2020-01-14
2020-01-14 105
105
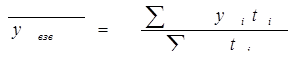
Для интервального ряда средний уровень рассчитывается по среднеарифметической простой и взвешенной (если интервалы в рядах, соответственно, равноотстоящие и неравноотстоящие):
где n – число уровней
ti – длительность интервала времени между уровнями
Примеры.
1) Предприятие выпускает продукцию по кварталам года
I кв. – 300 тыс.,
II кв.– 250 тыс.,
III кв.– 100 тыс.,
IV кв.– 500 тыс.
Т.к. ряд интервальный с равноотстоящими интервалами, применим среднюю арифметическую простую:
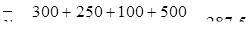
2) Предприятие выпустило продукции за первые 3 месяца года на 300 тыс., за последующие 2 месяца – на 250 тыс., за 1 месяц – на 100 тыс. и за оставшиеся 6 месяцев – на 500 тыс. Т.к. это интервальный ряд с неравноотстоящими интервалами, применяем среднюю арифметическую взвешенную:
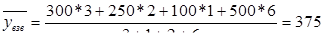
Для моментного ряда c равноотстоящими интервалами средний уровень исчисляется по формуле средней хронологической простой, которая имеет следующий вид:
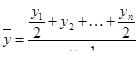
Пример. Остатки оборотных средств предприятия составили
на 1.01 – 110 тыс.,
на 1.02 – 120 тыс.,
на 1.03 – 130 тыс.,
на 1.04 – 140 тыс.,
на 1.07 – 170 тыс.
Определим средние остатки оборотных средств за I квартал:
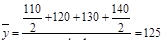
В случае если интервалы неравноотстоящие, применяют формулу средней хронологической взвешенной:
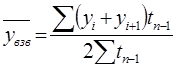
В нашем примере средние остатки оборотных средств за полугодие:
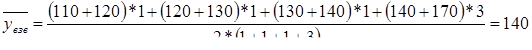
Эту задачу можно решить и другим способом (в несколько действий) – используя среднеарифметическую простую:
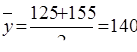
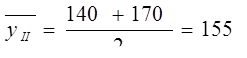

10.3 Темпы роста и прироста
Темп роста (Wachstumsfaktor, Growth factor) отвечает на вопрос, во сколько раз изменилось явление и получается делением последующего уровня ряда на предыдущий.
Темп прироста (Wachstumsrate, Growth rate) отвечает на вопрос, на сколько увеличилось явление и получается делением абсолютного прироста на преды  дущий уровень.
дущий уровень.
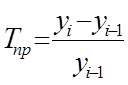
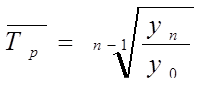
Среднегодовой темп роста находится по средней геометрической:
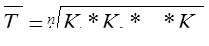
Пример. Фирма произвела услуг в 1 году – на 100 у.е., во 2 году – на 120 у.е.,
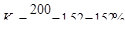
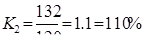
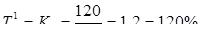
в 3 году – на 132 у.е. и в 4 году – на 200 у.е.
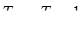
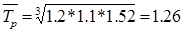
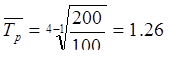
Среднегодовой темп прироста нельзя находить как среднее из годовых темпов прироста. Для этого существует формула:
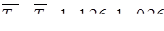
Т.е. среднегодовой темп прироста составил 0,26 или 26 %.
10.4 Правила составления рядов динамики
Анализ рядов динамики дает правильные результаты при условии правильного составления ряда. Для этого существуют следующие правила:
1) Все уровни динамического ряда должны быть сопоставимыми во времени. Например, численность населения обычно указывается на начало года.
2) Все уровни динамического ряда должны быть сопоставимыми в пространстве, т.е. относиться к одной и той же территории.
Исключение допускается только в случае, когда территориальные изменения рассматриваются как самостоятельный показатель динамики (например, в 1993 г. в состав Нижегородской области вошел Сокольский район
Ивановской области).
3) Все уровни динамического ряда должны быть сопоставимыми по методологии расчета.
Если способы расчета меняются с течением времени, то нужно сделать пересчет. Например, для составления динамического ряда произведенного в Нижегородской области ВВП данные по производству совокупного общественного продукта (СОП), рассчитывавшегося до начала 90-х годов, пересчитываются в ВВП.
10.5 Преобразование рядов динамики
При анализе рядов динамики приходится делать некоторые преобразования, которые улучшают условия анализа.
I. Сглаживание и выравнивание ряда (die Glättung, smoothing)
Это делается для погашения случайной колеблемости уровней ряда. Иными словами сглаживание и выравнивание выявляют основное направление развития явления (тренд).
Существуют следующие методы сглаживания и выравнивания:
1) выявление тренда визуальным методом (на графике)
Этот метод наиболее прост и наименее точен.
2) механическое выравнивание
Оно заключается в укрупнении интервалов путем расчета средних уровней не за один период, а за несколько. Например, этот прием часто используют при обработке динамических рядов урожайности сельскохозяйственных культур, рассчитывая среднюю урожайность не за 1 год, а за 5 лет.
3) метод скользящей средней
Этот метод применяется следующим образом (см. данные табл. 10.1).
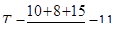
Скользящая средняя заменяет несколько уровней одним значением. В первую очередь выбирается интервал сглаживания (в нашем примере – 3 мес.). Чем он больше, тем сглаживание сильнее
Далее подсчитывают значения средней:
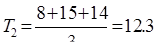
и т.д.
Таблица 10.1
Сведения о продажах продукции по месяцам на предприятии N
| t | -3 | -2 | -1 | 1 | 2 | 3 | ||
| -2 | -1 | 0 | 1 | 2 | - | |||
| Месяц | январь | февраль | март | апрель | май | июнь | ||
| Yi | 10 | 8 | 15 | 14 | 19 | 9 | ||
| Т | - | 11 | 12,3 | 16 | 14 | - | ||
| Ŷ | 8,4 | 10,8 | 13,2 | 15,6 | 18 | - | ||
| S | 1,6 | -2,8 | 1,8 | -1,6 | 1 | |||
Недостаток этого метода в том, что теряются уровни в начале и в конце ряда, а при криволинейном развитии явления скользящая средняя смещает уровни ряда. Для избежания этого применяют более сложный расчет скользящей средней взвешенной.
4) аналитическое выравнивание. В этом случае фактические уровни заменяются уровнями, вычисленными на основе определенной функции (кривой).
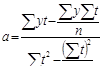


В нашем случае это линейная зависимость (уравнение прямой), хотя выравнивание может осуществляться и с помощью гиперболы, параболы, показательной, экспоненциальной и др. функций:
Коэффициенты a и b находятся по методу наименьших квадратов. Расчет можно значительно упростить, если изменить нумерацию уровней ряда (так, чтобы Σ ti = 0 и при четном, и при нечетном числе уровней) – см. верхние строки табл. 10.1.
 |
Тогда получим следующие формулы коэффициентов:
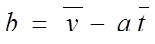
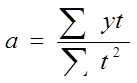
Пример (см. табл. 10.1).
 |
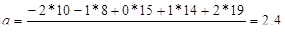
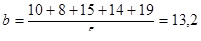
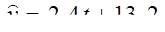
Теперь подсчитываем выровненные значения y:
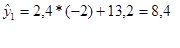
и т.д.
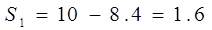
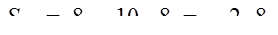
Далее можно вычислить разницу между трендовыми значениями и первоначальными уровнями ряда. Это даст нам возможность оценить и, если нужно, устранить влияние сезонной компоненты.
II. Приведение ряда динамики к одному основанию
Используется в случае, если необходимо сравнение или сопоставление тенденций в нескольких рядах.
Примеры.
1) Начальные уровни рядов динамики находятся в различных периодах (табл. 10.2). По какому предприятию темп роста выпуска продукции выше?
Таблица 10.2
Выпуск продукции по двум предприятиям (в %)
| Ряд | 1985 | 1986 | 1987 | 1988 | 1989 | 1990 |
| 1 | 100 | 110 | 125 | 130 | 135 | 140 |
| 1΄ | - | - | 100 | 104 | 108 | 112 |
| 2 | - | - | 100 | 108 | 114 | 120 |
1΄ - это 1-й ряд, приведенный к другому основанию (к 1987 г.) по пропорции:
Тр1987 = 100 % Тр1988 = 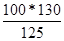 = 104 % и т.д.
= 104 % и т.д.
Таким образом, в сопоставимом виде у предприятия 2 темп роста выпуска продукции выше, чем у предприятия 1.
2) уровни ряда динамики выражены абсолютными величинами и начальные уровни имеют различные размеры (табл. 10.3). По какому предприятию темп роста выпуска продукции выше?
Таблица 10.3
Выпуск продукции по двум предприятиям (в тыс. руб.).
| Предприятие | 1995 | 1996 | 1997 | |
| Абсолютные величины (тыс. руб.) | 1 | 2 | 3 | 4 |
| 2 | 5 | 7 | 8 | |
| Относительные величины (%) | 1 | 100 | 150 | 200 |
| 2 | 100 | 140 | 160 |
При сравнении динамики выпуска продукции двух предприятий после перевода абсолютных значений в относительные можно сделать вывод о более высоких темпах роста на первом предприятии.
3) Ряды динамики можно приводить к одному основанию не по одному показателю, а по нескольким показателям.
Так, например, на предприятии имеются данные о средней производительности труда и заработной плате (табл. 10.4.). Как соотносятся между собой темпы роста этих двух показателей?
Таблица 10.4.
Средняя производительность труда и заработная плата по предприятию
| Годы | Произ. труда (выработка), изд./месяц | Заработная плата, у.е. | Произв. труда, % | Заработная плата, % |
| 1995 | 650 | 120 | 100 | 100 |
| 1996 | 695 | 123 | 106,9 | 102,5 |
| 1997 | 725 | 125 | 111,5 | 104,2 |
| 1998 | 747 | 129 | 115,0 | 107,5 |
| 1999 | 764 | 131 | 117,5 | 109,2 |
| 2000 | 779 | 133,5 | 119,9 | 111,3 |
После перевода показателей в относительный вид можно сказать, что темп роста производительности труда за рассматриваемый период опережал темп роста заработной платы. Следовательно, предприятие развивалось устойчиво, его конкурентоспособность возрастала.
III. Смыкание рядов динамики
Метод применяется, если необходимо совместить два динамических ряда, характеризующих одно явление.
Пример.
Таблица 10.5
Данные о продажах предприятия
| Годы | Объем продаж до реорганизации | Объем продаж после реорганизации | Сомкнутый ряд в относительных величинах | Сомкнутый ряд в абсолютных величинах |
| 1996 | 1995 | - | 95 | 1895 |
| 1997 | 2058 | - | 98 | 1955 |
| 1998 | 2100 | 2000 | 100 | 2000 |
| 1999 | - | 2040 | 102 | 2040 |
| 2000 | - | 2100 | 105 | 2100 |
 |  |  |  |
Принимаем 1998 г. за 100 %, а остальные уровни пересчитываем.
Иногда рассчитывают коэффициент до и после реорганизации:
 |  |  |
Теперь можно составить сомкнутый ряд по абсолютным значениям:
IV. Интерполяция и экстраполяция
Интерполяция – это нахождение уровней внутри динамического ряда.
Экстраполяция - это нахождение уровней за пределами динамического ряда.
Неизвестные уровни находятся с помощью всех перечисленных выше методов.
10.6 Определение и устранение влияния сезонных колебаний
Для определения сезонных колебаний существует два способа:
I. Если мы исходим из того, что тренд не определен или неизвестен.
В таком случае цель состоит в нахождении ряда динамики, очищенного от сезонных колебаний, прохождение которого похоже на тренд (показывает такую же, как тренд, тенденцию развития).
Пример.
Таблица 10.5
Оборот предприятия за три года
| Месяц | Оборот в тыс. у.е. (Yij) | Относительные показатели (Sij) | ΣSij | Сезонный индекс si | Si | Yi - Si | ||||||||
| 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | |||
| 1 | 20 | 21 | 21 | 95.2 | 91.3 | 87,5 | 274.0 | 91.3 | -1.9 | -2.0 | -2.0 | 21.9 | 23.0 | 23.0 |
| 2 | 22 | 24 | 25 | 104.8 | 104.3 | 104.2 | 313.3 | 104.5 | 0.9 | 1.0 | 1.1 | 21.1 | 23.0 | 23.9 |
| 3 | 24 | 25 | 28 | 114.3 | 108.7 | 116.7 | 339.7 | 113.2 | 2.8 | 2.9 | 3.3 | 21.2 | 22.1 | 24.7 |
| 4 | 21 | 23 | 23 | 100.0 | 100.0 | 95.8 | 295.8 | 98.6 | -0.3 | -0.3 | -0.3 | 21.3 | 23.3 | 23.3 |
| 5 | 18 | 21 | 21 | 85.7 | 91.3 | 87.5 | 264.5 | 88.2 | -2.4 | -2.8 | -2.8 | 20.4 | 23.8 | 23.8 |
| 6 | 20 | 19 | 20 | 95.2 | 82.6 | 83.3 | 261.1 | 87.0 | -3.0 | -2.8 | -3.0 | 23.0 | 21.8 | 23.0 |
| 7 | 20 | 22 | 22 | 95.2 | 95.7 | 91.7 | 282.6 | 94.2 | -1.2 | -1.4 | -1.4 | 21.2 | 23.4 | 23.4 |
| 8 | 24 | 27 | 28 | 114.3 | 117.4 | 116.7 | 348.4 | 116.1 | 3.3 | 3.7 | 3.9 | 20.7 | 23.3 | 24.1 |
| 9 | 26 | 28 | 30 | 123.8 | 121.7 | 125.0 | 370.5 | 123.5 | 4.9 | 5.3 | 5.7 | 21.1 | 22.7 | 24.3 |
| 10 | 21 | 23 | 25 | 100.0 | 100.0 | 104.2 | 304.2 | 101.4 | 0.3 | 0.3 | 0.3 | 20.7 | 22.7 | 24.7 |
| 11 | 19 | 22 | 23 | 90.5 | 95.7 | 95.8 | 282.0 | 94.0 | -1.2 | -1.4 | -1.5 | 20.2 | 23.4 | 24.5 |
| 12 | 17 | 21 | 22 | 81.0 | 91.3 | 91.7 | 264.0 | 88.0 | -2.3 | -2.9 | -3.0 | 19.3 | 23.9 | 25.0 |
| 252 | 276 | 288 | 1200.0 | |||||||||||
Руководство предприятия хотело бы знать, насколько велико влияние сезонных условий на оборот (такая постановка вопроса типична для некоторых отраслей, например, для сельского хозяйства).
1) Определим среднемесячный оборот по годам
1 год – 252/12=21
2 год – 276/12=23
3 год – 288/12=24
2) Рассчитаем относительные показатели (sij)
Относительный показатель = (Реальный месячный оборот)/
(Средний оборот за месяц)
 |
Январь 1-го года:
Результат (95,2%) показывает, что оборот в этот период был на 4,8% ниже среднемесячного уровня.
Январь 2-го года:
 |
и т.д.
3) Рассчитанные величины для одноименных месяцев складываются, и вычисляется их средняя, которая называется сезонным индексом или индексом сезонности (si)
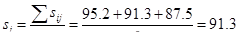
Это означает, что за три года оборот предприятия в январе-месяце подвержен влиянию сезонных колебаний на 8,7% ниже нормального годового значения.
Все двенадцать индексов сезонности образуют так называемую сезонную волну (1200,0), которая тем сильнее, чем больше отклонения в каждом месяце от нормального значения (100%).
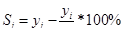
4) Исключаем влияние сезонной компоненты (Si)
Чтобы получить значения ряда, очищенные от сезонных колебаний (выровненные значения), нужно от каждого уровня ряда отнять сезонную компоненту.
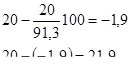
Январь 1-го года:
Это означает, что если бы в этот период не было бы сезонных колебаний, то оборот составил бы 21,9 тыс. у.е.
II. Если нам известен тренд ряда
1-й шаг. Расчет тренда любым способом
2-й шаг. Определение вида связи компонент ряда и расчет сезонных значений в виде разницы или частного.
3-й шаг. Определение сезонной компоненты, как среднеарифметическую из сезонных значений.
4-й шаг. Исключение влияния сезонной компоненты.
ТЕМА 11. Выборка
Stichprobenverfahren Sampling
11.1 Понятие выборки
Выборка (Stichprobe, sample) – это один из видов несплошного наблюдения, когда о целом судят по части. В качестве теоретических основ выборочного наблюдения используется теория вероятностей и математическая статистика, в особенности теоремы Бернулли, Пуассона, Чебышева, Ляпунова, закон больших чисел.
Для того, чтобы выборка давала хорошие результаты, необходим случайный отбора, т.е. избежание преднамеренности (в прикладных науках, например, в маркетинговых исследованиях, бывают исключения).
Условия проведения выборки:
1) требуемая точность устанавливается самостоятельно;
2) выборка должна давать значительное сокращение расходов по сравнению со сплошным наблюдением.
Причины проведения выборки:
1) невозможность сплошного наблюдения;
2) повышенная трудоемкость сплошного наблюдения;
3) необходимость проверки результатов сплошного наблюдения.
Условные обозначения, используемые в этой теме:
N – объем генеральной совокупности;
n – объем выборки;
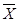 - генеральная средняя;
- генеральная средняя;
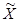 - средняя выборки;
- средняя выборки;
w – выборочная доля;
p – генеральная доля;
σ² - генеральная дисперсия;
s² - выборочная дисперсия.
11.2 Способы отбора
Существует несколько способов, обеспечивающих случайность и исключающих преднамеренность отбора:
1) собственно случайный отбор (Zufallsstichprobe, random sample) - это отбор по жребию, по таблице случайных чисел.
Случайный отбор бывает повторным (отобранная единица совокупности может снова попасть в выборку) и бесповторным (отобранная единица совокупности вновь в выборку не возвращается). Пример повторного отбора – измерение плотности пассажиропотока на определенном городском маршруте. Пример бесповторного отбора – лотерея "Спортлото".
Бесповторный отбор более точен, но и более сложен.
2) механический отбор (Mechanische Auswahl, mechanical sample) - отбор из списков.
На всю генеральную совокупность составляется общий список и далее из него через равный интервал отбирают нужное количество единиц.
Размер интервала равен 1/долю выборки. Так, при 2 %-ной выборке интервал будет равен 1/0,02 = 50 ед.
Общий список составляется двумя способами: единицы совокупности располагаются в случайном порядке или в определенном порядке, имеющем прямое или косвенное отношение к цели исследования. При первом варианте отбор можно начинать с любой единицы, при втором – с середины первого интервала. Примеры: табельные номера работников предприятия (первый вариант), алфавитный список студентов потока (второй вариант)
3) типический отбор (geschichtete Auswahl, stratified sample)
При этом способе генеральная совокупность разбивается на типические группы, которые должны как можно сильнее отличаться друг от друга и быть однородными внутри. Тогда типический отбор дает хорошие результаты. Затем из каждой типической группы первыми двумя способами отбирают единицы в выборочную совокупность.
Пример. Обследуются предприятия различных форм собственности. Формы собственности представляют различные типические группы.
4) серийный отбор (Klumpenauswahl, cluster sample)
Генеральная совокупность разбивается на серии. В отличие от типических групп, серии должны как можно менее отличаться друг от друга и быть разнородными внутри. Обследуется часть серий, зато внутри серии – как правило, все единицы. Отбор из серий в выборку также осуществляется первыми двумя способами.
Пример. Обследование одного ящика пива из партии.
11.3 Ошибки выборки
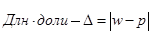
При проведении любого наблюдения случаются ошибки. Выборка характеризуется прежде всего ошибками представительства или репрезентативности, суть которых заключается в отклонениях выборочных значений от генеральных:
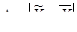
где Δ – предельная ошибка выборки (absolute Stichprobenfehler, absolute sampling error)
Для каждого способа отбора существуют свои формулы ошибок.
1) Случайный отбор
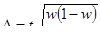
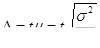
- повторный случайный отбор:
где μ средняя (стандартная) ошибка выборки;
t – кратность средней ошибки выборки;
n – объем выборки.
Кратность средней ошибки выборки связывает наши расчеты с определенной вероятностью p, что расчет ошибки правильный:
при p=0,997 t=3,
при p=0,954 t=2,
при p=0,683 t=1 и т.д. (см. таблицу нормального распределения).
Данная формула верна лишь для случая нормального распределения. В случаях отклонений от нормального распределения пользуются таблицей распределения Стьюдента. Например, при n<30 - случай малой выборки – в знаменателе будет n-1, а t будет определяться по таблице распределения Стьюдента, у которой 2 входа: вероятность p и число степеней свободы k:
При p=0,95 t=12,71 (k=1),
При p=0,95 t= 4,3 (k=2),
При p=0,95 t= 3,18 (k=3),
При p=0,95 t= 2,79 (k=4),
При p=0,95 t= 1,96 (k = ¥) и т.д. (см. таблицу распределения Стьюдента)
Пример. Из стада в 10 тыс. коров обследовано 100 коров. Половина из обследованных признана породистой. Определить долю породистых коров во все стаде.
Доля породистых коров во всем стаде p = w ± D.= 0,5 ± 0,098 
w = 0,5
При t = 1,96 (вероятность 95 %) D = 1,96 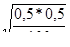 = 0,098.
= 0,098.
Т.е. с вероятностью 0,95 можно утверждать, что во всем стаде породистых коров 50 ± 9,8 %.
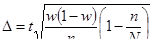
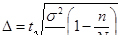
- бесповторный случайный отбор:
2) Механический отбор
Используются те же формулы, хотя фактически ошибки при данном виде отбора составляют меньшую величину. Следствие отрицательное – ошибки завышаются, следствие положительное – повышается уверенность в надежности результата.
3) Типический отбор
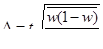
Вместо общей дисперсии (σ²) используется средняя из внутригрупповых дисперсий 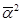 :
:
- повторный типический отбор:
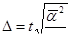
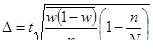
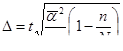
- бесповторный типический отбор:
4) Серийный отбор
Здесь вместо общей дисперсии используется межгрупповая дисперсия δ²:
- повторный серийный отбор
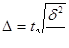
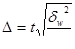
- бесповторный серийный отбор
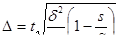
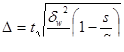
где s – число отобранных серий,
S – общее число серий в генеральной совокупности.
В случае, если внутри серий обследуются не все единицы, формулы усложняются:
- повторный серийный отбор
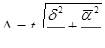
- бесповторный серийный отбор
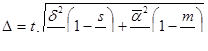
где m – число отобранных в сериях единиц
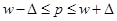
После нахождения величины ошибки определяются доверительные интервалы:
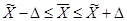
11.4 Необходимая численность выборки
1) Случайный отбор
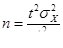
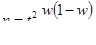
- повторный отбор
На практике при определении численности выборки встает вопрос о нахождении генеральной дисперсии. Существуют следующие способы:
а) если ранее уже проводилось обследование данной совокупности, то дисперсия берется из архива;
б) проводится пробное обследование, чтобы по его результатам ориентировочно определить выборочную дисперсию;
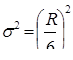
в) самый дешевый и распространенный способ – взять максимально возможную дисперсию - σ² = max из предполагаемых. Для этого используют размах вариации R. По правилу шести s он приблизительно равен 6s: R» 6s. Тогда s» R/6, а
Если речь идет о доле, то w(1-w) = 0,5 (1-0,5) = 0,25.
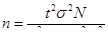

- бесповторный отбор
Пример. Определить численность выборки, если
D2 = 0,01
N = 100
s2 = 1
t = 2
Тогда n = 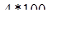 Þ лучше провести сплошное обследование, а не выборочное.
Þ лучше провести сплошное обследование, а не выборочное.
2) Механический отбор
Используются те же формулы.
3) Типический отбор
В формулах вместо выборочной дисперсии (σ²) используется средняя из внутригрупповых дисперсий :
статистический наблюдение индекс население
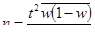
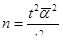
- повторный отбор:
- бесповторный отбор:
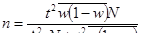
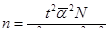
4) Серийный отбор
В формулах вместо выборочной дисперсии σ² используется межгрупповая δ²:
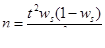
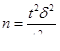
- повторный отбор:
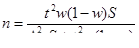
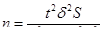
- бесповторный отбор:
11.5 Практика применения выборки
Основные направления применения выборочного метода на практике:
1) маркетинговые исследования;
2) изучение общественного мнения;
3) обследование уровня цен и объемов продаж в регионах;
4) оценка качества продукции;
5) статистический контроль производства;
6) обработка материалов переписи населения и переписей вообще.
[1] По материалам Доклада Нижегородского территориального управления Министерства РФ по антимонопольной политике и поддержке предпринимательства "Состояние конкуренции на товарных рынках Нижегородской области в 1998 г."
[2] Более подробно о χ²-тесте и других тестах – см. раздел статистическая проверка гипотез