 2020-05-25
2020-05-25 1852
1852Маркетинговые исследования. Формирование выборки.
https://www.youtube.com/watch?v=h8sfukQP5I4
Процедура формирования выборки
Основным способом получения данных в первичных маркетинговых исследованиях является выборочное наблюдение. Во избежание ошибок и неверных выводов маркетинговые службы должны строго придерживаться определенных правил отбора единиц в выборочную совокупность, оценивать надежность и репрезентативность выборки для того, чтобы распространить выборочные данные на генеральную совокупность.
Процесс формирования выборки состоит из нескольких этапов, целью которого является получение конкретного варианта выборки (рис. 1).
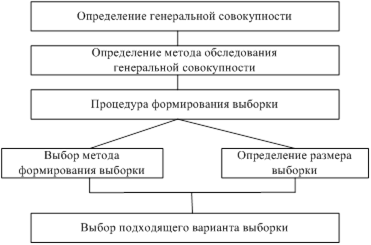
Рис. 1. Процесс формирование выборки
На первом этапе определяется генеральная совокупность. Генеральная совокупность -- это множество всех единиц, являющихся объектами исследования.
На этом этапе подготовки исследования необходимо определить, какие субъекты составляют исследуемую генеральную совокупность. Как правило, субъекты, входящие в генеральную совокупность неоднородны, особенно сложно представить все элементы генеральной совокупности, состоящей из организаций, поскольку не все фирмы афишируют свою деятельность. В качестве генеральной совокупности могут быть определены рынок в целом, сегмент рынка или целевая группа субъектов.
На втором этапе определяется метод обследования генеральной совокупности. В зависимости от объема генеральной совокупности и целей исследования могут быть использованы методы сплошного или выборочного обследования.
Метод сплошного обследования заключается в изучении всех единиц генеральной совокупности. Метод связан с высокими затратами на проведение исследования, его использование оправдано, например, в случае малого количества потребителей, представляющих сегмент, или в случае, когда объем покупок данных клиентов составляет значительную долю от емкости рынка в целом.
Метод выборочного обследования обеспечивает меньшую точность по сравнению с методом сплошного обследования, однако он менее трудоемок. Целесообразно использование данного метода при наличии большого числа однородных единиц генеральной совокупности. Выборка -- это группа объектов исследования, которая является носителем характеристик всех единиц генеральной совокупности, например группа потребителей, представляющих интересы и вкусы всего целевого рынка.
Метод выборочного обследования предоставляет информацию о генеральной совокупности на основании обследования только ее части, поэтому данные, полученные в ходе выборочного обследования, имеют вероятностный характер. На практике это означает, что в результате исследования определяется не конкретное значение, а интервал, в котором находится искомое значение. Вероятность, с которой можно утверждать, что ошибка выборки не превысит некоторую заданную величину, называется доверительной вероятностью.
Свойство выборки отражать характеристики генеральной совокупности называется репрезентативностью. Различие между характеристиками генеральной и выборочной совокупностями называется ошибкой выборки, которая зависит от выбранной процедуры составления (формирования) выборки.
На третьем этапе определяется процедура составления выборки.
Процедура составления выборки -- это последовательность отбора респондентов в выборку. Отбор респондентов может сопровождаться систематическими и случайными ошибками. Систематические ошибки возникают при неправильно выбранной процедуре составления выборки. Случайные ошибки существуют всегда, поскольку связаны с влиянием сложно-предсказуемых факторов. Влияние случайности полностью устранить невозможно, но величину случайной ошибки можно определить с помощью статистических методов. Систематическую ошибку невозможно оценить, но можно устранить, изменив процедуру выборки.
Учитывая наличие двух типов ошибок при формировании выборки, выделяют случайные (вероятностные) и неслучайные (детерминированные) методы формирования выборки (рис. 2).

Рис. 2. Методы формирования выборки
Размер выборки влияет на точность результатов. Точность выборки характеризует близость профиля выборки (например, итогового ответа на какой-то вопрос) к истинному профилю совокупности. Методы определения размера выборки представлены в приложении Б.
При формировании выборки в маркетинговых исследованиях используются вероятностные (случайные) и детерминированные (неслучайные) методы. Характеристика, достоинства и недостатки методов формирования выборки даны в Приложении А.
К вероятностным методам относятся выборки, в которых предполагается, что каждый элемент генеральной совокупности известен и имеет определенную вероятность попасть в обследование. К сожалению, в большинстве маркетинговых исследований не представляется возможным точно рассчитать вероятности из-за отсутствия сведений о размере генеральной совокупности. Поэтому термин «определенная вероятность» скорее связан с правилами формирования выборки, чем со знанием точных размеров генеральной совокупности. Наиболее распространенными вероятностные методы построения выборки включают: простую случайную выборку, систематическую выборку, стратифицированную выборку, кластерную выборку.
Детерминированные (неслучайные) процедуры составления выборки самим процессом формирования предполагают неслучайный выбор респондентов, чье мнение может отличаться от мнения генеральной совокупности в целом, порождая тем самым наличие неслучайной (систематической) ошибки данных в результатах исследования. При использовании неслучайных процедур отбор респондентов в выборку производится на основе каких-либо принятых условий, ограничивающих круг вероятных участников исследования. Наиболее распространенные детерминированные методы построения выборки включают выборку по удобству, выборку по усмотрению, выборку методом квоты и выборку методом снежного кома.
Локализованная выборка (выборка по удобству), как и подразумевается в названии, стремится получить набор элементов на основании удобства для исследователя. Выбором единиц выборки занимается преимущественно интервьюер. Часто респонденты попадают в выборку потому, что они оказываются в нужное время в нужном месте.
Выборка по удобству имеет преимущества в том, что она является недорогой и быстрой. Кроме того, единицы такой выборки обычно доступны, легки для измерения и охотно сотрудничают с интервьюером. Несмотря на эти преимущества, у данного вида выбора есть серьезные ограничения. Главным ограничением является тот факт, что итоговая выборка не является представителем любой определимой целевой популяции. Этот процесс выборки характеризуется отклонением отбора. Это означает, что характеристики людей, включенных в выборку по удобству, могут систематически отличаться от характеристик целевой популяции. Из-за этих ограничений теоретически бессмысленно делать обобщение выборки по удобству на всю популяцию.
Выборки по удобству непригодны для описательных или причинных исследований, где целью служит получение выводов относительно популяции. Однако в предварительных исследованиях, целью которых является генерация идей, получение новых точек зрения или разработка гипотез, выборки по удобству могут оказаться полезными. Их можно использовать в целевых группах, при предварительном тестировании анкет или в пробных проектах. Но даже в этих случаях интерпретацию результатов следует проводить с осторожностью. Несмотря на эти ограничения, данный метод иногда используется даже в больших опросах.
Выборка на основе суждения (выборка по усмотрению) представляет собой такую форму выборки по удобству, при которой элементы популяции выбираются на основании мнения исследователя. Исследователь выбирает те или иные элементы выборки, т.к. он считает, что они представляют целевую популяцию.
Выборка по усмотрению является привлекательной из-за ее низкой стоимости, удобства и скорости. Однако она является субъективной, в значительной степени зависящей от опытаи творческих способностей исследователя. Поэтому нельзя делать обобщений для конкретной популяции обычно по причине того, что популяция четко не определена.
При выборке методом квот процесс выборки по усмотрению состоит из двух этапов. На первом этапе происходит разработка контрольных категорий, иначе квот, элементов популяции. Используя здравый смысл для определения релевантных категорий, таких как пол или раса, исследователь оценивает распределение этих характеристик в целевой популяции. Например, белые женщины возрастом от 18 до 35 могут рассматриваться как релевантная категория контроля для исследования спроса на косметические услуги. После этого исследователь, основываясь на своем опыте или источниках вторичной информации, проводит оценку доли целевой популяции, попадающей в эту категорию. После этого проводится формирование выборки для обеспечения гарантии того, что доля белых женщин возрастом от 18 до 35 лет из целевой популяции будет отражена в выборке. Квоты используются для обеспечения того, что состав выборки и состав популяции будут одинаковыми в отношении характеристик, представляющих интерес.
Как только определены квоты, начинается второй этап процесса формирования выборки. Элементы выбираются по удобству или по усмотрению. Присутствует значительная свобода при выборе элементов, которые включаются в выборку. Единственным требованием является то, чтобы выбранные элементы соответствовали контрольным характеристикам.
Однако с этим методом выборки связано множество потенциальных проблем. В процессе установки квот можно не придать значения важным характеристикам, а это ведет к тому, что с точки зрения релевантных контрольных характеристик выборка не будет являться достаточно хорошим представлением популяции. Так как в каждой квоте элементы выбираются по удобству или усмотрению, возможно присутствие множества источников отклонений отбора. У интервьюеров может появиться искушение выбирать такие районы, в которых, по их мнению, они смогут добиться успеха в опросе участников, могут избегать людей, которые выглядят неприветливо, плохо одеты или живут в нежелательных районах. Еще одним ограничением выборки методом квот является тот факт, что для нее нельзя выполнить оценку ошибки выборки.
Применение выборок, сформированных методом квот, продиктовано стремлением к тому, чтобы сравнительно дешево получить репрезентативные выборки. Кроме того, такие выборки достаточно удобно составлять. Если выбраны подходящие контрольные характеристики, с помощью выборки методом квот можно получить результаты, близкие к тем, которые получаются при традиционной вероятностной выборке.
При выборке методом снежного кома выбирается первоначальная группа респондентов, обычно случайным образом. Этих респондентов, после того, как они опрошены, просят указать, кто еще принадлежит к целевой популяции, представляющей интерес. Этот процесс продолжается, что ведет к эффекту снежного кома, т.к. одна ссылка исходит из другой. Таким образом, в результате этого процесса формируется структура выборки, из которой отбираются респонденты. Несмотря на то, что в этом методе выборки сначала используется вероятностная выборка, в результате получается невероятностная выборка. Это происходит потому, что указанные респонденты по демографическим и психографическим характеристикам будут скорее похожи на респондентов, которые указали на них.
Выборка методом снежного кома используется при изучении характеристик, которые для данной популяции являются сравнительно редкими или трудными для выявления. Без такого рода ссылок может вообще быть невозможным выявление групп со специальными характеристиками, таких как мужчины-вдовцы моложе 35 лет или отдельные популяции-меньшинства.
Главное преимущество выборки методом снежного кома заключается в том, что она значительно увеличивает вероятность обнаружения требуемых свойств среди популяции. Она характеризуется сравнительно низкой стоимостью и величиной отклонений в выборке.
В простой случайной выборке каждому элементу популяции соответствует заданная и одинаковая вероятность отбора. Более того, любая возможная выборка заданного размера (n) имеет заданную и одинаковую вероятность стать действительной выборкой. Суть процедуры формирования случайной выборки лежит в том, что каждый элемент отбирается независимо от всех остальных элементов.
В телефонных опросах для генерации случайной выборки телефонных номеров часто используется метод дозвона на случайный номер. Этот метод заключается в случайном выборе всех 10 цифр телефонного номера (код города, основной и добавочный номера). Хотя такой подход дает всем семействам, имеющим телефон, примерно одинаковые шансы попасть в выборку, однако не все числа, сгенерированные таким образом, являются действительными телефонными номерами. Для того чтобы выявить и устранить недействительные номера, было предложено несколько модификаций этого метода. С их использованием применение простой случайной выборки в телефонных опросах становится более привлекательным.
У метода простой случайной выборки есть множество преимуществ. Он прост для понимания и направлен на то, чтобы получить данные, являющиеся репрезентативными для целевой популяции. Большинство подходов, связанных со статистическими выводами, предполагают, что использовалась случайная выборка. Тем не менее, у метода простой случайной выборки есть, как минимум, четыре существенных ограничения:
· 1) Построение структуры выборки с использованием этого метода является сложной задачей.
· 2) Этот метод может оказаться дорогостоящим и занимать много времени, т.к. структура выборки географически может быть распределена по большой территории.
· 3) Метод простой случайной выборки часто дает низкую точность.
· 4) Выборки, сгенерированные с помощью этого метода, могут не быть репрезентативными выборками целевой популяции, особенно если размер выборки мал.
Хотя сформированные выборки неплохо представляют популяцию в целом, отдельная простая случайная выборка может значительно отличаться от целевой популяции. По этим причинам метод простой случайной выборки не используется широко в маркетинговых исследованиях. Более популярны такие процедуры, как систематическая выборка.
Метод систематической выборки включается в том, что выборка формируется путем выбора случайным образом начальной точки и затем последовательного отбора каждого i -го элемента схемы выборки. Частота отбора элементов i называется интервалом выборки. Он вычисляется путем деления размера популяции N на размер выборки n и округления полученного значения до ближайшего целого. Например, допустим, что популяция состоит из 100 000 элементов, и желательно, чтобы выборка состояла из 1000 элементов. В этом случае интервал выборки i равен 100. Выбирается случайное число между 1 и 100. Если, например, оно равно 23, то выборка будет состоять из элементов 23, 123, 223, 323, 423, 523 и т.д.
Элементы популяции, используемые при систематической выборке, обычно определенным способом организованы. Если в качестве схемы выборки используется телефонная книга, элементы организуются в алфавитном порядке. В некоторых случаях порядок следования элементов может быть связан с некоторой характеристикой, представляющей интерес для исследователя. Например, потребители кредитных карточек могут быть перечислены в порядке величины суммы задолженности, а фирмы некоторой отрасли могут быть расположены в порядке, соответствующем годовому объему продаж. Когда элементы популяции организованы некоторым образом, который связан с изучаемыми характеристиками, систематическая выборка может дать результаты, совершенно отличающиеся от метода простой случайной выборки.
С другой стороны, когда структуры выборки организованы циклическим путем, систематические выборки становятся менее репрезентативными. Чтобы продемонстрировать это на практике, рассмотрим пример применения метода систематической выборки для генерации выборки, состоящей из показателей объема реализации услуг за месяц в салоне красоты. Выборка формируется на основе структуры выборки, содержащей показатели месячного объема реализации услуг за последние 7 лет. Если установить интервал выборки равным 12, итоговая выборка не отразит зависимость уровня реализации услуг от месяца.
Систематическая выборка менее дорогостояща и более проста, чем простая случайная выборка, потому что здесь случайный выбор происходит только один раз. Кроме того, систематическую выборку можно применить, не имея знаний о структуре схемы выборки. По этим причинам систематическая выборка часто применяется в почтовых, телефонных опросах и собеседованиях.
Стратифицированная выборка представляет собой процесс выборки, состоящий из двух этапов и производящий скорее вероятностную выборку, чем выборку по удобству или по усмотрению. Во-первых, популяция делится на подгруппы, называемые стратами. Каждый элемент популяции должен быть отнесен к одной и только одной страте, и ни один из элементов популяции не должен быть пропущен. Во-вторых, элементы из каждой страты должны быть отобраны случайным образом. Идеальным вариантом является использование метода простой случайной выборки для отбора элементов в каждой страте. Тем не менее, на практике может использоваться метод систематической выборки и другие вероятностные процедуры построения выборки.
Главной целью метода стратифицированной выборки является повышение точности без увеличения стоимости. Разделение популяции происходит с использованием стратификационных переменных. Страты формируются исходя из четырех критериев: однородность, разнородность, связанность, стоимость. Следует соблюдать следующие указания:
· – Элементы в пределах страты должны быть похожими или однородными.
· – Элементы, находящиеся в разных стратах, должны отличаться, т.е. быть разнородными.
· – Стратификационные переменные должны быть связаны с интересующей характеристикой.
· – Количество страт обычно варьируется между двумя и шестью. Когда число страт превышает шесть, всякое дальнейшее повышение точности происходит за счет очень высокой стоимости.
У метода стратификации есть два преимущества. Когда исследование проводится с учетом перечисленных выше указаний, колебания в выборке уменьшаются. Стоимость выборки также можно уменьшить, если стратификационные переменные выбираются так, чтобы их было легко измерить и применить. Для стратификации обычно используются такие переменные, как демографические характеристики, тип потребителя (кредитная карточка или другой вид оплаты), размер фирмы. Стратифицированная выборка повышает точность метода генерации простой случайной выборки.
При кластерной выборке целевую популяцию сначала делят на взаимно исключающие и совокупно исчерпывающие субпопуляции, по-другому - кластеры. Затем с помощью вероятностного метода выборки, такого как простая случайная выборка, формируется произвольная выборка из кластеров. В каждом отдельном кластере включаются либо все элементы, либо выборка элементов, сформированная вероятностным методом. Если в выборку включаются все элементы каждого отобранного кластера, такая процедура называется одноэтапной кластерной выборкой. Если же выборка элементов формируется вероятностным путем из каждого отобранного кластера, такая процедура называется двухэтапной кластерной выборкой.
Существует множество ключевых отличий между кластерной и стратифицированной выборкой. Они приведены в следующей таблице 1.
Таблица 1
Ключевые отличия между кластерной и стратифицированной выборкой
| Кластерная выборка | Стратифицированная выборка |
| Выборка формируется только из некоторых субпопуляций (кластеров) | Выборка формируется из всех субпопуляций (страт) |
| В пределах кластера элементы должны отличаться (быть разнородными), тогда как поддерживается однородность или схожесть между различными кластерами | В пределах страты элементы должны быть однородными, а между стратами должны быть различия (разнородность) |
| Схема выборки нужна только для кластеров, попавших в выборку | Должна быть сформирована полная схема выборки для всех стратифицированных субпопуляций |
| Повышает эффективность выборки, уменьшая стоимость | Повышает точность |
Одной из наиболее распространенных форм кластерной выборки является пространственная выборка. Пространственная выборка основана на кластеризации по географическим областям, таким как округа, жилые участки и кварталы. Выборка может быть получена за один или несколько этапов. При одноэтапной площадной выборке происходит выборка всех элементов из данного кластера. Например, если за кластеры принимаются городские кварталы, тогда все семьи в отобранных кварталах должны быть включены в выборку. В случае двухэтапной выборки только часть семей, проживающих в каждом квартале, попадет в выборку.
Кластерная выборка имеет два основных преимущества: легкая осуществимость и низкая стоимость. Так как структуры выборки часто составляются на основании кластеров, а не элементов популяции, кластерная выборка может быть единственно возможным подходом. Принимая во внимание ограниченность ресурсов проекта исследования, составление списка всех элементов популяции может быть очень дорогостоящей, или даже неосуществимой задачей. Однако списки географических районов, телефонных узлов и прочих кластеров (скоплений) потребителей можно составить сравнительно легко. Кластерная выборка является самым экономически эффективным методом выборки. Это преимущество следует рассматривать, принимая во внимание то, что существуют и некоторые ограничения. При кластерном методе построения получаются некачественные выборки, в которых трудно сформировать отличающиеся, разнородные кластеры. Например, семьи, проживающие в одном квартале, скорее будут похожими, чем непохожими. Вычисление и интерпретация статистики на основании кластеров может быть сложной задачей.
Выбор между невероятностным и вероятностным методом построения выборки следует делать, принимая во внимание такие факторы, как природа исследования, ошибка, вносимая в процессе выборки, изменчивость популяции, статистические и оперативные факторы. Например, в познавательных исследованиях получаемые сведения рассматриваются как предварительные, и тогда применение вероятностной выборки может быть неоправданным. С другой стороны, в итоговых исследованиях, в которых исследователь хочет обобщить результаты на всю целевую популяцию предпочтительно использование вероятностной выборки. Вероятностные выборки делают возможным статистическое распространение результатов на целевую популяцию.
Когда требуется высокая степень точности, как в случае получения оценок характеристик популяции, желательно использовать вероятностную выборку. В таких ситуациях исследователю нужно устранить отклонения отбора и вычислить влияние ошибки выборки. Для этого требуется использование вероятностной выборки. Однако даже при такой повышенной точности метода формирования вероятностная выборка не всегда даст более точные результаты. Например, с помощью вероятностной выборки невозможно контролировать ошибки, не связанные с выборкой. Если ошибки именно такого рода будут представлять главную проблему, то невероятностные методы выборки, такие как выборка по усмотрению, могут оказаться более предпочтительными, т.к. они дают повышенный уровень контроля над процессом выборки.
При выборе между методами формирования выборки исследователь должен также принять во внимание похожесть или однородность популяции в характеристиках, представляющих интерес. Например, вероятностная выборка лучше подходит для популяций с высокой степенью разнородности, для которых формирование репрезентативной выборки имеет исключительно большое значение. Вероятностная выборка более предпочтительна и с точки зрения статистики, т.к. на ее основе можно применять все наиболее распространенные статистические методы.
Хотя вероятностный метод формирования выборки имеет множество преимуществ, он сложен и требует от исследователей отличного знания статистики. Обычно построение вероятностной выборки дороже и для нее необходимо больше времени, чем для невероятностной. Во многих проектах маркетинговых исследований очень сложно найти оправдание дополнительным затратам финансов и времени. Поэтому на практике использование того или иного метода выборки диктуется целями исследования.

