2020-05-25
2020-05-25 144
144Практическая работа № 12.
Интеллектуальные системы и технологии: использование аналитической информационной системы Deductor Academic в оценке кредитоспособности заемщика
Цель:сформировать знания о сущности методики Data Mining, изучить процесс построения модели оценки потенциальных заемщиков на базе на основе аналитической платформы Deductor Academic.
Время: 2 часа.
План :
1. Сущность методики Data Mining
2. Правила оформления и представления отчета по практической работе.
3. Построение модели оценки (классификации) потенциальных заемщиков на основе аналитической платформы Deductor Academic.
Ход работы
Сущность методики Data Mining
Развитие экономики неразрывно связано с процессом кредитования, который в различных формах проникает во все сферы хозяйственной жизни. Об этом свидетельствует расширение круга операций банков в области кредитования. Активная работа коммерческих банков в области кредитования является непременным условием успешной конкуренции этих учреждений, ведет к росту производства, увеличению занятости населения, повышению платежеспособности участников экономических отношений.
Риски присущи всем сферам банковской деятельности, но большинство рисков связано с активными операциями банка, в первую очередь с кредитной и инвестиционной деятельностью. Кредитные операции банка являются ведущими среди прочих как по прибыльности, так и по масштабности размещения средств. В связи с этим повышение эффективности кредитной политики и снижение кредитных рисков являются очень актуальными.
Большое значение имеет автоматизация процессов расчета оценки кредитоспособности заемщика. Система поддержки принятия решений в кредитовании позволит проводить более точный и глубокий анализ кредитоспособности заемщика, снизит кредитные риски банка, ускорит и повысит качество принимаемых решений банковскими работниками.
Задачи подобного рода эффективно решаются на базе аналитической платформы Deductor Academic (фирмы BaseGroup Labs). Механизмы Deductor позволяют как создать консолидированное хранилище информации о заемщиках, обеспечивая к тому же и непротиворечивость хранимой информации, так и формализовать знания экспертов, создав модели классификации заемщиков с достоверностью более 90%. Причем модель позволяет принять решение о выдаче кредита или отказе практически мгновенно.
Основные возможности Deductor Academic:
Ø Обеспечение централизованного хранения данных, их непротиворечивости, а также обеспечение всей необходимой поддержки процесса анализа данных, оптимизированного доступа.
Ø Обеспечение возможности выбора экспертом наиболее подходящего метода на каждом шаге обработки информации. Это позволяет наиболее точно формализовать его знания в данной предметной области.
Ø Обеспечение возможности сотрудникам, не разбирающимся в методиках анализа и способах получения того или иного результата, получать ответ на основе моделей, подготовленных экспертом. Так сотрудник, оформляющий кредиты, должен ввести данные по потребителю и система автоматически выдаст решение об отказе или о выдаче кредита.
Ø Выдача решения по списку потенциальных заемщиков. Из хранилища автоматически выбираются данные по лицам, заполнившим анкету вчера (или за какой угодно буферный период), эти данные прогоняются через построенную модель, а результат экспортируется в виде отчета, либо экспортируется в систему автоматического формирования договоров кредитования или писем с отказом в предоставлении кредита. Это позволяет сэкономить время и деньги.
Ø Обеспечение возможности эксперту оценить адекватность текущей модели и, в случае каких либо нежелательных отклонений, перестроить ее, используя новые данные.
Ø Автоматизация всей последовательности действий от получения заявки на кредит до принятия решения об его выдаче и формирование необходимого пакета документов.
Сущность методики:
Большинство кредитных учреждений обладают слабо развитыми средствами анализа и классификации. В основном для оценки потенциального заемщика используется мнение эксперта в комбинации с бальными системами оценки. Эти методы слишком инертны, чтобы реагировать на динамику рынка.
Для увеличения прибыли необходимы более эффективные инструменты анализа, например, основанные на технологиях Data Mining.
Data Mining («добыча данных») – это общий термин для обозначения анализа данных с активным использованием математических методов и алгоритмов, таких как методы оптимизации, генетические алгоритмы, распознавание образов.
Data Mining – это процесс обнаружения в заранее необработанных данных ранее неизвестных практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Задачи, решаемые методами Data Mining:
Ø Классификация – это отнесение объектов (наблюдений, событий) к одному из заранее известных классов.
Ø Регрессия, в том числе задачи прогнозирования. Установление зависимости непрерывных выходных от входных переменных.
Ø Кластеризация – это группировка объектов (наблюдений, событий) на основе данных (свойств), описывающих сущность этих объектов.
Ø Ассоциация – выявление закономерностей между связанными событиями.
Ø Последовательные шаблоны – установление закономерностей между связанными во времени событиями, т.е. обнаружение зависимости, что если произойдет событие X, то спустя заданное время произойдет событие Y.
Ø Анализ отклонений – выявление наиболее нехарактерных шаблонов.
Для расчета рейтинга заемщика и управления кредитными рисками наибольшее распространение получил метод логистической регрессии.
Логистическая регрессия – это разновидность множественной регрессии, общее назначение которой состоит в анализе связи между несколькими независимыми переменными (называемыми также регрессорами или предикторами) и зависимой переменной. Бинарная логистическая регрессия, как следует из названия, применяется в случае, когда зависимая переменная является бинарной (т.е. может принимать только два значения). Иными словами, с помощью логистической регрессии можно оценивать вероятность того, что событие наступит для конкретного испытуемого (возврат кредита/дефолт и т.д.).
Следует отметить, что возможности по моделированию нелинейных зависимостей у логистической регрессии отсутствуют. Однако для оценки качества модели логистической регрессии существует эффективный инструмент ROC-анализа, что является несомненным ее преимуществом.
ROC-кривая (Receiver Operator Characteristic) – кривая, которая наиболее часто используется для представления результатов бинарной классификации в машинном обучении. Название пришло из систем обработки сигналов. Поскольку классов два, один из них называется классом с положительными исходами, второй – с отрицательными исходами. ROC-кривая показывает зависимость количества верно классифицированных положительных примеров от количества неверно классифицированных отрицательных примеров. В терминологии ROC-анализа первые называются истинно положительным, вторые – ложно отрицательным множеством. При этом предполагается, что у классификатора имеется некоторый параметр, варьируя который, мы будем получать то или иное разбиение на два класса. Этот параметр часто называют порогом, или точкой отсечения (cut-off value). В зависимости от него будут получаться различные величины ошибок I и II рода.
В логистической регрессии порог отсечения изменяется от 0 до 1 – это и есть расчетное значение уравнения регрессии. Будем называть его рейтингом.
Для понимания сути ошибок I и II рода рассмотрим четырехпольную таблицу 1 сопряженности (confusion matrix), которая строится на основе результатов классификации моделью и фактической (объективной) принадлежностью примеров к классам.
Таблица 1 - Сопряженность
| Модель | Фактически | |
| положительно | отрицательно | |
| положительно | TP | FP |
| отрицательно | FN | TN |
· TP (True Positives) – верно классифицированные положительные примеры (так называемые истинно положительные случаи);
· TN (True Negatives) – верно классифицированные отрицательные примеры (истинно отрицательные случаи);
· FN (False Negatives) – положительные примеры, классифицированные как отрицательные (ошибка I рода). Это так называемый "ложный пропуск" – когда интересующее нас событие ошибочно не обнаруживается (ложно отрицательные примеры);
· FP (False Positives) – отрицательные примеры, классифицированные как положительные (ошибка II рода). Это ложное обнаружение, т.к. при отсутствии события ошибочно выносится решение о его присутствии (ложно положительные случаи).
Что является положительным событием, а что – отрицательным, зависит от конкретной задачи. Например, если мы прогнозируем вероятность невозврата кредита, то положительным исходом будет класс «Не вернувшие кредит», отрицательным – «Вернувшие кредит». И наоборот, если мы ходим определить вероятность возврата кредита, то положительным исходом будет класс «Вернувшие кредит».
При анализе чаще оперируют не абсолютными показателями, а относительными – долями (rates), выраженными в процентах:
Доля истинно положительных примеров (True Positives Rate):

Доля ложно положительных примеров (False Positives Rate):
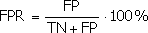
Введем еще два определения: чувствительность и специфичность модели. Ими определяется объективная ценность любого бинарного классификатора.
Чувствительность (Sensitivity) – это и есть доля истинно положительных случаев:
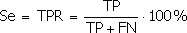
Специфичность (Specificity) – доля истинно отрицательных случаев, которые были правильно идентифицированы моделью:
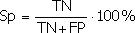
Заметим, что FPR=100-Sp.
Модель с высокой чувствительностью часто дает истинный результат при наличии положительного исхода (обнаруживает положительные примеры). Наоборот, модель с высокой специфичностью чаще дает истинный результат при наличии отрицательного исхода (обнаруживает отрицательные примеры).
Своеобразным методом сравнения ROC-кривых является оценка площади под кривыми. Теоретически она изменяется от 0 до 1.0, но, поскольку модель всегда характеризуется кривой, расположенной выше положительной диагонали, то обычно говорят об изменениях от 0.5 («бесполезный» классификатор) до 1.0 («идеальная» модель). Эта оценка может быть получена непосредственно вычислением площади под многогранником, ограниченным справа и снизу осями координат и слева вверху – экспериментально полученными точками (рис.1). Численный показатель площади под кривой называется AUC (Area Under Curve). Вычислить его можно, например, с помощью численного метода трапеций:

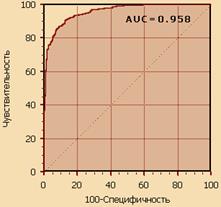
Рисунок 1 – Площадь под ROC-кривой
С большими допущениями можно считать, что чем больше показатель AUC, тем лучшей прогностической силой обладает модель. Однако следует знать, что:
· показатель AUC предназначен скорее для сравнительного анализа нескольких моделей;
· AUC не содержит никакой информации о чувствительности и специфичности модели.
О качестве модели можно судить по экспертной шкале для значений AUC (см. таблицу 1)
Таблица 1 – Шкала оценки качества модели
| Интервал AUC | Качество модели |
| 0.9-1.0 | Отличное |
| 0.8-0.9 | Очень хорошее |
| 0.7-0.8 | Хорошее |
| 0.6-0.7 | Среднее |
| 0.5-0.6 | Неудовлетворительное |
Идеальная модель обладает 100% чувствительностью и специфичностью. Однако на практике добиться этого невозможно, более того, невозможно одновременно повысить и чувствительность, и специфичность модели. Компромисс находится с помощью порога отсечения, т.к. пороговое значение влияет на соотношение Se и Sp. Можно говорить о задаче нахождения оптимального порога отсечения (optimal cut-off value).
Порог отсечения нужен для того, чтобы применять модель на практике: относить новые примеры к одному из двух классов. Для определения оптимального порога нужно задать критерий его определения, т.к. в разных задачах присутствует своя оптимальная стратегия. Критериями выбора порога отсечения могут выступать:
Ø Требование минимальной величины чувствительности (специфичности) модели. Например, нужно обеспечить чувствительность теста не менее 80%. В этом случае оптимальным порогом будет максимальная специфичность (чувствительность), которая достигается при 80% (или значение, близкое к нему "справа" из-за дискретности ряда) чувствительности (специфичности).
Ø Требование максимальной суммарной чувствительности и специфичности модели.
Ø Требование баланса между чувствительностью и специфичностью.
Существуют и другие подходы, когда ошибкам I и II рода назначается вес, который интерпретируется как цена ошибок. Но здесь встает проблема определения этих весов, что само по себе является сложной, а часто не разрешимой задачей.