =. 0,006251837
 =
=  =393,812057/ 38,81687151= 10,145.
=393,812057/ 38,81687151= 10,145.
При а =393,812057 и  =38,81687151
=38,81687151
1.6.Определение критического значения критерия Стьюдента на уровне значимости α= 0,05.
С помощью статистической функции Excel СТЬЮДРАСПОБР
 (α= 0,05; m=20-2)= 2,100922 - критическое значение критерия Стьюдента, где n= 20 –количество выборки; k =2 – количество коэффициентов модели; α=0,05 – уровень значимости критерия и вероятность совершить ошибку при нулевой гипотезе.
(α= 0,05; m=20-2)= 2,100922 - критическое значение критерия Стьюдента, где n= 20 –количество выборки; k =2 – количество коэффициентов модели; α=0,05 – уровень значимости критерия и вероятность совершить ошибку при нулевой гипотезе.
1.6. Проверка достоверности коэффициента b.
Проверим 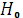 – нулевую гипотезу: : b= 0, так как коэффициент Стьюдента b по своей величине равен 20,8104.
– нулевую гипотезу: : b= 0, так как коэффициент Стьюдента b по своей величине равен 20,8104.
׀ 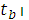 = 20,8104 является больше = 2,100922, то : b= 0 – отвергается с вероятностью 1 – α = 0,95.
= 20,8104 является больше = 2,100922, то : b= 0 – отвергается с вероятностью 1 – α = 0,95.
1.7. Вычисление доли объясненной вариации переменной Y.
Таблица 5
Расчет коэффициента детерминации и критерия Фишера
| i | Xi | Yi | (Yi) ̂ | (Yi-Y ̅)^2 | (Y ̂-Y ̅)^2 | (Yi-(Yi) ̂)^2 |
| 1 | 2300 | 760 | 686,8759642 | 152881 | 215411,1206 | 5347,124605 |
| 2 | 3400 | 750 | 827,0369634 | 160801 | 104952,0491 | 5934,693726 |
| 3 | 3600 | 800 | 852,5207814 | 123201 | 89089,84394 | 2758,432479 |
| 4 | 4000 | 860 | 903,4884174 | 84681 | 61261,9835 | 1891,242452 |
| 5 | 4250 | 880 | 935,34319 | 73441 | 46507,85971 | 3062,868677 |
| 6 | 4500 | 1020 | 967,1979625 | 17161 | 33783,18899 | 2788,055164 |
| 7 | 5000 | 1040 | 1030,907508 | 12321 | 14422,20674 | 82,67341869 |
| 8 | 5600 | 1050 | 1107,358962 | 10201 | 1904,54023 | 3290,05048 |
| 9 | 5800 | 1170 | 1132,84278 | 361 | 329,6846505 | 1380,659024 |
| 10 | 6000 | 1210 | 1158,326598 | 3481 | 53,67903359 | 2670,140507 |
| 11 | 6100 | 1250 | 1171,068507 | 9801 | 402,7449609 | 6230,180636 |
| 12 | 6500 | 1240 | 1222,036143 | 7921 | 5046,133575 | 322,7001676 |
| 13 | 6800 | 1300 | 1260,26187 | 22201 | 11938,15619 | 1579,118994 |
| 14 | 7000 | 1290 | 1285,745688 | 19321 | 18156,40038 | 18,0991723 |
| 15 | 7200 | 1280 | 1311,229506 | 16641 | 25673,49454 | 975,2820339 |
| 16 | 7500 | 1350 | 1349,455233 | 39601 | 39384,47945 | 0,296771239 |
| 17 | 7800 | 1400 | 1387,68096 | 62001 | 56017,87678 | 151,7587492 |
| 18 | 8000 | 1450 | 1413,164778 | 89401 | 68730,37078 | 1356,833586 |
| 19 | 8500 | 1450 | 1476,874323 | 89401 | 106194,0744 | 722,2292354 |
| 20 | 9000 | 1470 | 1540,583868 | 101761 | 151775,5902 | 4982,082427 |
| Сумма | 118850 | 23020 | 23020 | 1096580 | 1051035,478 | 45544,5223 |
| Среднее | 5942,5 | 1151 | 1151 |
Определение доли объема вариации. Коэффициент детерминации.
 =
=  = 151775,5902/101761 = 1,4914
= 151775,5902/101761 = 1,4914
При котором (Ŷi - ӯ)²= 151775,5902 – вариация регрессии;
(Yi - ӯ)² = 101761 – вариация переменной Y.
Проверка достоверности модели.
Для проверки достоверности модели выдвигаем «модель недостоверна» или Ŷi = ӯ или  =
= 
Если коэффициент Фишера F  (
( = n-k), то - отвергается с вероятностью совершенной отвергаемой ошибки с
= n-k), то - отвергается с вероятностью совершенной отвергаемой ошибки с  или
или  1 -
1 -  , и утверждается, что модель является достоверной с вероятностью 1- .
, и утверждается, что модель является достоверной с вероятностью 1- .
Если критерий Фишера 
 ( = n-k), то
( = n-k), то  - принимается и утверждается, что модель является недостоверной.
- принимается и утверждается, что модель является недостоверной.
Критерий Фишера означает во сколько раз дисперсия регрессии больше дисперсии остатка,чем больше критерий Фишера, тем точнее модель и тем меньше процент стандартной ошибки моделей.
1.9.Критерий Фишера

Где  - дисперсия обусловленная регрессией;
- дисперсия обусловленная регрессией;
 - дисперсия остатка.
- дисперсия остатка.
 ;
;  .
.
Критическое значение Фишера ( = n-k), значение определено на уровне значимости  и определяется по функции Excell FРАСПОБР.
и определяется по функции Excell FРАСПОБР.
Вычисление критерия Фишера.
F= = 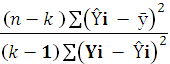 = (20-2)*1051035/(2-1)*45544 = 18918630/45544= 415,392
= (20-2)*1051035/(2-1)*45544 = 18918630/45544= 415,392
1.10.Расчет критерия Фишера критического.
При значениях  4,413873
4,413873
1.11. Проверка достоверности модели.
Проверим - она не достоверна. Так как коэффициент Фишера расчетное равен F =6400,43  равного 4,413873, то - модель не достоверна и поэтому отвергается с вероятностью 1- .
равного 4,413873, то - модель не достоверна и поэтому отвергается с вероятностью 1- .
Экономическая интерпретация доверительных интервалов для математического ожидания Y.
С вероятностью 0,95 можно утверждать, что математическое значение Y или среднее значение Y рассчитанные для всей генеральной совокупности для каждого фиксированного Хi , или уравнения регрессии, рассчитанные для всех данных генеральной совокупности, будет находиться в интервале от  до
до  .
.
Вычислим точечный и интервальный прогноз Y при ожидаемом значении Х:  = 31. Прогнозное значение Y для выборочной совокупности при ожидаемо значении.
= 31. Прогнозное значение Y для выборочной совокупности при ожидаемо значении.
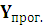 = а + b
= а + b  = 397,762046
= 397,762046
При а =393,812057; b= 0,12741909 ; = 31.
1.12.Расчет 95 %доверительного интервала, нахождение прогнозного и математического ожидания (среднее значение).
Y прогнозное по всем предприятиям отрасли (для всей генеральной совокупности) при ожидаемом значении вычисленном по формуле:


 *Е
*Е  = 436,3934
= 436,3934
 а + b = 397,762046 - прогнозное значение Y для выборочной совокупности;
а + b = 397,762046 - прогнозное значение Y для выборочной совокупности;
= 31 – ожидаемое значение Х;
(α= 0,05; m=20-2)= 2,100922 - критическое значение критерия Стьюдента;
n= 20 –количество выборки;
k =2 – количество коэффициентов модели;
Е=50,3016 - ошибка модели;
 = 64736375 - вариация переменной Х;
= 64736375 - вариация переменной Х;
 = 5942,5 – среднее значение Х.
= 5942,5 – среднее значение Х.
Ошибка прогноза:
 = E
= E  =38,63142014
=38,63142014
1.12. Вывод по определению интервального прогноза.
С вероятностью 95 % можно утверждать, что среднее значение объема производства для генеральной совокупности при ожидаемом значении Х = 31, будет находиться в интервале от 359,130 до 436,3934.
1.13. Расчет 95 % доверительного интервала, нахождение математического ожидания (среднего значения) по всем предприятиям отрасли (для всей генеральной совокупности при каждом значении Х)
 = * E
= * E 
При - математическое ожидание Y для i-го измерения;
 = а +bXi - расчетное значение Y для i-го измерения;
= а +bXi - расчетное значение Y для i-го измерения;
Xi - значение Х при i-ом измерении;
(α= 0,05; m=20-2)= 2,100922 - критическое значение критерия Стьюдента;
n= 20 –количество выборки;
k =2 – количество коэффициентов модели;
Е =50,3016 - ошибка модели;
= 64736375 - вариация переменной Х;
= 5942,5 – среднее значение Х.
Получение доверительных интервалов уравнения регрессии.
95 % доверительные интервалы математического ожидания Yi для значения вычисляется по формуле:
 =
=  -
-  E - нижний 95 % доверительный интервал для математического ожидания Y.
E - нижний 95 % доверительный интервал для математического ожидания Y.
 =
=  + E - верхний 95 % доверительный интервал для математического ожидания Y.
+ E - верхний 95 % доверительный интервал для математического ожидания Y.
Таблица 6
Расчет 95 % доверительного интервала математического ожидания Y
| i | Xi | Y_(p_t) | Y_(M(max)) | Y_(M(min)) |
| 1 | 2300 | 686,8759642 | 725,5073844 | 648,2445441 |
| 2 | 3400 | 827,0369634 | 865,6683835 | 788,4055432 |
| 3 | 3600 | 852,5207814 | 891,1522015 | 813,8893613 |
| 4 | 4000 | 903,4884174 | 942,1198376 | 864,8569973 |
| 5 | 4250 | 935,34319 | 973,9746101 | 896,7117698 |
| 6 | 4500 | 967,1979625 | 1005,829383 | 928,5665424 |
| 7 | 5000 | 1030,907508 | 1069,538928 | 992,2760874 |
| 8 | 5600 | 1107,358962 | 1145,990382 | 1068,727541 |
| 9 | 5800 | 1132,84278 | 1171,4742 | 1094,21136 |
| 10 | 6000 | 1171,068507 | 1209,699927 | 1132,437087 |
| 11 | 6100 | 1171,068507 | 1209,699927 | 1132,437087 |
| 12 | 6500 | 1222,036143 | 1260,667563 | 1183,404723 |
| 13 | 6800 | 1260,26187 | 1298,89329 | 1221,63045 |
| 14 | 7000 | 1285,745688 | 1324,377108 | 1247,114268 |
| 15 | 7200 | 1311,229506 | 1349,860926 | 1272,598086 |
| 16 | 7500 | 1349,455233 | 1388,086653 | 1310,823813 |
| 17 | 7800 | 1387,68096 | 1426,31238 | 1349,04954 |
| 18 | 8000 | 1413,164778 | 1451,796198 | 1374,533358 |
| 19 | 8500 | 1476,874323 | 1515,505743 | 1438,242903 |
| 20 | 9000 | 1540,583868 | 1579,215288 | 1501,952448 |
| Сумма | 118850 | 23032,74191 | 23805,37031 | 22260,11351 |
| Среднее | 5942,5 | 1151,637095 | 1190,268516 | 1113,005675 |
1.14. Эконометрический анализ линейной модели.
Линейная модель исследованного экономического процесса имеет вид:
 = 393,812057+0,12741909 *
= 393,812057+0,12741909 * 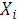 +
+ 
При Sb = 0,00625; Sa =38,81687151 ; Tb =20,3810 ; =10,145; = 2,100922;
 1,491490; F =415,429; = 4,413873.
1,491490; F =415,429; = 4,413873.
При проверки модель недостоверна и тогда можно сделать вывод: так как F- критерий Фишера F =415,429 = 4,413873, то данная гипотеза отвергается с вероятностью 1 -  =0,95.
=0,95.
Таким образом, модель зависимости У(Х) представленная в виде регрессивного уравнения:
=393,812057+0,12741909 * +  , построенного по выборочной совокупности равного 20 и является достоверной с вероятностью 0,95.
, построенного по выборочной совокупности равного 20 и является достоверной с вероятностью 0,95.
Проверка достоверности коэффициентов.
Проверяем, что b= 0 при этом абсолютная величина критерия Стьюдента коэффициента b:
׀ =20,3810  = 2,100922 значения критерия значения Стьюдента. Следовательно,: b= 0 и тогда отвергается с вероятностью
= 2,100922 значения критерия значения Стьюдента. Следовательно,: b= 0 и тогда отвергается с вероятностью
1 - = 0,95.
Коэффициент b=39,789474 достоверно отличается от нуля.
1.15. Общий вывод.
Линейная модель динамики объема производства может быть представлена в виде регрессивного уравнения:
= 393,812057+0,12741909 * + и является достоверной с вероятностью 0,95.
Коэффициент b= 0,12741909 достоверно отличается от нуля.
В прогнозном периоде в январе следующего года при Х ожид. = 31 точечный прогноз или наиболее вероятное прогнозное значение прироста объема производства будет равно 397,762046.
С вероятностью 0,95 можно утверждать, что математическое ожидание (среднее значение) прироста объема производства или интервальный прогноз будет находиться в пределе 359,130 до 436,3934.
1.16. Проверка расчетов при помощи функции Excell «ЛИНЕЙН».
Проверка всех расчетов в данном модуле производится с использованием статистической функции:
1) В рабочую ячейку функция с указанием диапазона ячеек для зависимой переменной Y и для объяснимой переменной Х;
2) Выделяется два столбца и пять строк, в которую необходимо вывести результаты расчетов данной функции.
Результаты функции «ЛИНЕЙН».
| 0,12741909 | 393,812057 |
| 0,006251837 | 38,81687151 |
| 0,958466758 | 50,30160275 |
| 415,3877929 | 18 |
| 1051035,478 | 45544,5223 |
Данные результатов расчетов коэффициентов и всех характеристик линейной модели позволяют произвести эконометрический анализ регрессивных моделей, то есть:
Е=50,30160275; b=0,12741909; а=393,812057 и т.д.
При сравнении расчетов полученных самостоятельно с помощью электронных таблиц и функции «ЛИНЕЙН» можно сделать заключение, что они почти идентичны.
1.17. Проверка достоверности модели по контрольной совокупности.
Проведем проверку достоверности модели с помощью внешних критерий. Для этого необходимо всю совокупность поделить на 2 части:
1) Обучающая (таблица 1) – совокупность состоит 2/ 3объема выборки;
2) Контрольная (таблица 2) – совокупность состоит 1/ 3объема выборки.
Таблица 1
Обучающая выборка
| i | Xi | Yi |
| 1 | 11 | 760 |
| 2 | 12 | 750 |
| 3 | 13 | 800 |
| 4 | 14 | 860 |
| 5 | 15 | 880 |
| 6 | 16 | 1020 |
| 7 | 17 | 1040 |
| 8 | 18 | 1050 |
| 9 | 19 | 1170 |
| 10 | 20 | 1210 |
| 11 | 21 | 1250 |
| 12 | 22 | 1240 |
| 13 | 23 | 1300 |
Таблица 2
Контрольная выборка
| 14 | 7000 | 1290 |
| 15 | 7200 | 1280 |
| 16 | 7500 | 1350 |
| 17 | 7800 | 1400 |
| 18 | 8000 | 1450 |
| 19 | 8500 | 1450 |
| 20 | 9000 | 1470 |
Долее вычисляем коэффициент ошибки линейной модели для обучающей выборки с помощью функции «ЛИНЕЙН».
| 0,124436302 | 393,9360203 |
| 0,019041889 | 83,75605436 |
| 0,859167825 | 59,77926528 |
| 42,70455079 | 7 |
| 152607,2983 | 25014,9239 |
И тогда  = 50,27473 + 0,769186
= 50,27473 + 0,769186  и Е
и Е  - ошибка модели.
- ошибка модели.
Затем при помощи той же функции вычислим ошибку модели на контрольную выборки с помощью функции «ЛИНЕЙН».
| 0,073170732 | 781,9512195 |
| 0,016452119 | 111,0261209 |
| 0,798226164 | 22,52370025 |
| 19,78021978 | 5 |
| 10034,84321 | 2536,585366 |
Стандартная статистическая проверка достоверности модели на контрольной совокупности имеет малую мощность. Поэтому необходимы новые методики проверки достоверности модели по контрольной совокупности в условиях малых выборок.
Задание 2.
Была произведена группировка однородных предприятий за 2009 год по двум показателям: годовой объем производства Y (тыс.руб.)и себестоимость 1 продукции Х (тыс.руб.)
Таблица 1
База данных
| i | Xi | Yi |
| 1 | 2300 | 1130 |
| 2 | 3400 | 923 |
| 3 | 3600 | 1030 |
| 4 | 4000 | 930 |
| 5 | 4250 | 750 |
| 6 | 4500 | 930 |
| 7 | 5000 | 810 |
| 8 | 5600 | 830 |
| 9 | 5800 | 650 |
| 10 | 6000 | 730 |
| 11 | 6100 | 680 |
| 12 | 6500 | 610 |
| 13 | 6800 | 600 |
| 14 | 7000 | 580 |
| 15 | 7200 | 570 |
| 16 | 7500 | 560 |
| 17 | 7800 | 540 |
| 18 | 8000 | 530 |
| 19 | 8500 | 530 |
| 20 | 9000 | 530 |
Необходимо:
1. Получить прогноз себестоимости 1 продукции при ожидаемом значении годового объема производства;
2. Определить оптимальный годовой объем производства, при котором себестоимость 1 продукции станет минимальной;
3. Провести сравнительный анализ следующих моделей:
- линейной.
Теперь перейдем к расчету следующих показателей:
Таблица 2
База данных нескольких предприятий
| i | Xi | Yi | Yi /Xi |
| 1 | 2300 | 1130 | 0,491304 |
| 2 | 3400 | 923 | 0,271471 |
| 3 | 3600 | 1030 | 0,286111 |
| 4 | 4000 | 930 | 0,2325 |
| 5 | 4250 | 750 | 0,176471 |
| 6 | 4500 | 930 | 0,206667 |
| 7 | 5000 | 810 | 0,162 |
| 8 | 5600 | 830 | 0,148214 |
| 9 | 5800 | 650 | 0,112069 |
| 10 | 6000 | 730 | 0,121667 |
| 11 | 6100 | 680 | 0,111475 |
| 12 | 6500 | 610 | 0,093846 |
| 13 | 6800 | 600 | 0,088235 |
| 14 | 7000 | 580 | 0,082857 |
| 15 | 7200 | 570 | 0,079167 |
| 16 | 7500 | 560 | 0,074667 |
| 17 | 7800 | 540 | 0,069231 |
| 18 | 8000 | 530 | 0,06625 |
| 19 | 8500 | 530 | 0,062353 |
| 20 | 9000 | 530 | 0,058889 |
Предположим, что в данном предприятии существенной является себестоимость продукции.
График 1 исходных данных.

Визуальный характер графика 1 показывает, что с увеличением количества себестоимости продукции сначала возрастает, а затем стремится к постоянной величине.
График 2 зависимости себестоимости продукции от численности предприятий.
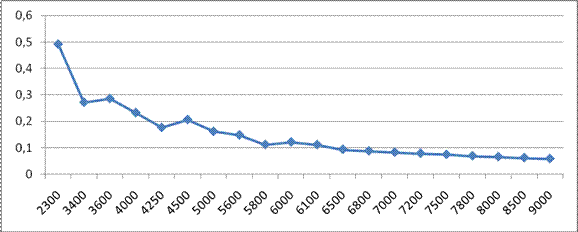
Визуальный анализ графика 2 показывает, что с увеличением количества предприятий до 3400 себестоимость продукции падает, а затем возрастает до 3600 себестоимости продукции, а затем постепенно, то падает, то возрастает.
В зависимости себестоимости продукции от численности предприятия (график 1) не является линейным и очевидно будет логистической с пределом равным максимальной себестоимости продукции.
Допущения.
Себестоимость продукции будет нелинейно зависеть от количества работников при условии, что на предприятии начиная с определенного количества работников, пропадает очередь.
Спецификация модели.
Воспроизведение нелинейной зависимости Y(X) будет производить с использованием следующей функции – линейной.
Спецификация модели зависимости Y(X) с помощью линейной функции  = a +b
= a +b  +e, при условии, что математическое ожидание М (Е)=0.
+e, при условии, что математическое ожидание М (Е)=0.
Идентифицируемость модели.
Исходные данные соответствуют модели, поэтому можно оценить её параметры.
Идентификация модели (оценка параметров модели):
Таблица 3
База данных для вычисления коэффициентов функции Ŷ =а+b
| i | Xi | Yi | Xi - Хсред. | Yi - Yсред. | (Xi - Хсред.)² | Ŷ |
|
|
| 1 | 2300 | 1130 | -3642,5 | 407,85 |
Сейчас читают про:
 8680 8680 8190 8190 |