 2018-02-20
2018-02-20 2970
2970
1.1. Требуемые свойства систем
распределенной обработки информации
Для достижения целей реальной и эффективной распределенной обработки информации вычислительные системы должны обладать рядом важнейших свойств (атрибутов), основными из которых являются прозрачность, открытость, переносимость приложений,гибкость, масштабируемость, безопасность.
Под прозрачностью (transparency) понимают «незаметность» для пользователя внутренней работы системы, что достигается путем сокрытия от пользователя аспектов организации и реализации распределенной обработки информации. Пользователи распределенной системы должны обладать доступом к ресурсам, не задаваясь вопросами о взаимодействии между процессами, о физическом месте размещения ресурсов, о том, какой именно процесс обслуживает тот или иной запрос пользователя.
В «Эталонной модели распределенной обработки информации в открытой системе» Международной организации по стандартизации ISO (International Standardization Organization) определены восемь «типов прозрачности», обеспечиваемых в распределенной системе, а именно:
1) Прозрачность доступа (access transparency) скрывает от пользователя детали реализации сетевых протоколов, обеспечивающих связь между удаленными компьютерами. Кроме того, она также предоставляет универсальные средства доступа к данным, хранимым в различных форматах по всей системе;
2) Прозрачность местоположения (location transparency) основана на прозрачности доступа и предназначена для сокрытия физического местоположения ресурсов в распределенной системе от клиента, желающего ими воспользоваться. Распределенная система, в которой реализована прозрачность местоположения, предоставляет доступ к удаленным файлам так, как если бы они являлись локальными;
3) Прозрачность сбоев (failure transparency) представляет собой метод обеспечения отказоустойчивости в распределенных системах. В случае выхода из строя какого-то ресурса либо компьютера сети пользователи сети могут заметить лишь некоторое снижение быстродействия. Прозрачность сбоев обычно реализуется путем репликации (replication) ресурсов либо создания контрольных точек восстановления. При применении репликации система обеспечивает дублирование ресурсов, выполняющих одни и те же функции. Даже если из строя выйдут все копии, кроме одной, распределенная система продолжит свое функционирование. Система, в которой используются контрольные точки, периодически выполняет сохранение информации о состоянии объектов (например, процессов), по которым они могут быть восстановлены, если сбой в распределенной системе приведет к потере этих объектов;
4) Прозрачность репликации (replication transparency) позволяет скрыть от пользователя факт существования нескольких копий того или иного ресурса, доступного в системе. В такой системе доступ к группе реплицированных ресурсов осуществляется аналогично тому, как если бы доступным являлся один-единственный ресурс;
5) Прозрачность постоянства (persistence transparency) скрывает от пользователя информацию о месте хранения ресурса (будь то ОЗУ или дисковый накопитель);
6) Прозрачность транзакций (transaction transparency) позволяет системе добиваться непротиворечивости, скрывая выполнение согласования в группе ресурсов. Транзакции включают запросы к службам (например, доступ к файлам и вызов функций), позволяющие менять состояние системы. Следовательно, транзакции часто требуют создания контрольных точек либо выполнения репликации в целях обеспечения реализации других задач в распределенных системах. Прозрачность транзакций позволяет скрывать от пользователя детали реализации этих служб;
7) Прозрачность миграции (migration transparency);
8) Прозрачность изменения местоположения (relocation transpa-rency).
Прозрачность миграции и прозрачность изменения местоположения скрывают от пользователя все перемещения компонентов системы. Прозрачность миграции маскирует перемещения объекта с одного места в другое в распределенной системе, например, перемещение файла с одного сервера на другой. Прозрачность изменения местоположения маскирует перемещения одного объекта по отношению к другим объектам, с которыми он поддерживает связь.
Под открытостью понимают использование синтаксических и семантических правил, основанных на стандартах. Правильный интерфейс обеспечивает возможность правильной совместной работы одного произвольного процесса, нуждающегося в интерфейсе, с другим произвольным процессом, представляющим интерфейс.
Переносимость приложений характеризует возможность приложения, выполненного для одной системы, работать в составе другой системы.
Гибкость характеризует легкость конфигурирования системы при изменении состава компонентов.
Масштабируемость, или расширяемость (scalability), означает способность распределенной системы увеличиваться в масштабах (возможность подключения к системе дополнительных компонентов) без влияния на работу существующих приложений и пользователей.Масштабируемость рассматривается по отношению к размеру (подключение дополнительных пользователей и ресурсов), к географическому положению (пространственное расположение пользователей и ресурсов), к административному устройству (управление в административно независимых организациях). Проблемы масштабируемости обычно связаны с «узкими» местами по обслуживанию (один сервер для множества клиентов), по данным (один файл с общей информацией), по алгоритмам (централизованный алгоритм и перегрузка коммуникационной сети).
Применение децентрализованных алгоритмов придает распределенной системе следующие характерные черты:
• никто не обладает полной информацией о системе;
• решения принимаются на основе локальной информации;
• сбой в одном месте не вызывает нарушения работы алгоритма;
• существования единого времени не требуется.
Требование масштабируемости является существенным препятствием на пути распространения систем, реализованных на базе локальных сетей, на уровень сетей глобальных.
Безопасность распределенных систем связана с обеспечением защиты ресурсов от атак со стороны враждебно настроенных пользователей. С целью повышения безопасности распределенные системы должны использовать защищенные каналы передачи данных, разрешать доступ к ресурсам только для авторизованных пользователей и допускать чтение передаваемых по сети данных только получателем.
1.2. Логические слои прикладного программного обеспечения
вычислительных систем
Прикладное программное обеспечение (ПО) может быть представлено в виде набора из трех частей, обычно называемых слоями (или уровнями):
1) слой (уровень) логики (алгоритмов) представления, или презентационный слой;
2) слой (уровень) бизнес-логики (вычислительных и управляющих алгоритмов), или слой прикладной логики;
3) слой (уровень) логики доступа к данным, или слой управления ресурсами.
Происхождение термина «слой» связано с моделью, которая рассматривает каждую часть приложения в зависимости от ее положения относительно пользователя: от «переднего слоя» (front-end) – логики представления до «заднего слоя» (back-end) – логики доступа к данным). Одна из функций «среднего слоя» (бизнес-логики) состоит в обеспечении двунаправленного преобразования между структурами данных высокого уровня переднего слоя и низкоуровневыми структурами заднего слоя.
Каждая из указанных частей прикладного программного обеспечения вовсе не должна полностью соответствовать отдельному модулю программы, отдельной программе, процессу, функции или процедуре – такое разделение достаточно полезно, но не необходимо. Очень простые приложения часто способны собрать все три части в единственную программу, а подобное разделение соответствует функциональным границам.
Пользователи взаимодействуют с частью, называемой логикой представления, которая управляет доступом к приложению. Независимо от конкретных характеристик этой части системы (интерфейс командной строки, сложные графические пользовательские интерфейсы, интерфейсы через посредника) ее задача состоит в том, чтобы обеспечить средства для наиболее эффективного обмена информацией между пользователем и системой. Поэтому на стадии проектирования приложения обычно много внимания уделяют именно этому компоненту, видимому со стороны внешнего мира.
Бизнес-логика определяет, для чего, собственно, предназначено приложение. В зависимости от конкретных функциональных требований и сложности задач может быть полезным подразделить эту часть на несколько компонентов. В этом случае конкретная реализация каждого компонента может быть представлена в виде набора процедур (библиотеки), класса или классов объектов, отдельных программ. Разделение слоя бизнес-логики приложения по границам между программами обеспечивает потенциальную возможность распределения этой части для выполнения на разных вычислительных устройствах.
Алгоритмы доступа к данным исторически рассматривались как специфический для конкретного приложения интерфейс к механизму постоянного хранения данных наподобие файловой системы или системы управления базами данных (СУБД). При помощи этой части приложение управляет соединениями с базой данных и запросами к ней (перевод специфических для конкретного приложения запросов на язык базы данных, получение результатов и перевод этих результатов обратно в специфические для конкретного приложения структуры данных). К этой части относят только специфический для приложения интерфейс к СУБД, но не ее саму.
Разделение функциональных алгоритмов на логику представления, бизнес-логику и логику доступа к данным предполагает разные уровни абстракции в различных частях приложения. Разложение же приложения на части согласно различным уровням абстракции представляет иерархию, которую можно использовать, чтобы разделить одну программу на несколько одновременно исполняемых модулей. Процесс, реализующий один или несколько уровней в этой иерархии, не должен ничего «знать» об уровнях, расположенных выше или ниже. Поэтому, за исключением обмена информацией между процессами в различных слоях, каждый процесс независим и самодостаточен. Процесс на одном уровне не нуждается в прямом доступе к структурам данных, расположенным на другом уровне. Следовательно, процесс может быть легко выделен в отдельно исполняемую программу.
Представленное послойное разделение прикладного программного обеспечения минимизирует взаимодействие между составными элементами (уменьшая объем передаваемой информации и упрощая алгоритмы, отвечающие за связь между процессами) и потому служит основой для выделения компонентов, которые могут быть распределены для работы на нескольких вычислительных машинах.
1.3. Варианты архитектурного построения систем
распределенной обработки информации
Исторически первым вариантом архитектурного построения вычислительной системы была архитектура с централизованной обработкой информации, когда одна мощная универсальная ЭВМ являлась единственной платформой, выполняющей все слои логики приложения. Централизованная архитектура характеризуется рядом существенных достоинств: простота разработка приложений, легкость обслуживания и управления. Именно эти достоинства обеспечили широкое практическое применение и долгое существование вычислительных систем с централизованной обработкой информации.
Появление классов мини- и микро-ЭВМ, а особенно класса персональных компьютеров (ПК) привело к разработке архитектур с децентрализованной обработкой информации, функционирующих в рамках парадигмы построения сетей, называемой моделью клиент/сервер (client/server model). Клиентами (client) в данном случае считаются вычислительные машины, нуждающиеся в получении тех или иных услуг, а серверами (server) – вычислительные машины, которые эти услуги предоставляют.
Первой разновидностью такой архитектуры может считаться так называемая архитектура с разделением файлов, которая включает несколько машин-клиентов, связанных сетью с машиной-сервером – файловым сервером. Файловый сервер загружает файлы из разделяемого местоположения, а прикладные программы полностью исполняются на компьютерах-клиентах. Эта архитектура достаточно проста в реализации, однако метафора совместного использования файлов крайне ограничивает число параллельных пользователей ввиду того, что при увеличении количества клиентов производительность системы существенно сокращается из-за частых конфликтов обновления данных и необходимости передачи по сети больших объемов трафика, требующих экономически затратного повышения пропускной способности сети.
Результатом усовершенствования архитектуры с разделением файлов стала замена файлового сервера сервером баз данных. Вместо передачи файлов целиком он пересылает только ответы на запросы клиентов, уменьшая нагрузку на сеть.
На уровне программного обеспечения разделение на клиента и сервер является логическим: процессы клиента и сервера могут физически размещаться как на одной, так и на разных машинах. Так в рассмотренных выше архитектурных построениях при размещении процессов клиента и сервера на одной машине (обычно принято называть эту машину звеном, или ярусом – от англ. «tier») говорят об однозвенной реализации архитектуры клиент/сервер, а при размещении процессов клиента и сервера соответственно на двух разных машинах говорят о двухзвенной реализации такой архитектуры. Таким образом под общим концептуальным названием модели «клиент/сервер» скрывается несколько вариантов архитектурного построения вычислительных систем, а именно архитектуры однозвенные, двухзвенные, трехзвенные и т. д. (обычно при числе звеньев более трех архитектуру называют многозвенной).
Однозвенная архитектура вырождается в классическую архитектуру с централизованной обработкой информации. В двухзвенной архитектуре приложение разделено на две части: клиентскую и серверную. Возможные варианты распределения слоев прикладного программного обеспечения в двухзвенной архитектуре представлены на рис. 1.1. Обычно сторона клиента содержит логику представления, а логика доступа к данным (как правило СУБД) и сама база данных находятся на стороне сервера. Алгоритмы бизнес-логики могут быть размещены либо полностью на стороне сервера (конфигурация так называемого «тонкого» клиента, рис. 1.1б), либо частично или полностью на машине клиента вместе с логикой представления (конфигурация так называемого «толстого» клиента, рис. 1.1в,1.1г). В случае размещения на стороне клиента лишь части логики представления, минимально достаточной для функционирования клиента (что характерно для современных архитектур так называемых «терминальных», или «бездисковых», рабочих станций), конфигурация обычно носит наименование «сверхтонкого» клиента (рис.1.1а).
Главными недостатками двухзвенной архитектуры являются необходимость либо наличия высокопроизводительных машин-клиентов (в конфигурации «толстый клиент»), либо относительно высокие требования к производительности сервера (в конфигурации «тонкий клиент»). Размещение в последнем случае на сервере как бизнес-логики, так и логики доступа к данным приводит не только к чрезмерной нагрузке сервера, но и к снижению гибкости его работы и универсальности построения. Тем не менее двухзвенные архитектуры получили с начала 1990-х годов весьма широкое практическое распространение в распределенных системах с небольшим числом клиентов (до нескольких десятков).
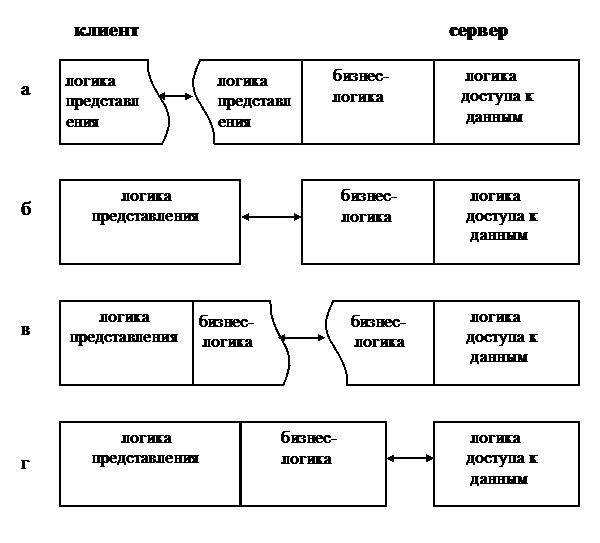
Рис.1.1. Варианты построения двухзвенных архитектур клиент/сервер
(конфигурации: а – «сверхтонкий» клиент; б – «тонкий» клиент;
в, г – «толстый» клиент)
Стремление повысить гибкость и масштабируемость многопользовательской распределенной системы привело к архитектурным решениям с тремя и более звеньями. С середины 1990-х годов интенсивное практическое внедрение получила трехзвенная архитектура, которая, как и двухзвенная, поддерживает концепцию «клиент/сервер», но разделяет систему по функциональным границам между тремя слоями: логикой представления, бизнес-логикой и логикой доступа к данным (рис. 1.2). В трехзвенной архитектуре появилось дополнительное звено (так называемый «сервер приложений»), целиком предназначенное для реализации бизнес-логики. Трехзвенная архитектура позволила более явно отделить прикладную логику от пользовательского интерфейса и уровня баз данных. Так как в трехзвенной архитектуре под бизнес-логику обычно выделяется отдельная машина-сервер, то это повышает гибкость распределенной системы (поскольку все три слоя отделены друг от друга, то становится возможным относительно легкое изменение либо перемещение любого из них без существенного влияния на остальные слои).

Рис.1.2. Вариант построения трехзвенной архитектуры клиент/сервер
Характерным примером использования трехзвенной архитектуры являются веб-приложения, которые реализуются посредством трех компонентов: веб-браузера клиента, веб-сервера и реляционной базы данных. Веб-браузер на машине-клиенте обычно отвечает за предоставление клиенту графического интерфейса, который облегчает доступ к удаленным документам. Браузер интерпретирует страницы, написанные с использованием языка HTML, и формирует их представление на мониторе клиента. Для извлечения удаленного документа браузер связывается с веб-сервером по протоколу HTTP, а затем сервер по тому же протоколу передает клиенту HTML-документ, найденный в базе данных. При этом уровень клиента, уровень сервера и уровень данных физически разнесены по разным машинам.
Именно выделение бизнес-логики в отдельное звено позволяет преодолеть фундаментальные ограничения двухзвенной архитектуры. Клиенты в этом случае не поддерживают постоянного соединения с базой данных, а обмениваются информацией со средним звеном только тогда, когда это необходимо. В то же время процесс среднего звена поддерживает всего несколько активных соединений с базой данных, но использует их многократно. Поэтому процессы в среднем звене могут предоставлять обслуживание теоретически неограниченному числу клиентов.
Дальнейшее увеличение гибкости и масштабируемости распределенных систем достигается переходом к многозвенным архитектурам, включающим более чем три звена, и соответствующим распределением слоев прикладного программного обеспечения (и их частей) по разным машинам. Например, слой логики доступа к данным может быть разделен на СУБД и собственно базу данных, хранимую на отдельном устройстве (или группе устройств). Такая конфигурация отражает реализацию распределенной СУБД (рис.1.3.).

Рис. 1.3. Вариант построения четырехзвенной архитектуры клиент/сервер
Перенос основных операций приложения на отдельный уровень позволяет с максимальной эффективностью распределить нагрузку на аппаратные устройства (трехзвенная модель на самом деле может быть многозвенной с разделением нагрузки на несколько серверов приложений) и обеспечивает безболезненное наращивание как функциональности приложения, так и числа обслуживаемых пользователей.
1.4. Понятие и назначение промежуточного слоя
программного обеспечения распределенных вычислений
Преимущества перехода к трехзвенным и далее к многозвенным архитектурам на практике не даются даром. Например, разработка прикладных программ, основанных на трехзвенной архитектуре, более затруднительна, чем для двухзвенной или централизованной архитектур. Преодолеть возникающие проблемы помогает так называемый промежуточный слой прикладного программного обеспечения или промежуточное (посредническое) программное обеспечение (middleware, MW).
В последнее время распределенные корпоративные приложения все более усложняются, интегрируя в себя разработки от разных подразделений, унаследованные приложения и вновь приобретенные готовые программные пакеты. Информационная система все чаще включает в себя модули, разработанные поставщиками и партнерами компании. Кроме того привычным явлением стали приобретения и объединения компаний, а поэтому инфраструктура корпоративного приложения должна уметь быстро интегрировать системы новых членов корпорации. Разные модули информационной системы компании решают разные бизнес-задачи, однако конечная цель при создании корпоративной системы – получить «единый образ» общего бизнес-процесса, благодаря которому пользователь быстро получит доступ к нужным операциям и ресурсам. Например, банковский служащий должен иметь возможность работать с любыми запросами своего клиента, независимо от того, в каком модуле общей системы они реально обрабатываются.
Чтобы создать такое мощное, интегрированное и хорошо масштабируемое решение необходима инфраструктура, которая бы объединяла разные модули и позволяла бы им взаимодействовать друг с другом, не вдаваясь в тонкости реализации коммуникаций. Основой такой инфраструктуры и является промежуточное программное обеспечение (ПО), бурное развитие которого связано именно с новыми задачами разработки интегрированных распределенных систем. Разные типы MW обслуживают приложения с разными требованиями к межмодульным коммуникациям. Кроме того тенденция последних лет – объектная ориентированность прикладных разработок и построение приложений из готовых компонентов – стимулирует развитие новых, объектных решений промежуточного слоя.
Современная эволюция систем MW идет в сторону их усложнения. Поначалу назначение MW ограничивалось построением более высокого уровня абстракции для взаимодействия приложения с ресурсами данных или различных компонентов приложения между собой. Разработчик приложения получал возможность использовать общие интерфейсы прикладного программирования (Application Program Interface, API), которые скрывали различия специфических интерфейсов коммуникационных протоколов более низкого уровня. Однако к настоящему времени этого уже явно недостаточно для построения сложных распределенных приложений. Современные решения MW не только обеспечивают межпрограммное взаимодействие, но и реализуют платформу для среднего звена – сервера приложений, обеспечивая обширный набор необходимых служб: управления транзакциями, именования, защиты и т. д.
Часто MW называют «клеем», соединяющим разрозненные части распределенного приложения. Компания ISG (International Systems Group) предлагает следующее определение MW, наиболее емко отражающее суть этой категории ПО. ISG определяет MW как специальный уровень прикладной системы, который расположен между бизнес-приложением и коммуникационным уровнем и изолирует приложение от сетевых протоколов и деталей операционных систем.
Вычислительная среда распределенных приложений может включать в себя множество различных операционных систем, аппаратных платформ, коммуникационных протоколов, баз данных и разнообразных средств разработки. Общие прикладные интерфейсы MW API позволяют реализовать взаимодействие между составными частями приложения, не вдаваясь в подробности этого сложнейшего конгломерата. Изменения в инфраструктуре не потребуют изменений в приложении, если они не затрагивают MW API.
MW отвечает за возможность обмена разнородной информацией. Формат представления данных на мэйнфреймах отличается от представления в Unix- или Windows-системах, поэтому прозрачное для пользователя преобразование данных также входит в задачу MW. Таким образом, в распределенной неоднородной среде MW играет роль «информационной шины», надстроенной над сетевым уровнем и обеспечивающей доступ приложения к разнородным ресурсам, а также независимую от платформ взаимосвязь различных прикладных компонентов.
Различия прикладных задач не позволяют построить универсальное MW, реализовав в одном продукте все необходимые возможности. Однако явная тенденция современного рынка – консолидация различных типов MW.
Существующий на сегодняшний день спектр продуктов MW можно разделить на два основных типа – промежуточное ПО доступа к базам данных и промежуточное ПО для межпрограммного взаимодействия. Промежуточное ПО доступа к базам данных относится к тематике распределенных баз данных, не входящих в круг вопросов, рассматриваемых в настоящем учебном пособии. Поэтому дальнейшее изложение будет посвящено рассмотрению промежуточного ПО для межпрограммного взаимодействия.
Резюме
Системы распределенной обработки информации должны обладать свойствами прозрачности, открытости, переносимости приложений, гибкости, масштабируемости, безопасности. Распределенная система позволяет скрыть от пользователя аспекты своей внутренней организации, физические места размещения ресурсов, вопросы реализации и взаимодействия процессов, обслуживающих запросы пользователя. Распределенная система способна увеличиваться в масштабах путем подключения к системе дополнительных компонентов без принципиального влияния на работу существующих приложений и пользователей.
Прикладное программное обеспечение в общем случае может быть представлено в виде композиции трех логических слоев (уровней): слоя логики представления, слоя бизнес-логики и слоя логики доступа к данным. Разделение функциональных алгоритмов на логику представления, бизнес-логику и логику доступа к данным предполагает разные уровни абстракции в различных частях приложения. Послойное разделение прикладного программного обеспечения минимизирует взаимодействие между составными элементами и служит основой для выделения компонентов, которые могут быть распределены для работы на нескольких вычислительных машинах.
Архитектурное построение вычислительной системы с централизованной обработкой информации предполагает выполнение всех логических слоев программного обеспечения на одной мощной универсальной машине. Децентрализованная обработка информации основывается на архитектурной модели клиент/сервер, где клиентами считаются вычислительные машины, нуждающиеся в получении тех или иных услуг, а серверами – вычислительные машины, которые эти услуги предоставляют. Под общим концептуальным названием модели клиент/сервер скрывается несколько вариантов архитектурного построения вычислительных систем, а именно архитектуры однозвенные, двухзвенные, трехзвенные и многозвенные (в зависимости от числа машин, на которых размещаются процессы клиента и сервера).
Промежуточное программное обеспечение позволяет осуществить связь и взаимодействие между разнородными компонентами распределенных систем, предоставляет стандартные интерфейсы программирования, реализует переносимость программ и прозрачность функционирования систем распределенной обработки информации.
Контрольные вопросы и задания
1. Дайте определение понятию «Распределенная обработка информации».
2. Поясните цель и практическое назначение систем распределенных вычислений.
3. Какие факторы определяют возможность так называемого «упрощения» работы пользователя распределенной вычислительной системы?
4. Перечислите и охарактеризуйте важнейшие свойства, которыми должны обладать вычислительные системы для достижения целей эффективной распределенной обработки информации.
5. Что понимают под свойством прозрачности вычислительной системы и какие «типы прозрачности» определены в эталонной модели Международной организацией по стандартизации?
6. Какие характерные черты приобретает распределенная система в случае применения децентрализованных алгоритмов функционирования?
7. Назовите и дайте характеристику логическим слоям прикладного программного обеспечения вычислительных систем.
8. Какую основную задачу решает презентационный слой прикладного программного обеспечения?
9. Какими свойствами обладает архитектура вычислительной системы с централизованной обработкой информации?
10. Дайте определение понятиям «клиент» и «сервер».
11. Перечислите и охарактеризуйте варианты архитектурного построения систем распределенной обработки информации.
12. Опишите возможные варианты и особенности построения двухзвенной архитектуры распределенной системы.
13. Поясните принципиальное отличие конфигураций «тонкий» и «толстый» клиент. Каковы их преимущества и недостатки?
14. Какие факторы являются главными недостатками двухзвенной архитектуры распределенных систем?
15. Какие преимущества дает увеличение числа звеньев в системах распределенной обработки информации?
16. Каково назначение промежуточного слоя прикладного программного обеспечения?
17. Каким образом в промежуточном слое программного обеспечения реализуется свойство прозрачности?
18. Охарактеризуйте основные типы программных продуктов промежуточного слоя.

