2020-07-12
2020-07-12 419
419Корреляционный и регрессионный анализ
ДЛЯ РАБОТЫ СО СТАТИСТИЧЕСКИМИ ДАННЫМИ можно воспользоваться в Microsoft Excel встроенным Пакетом анализа. Если этот пункт в данном меню Сервис отсутствует, необходимо его включить, используя пункт меню Надстройки (рис. 6):
|

Рис. 6
Поставьте флажок в Надстройках в строке Пакет анализа (рис. 7), нажмите клавишу ОК.

Рис. 7
После этого шага в меню Сервис появится строка Анализ данных (рис. 8).

Рис. 8
После активизации Анализ данных, выберите модуль Описательная статистика (рис. 9) нажмите кнопку ОК.

Рис. 9
После этого появится диалоговое окно Описательная статистика, в котором нужно определить Входной интервал, поставить флажок Метки в первой строке, если вместе с входными данными были выделены заголовки, задать параметры вывода (рис. 10).
В параметрах вывода по умолчанию указано, что результаты будут размещаться на Новом рабочем листе. Поставьте флажок в строке Итоговая статистика. Затем, нажмите кнопку ОК.

Рис. 10
Рассмотрим более подробно элементы Диалогового окна Описательная статистика и операции в этом окне. Окно содержит (рис. 10):
1) Входной диапазон. Ссылка на диапазон, содержащий анализируемые данные. Ссылка должна состоять не менее чем из двух смежных диапазонов данных, данные в которых расположены по строкам или столбцам.
2) Группирование. Установите переключатель в положение По столбцам или По строкам в зависимости от расположения данных во входном диапазоне.
3) Метки в первой строке/Метки в первом столбце. Если первая строка исходного диапазона содержит названия столбцов, установите переключатель в положение Метки в первой строке. Если названия строк находятся в первом столбце входного диапазона, установите переключатель в положение Метки в первом столбце. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически.
4) Уровень надежности. Установите флажок, если в выходную таблицу необходимо включить строку для уровня надежности. В поле введите требуемое значение. Например, значение 95% вычисляет уровень надежности среднего со значимостью 0.05.
5) К-ый наибольший. Установите флажок, если в выходную таблицу необходимо включить строку для k-го наибольшего значения для каждого диапазона данных. В соответствующем окне введите число k. Если k равно 1, эта строка будет содержать максимум из набора данных.
6) К-ый наименьший. Установите флажок, если в выходную таблицу необходимо включить строку для k-го наименьшего значения для каждого диапазона данных. В соответствующем окне введите число k. Если k равно 1, эта строка будет содержать минимум из набора данных.
7) Выходной диапазон. Введите ссылку на левую верхнюю ячейку выходного диапазона. Этот инструмент анализа выводит два столбца сведений для каждого набора данных. Левый столбец содержит метки статистических данных; правый столбец содержит статистические данные. Состоящий их двух столбцов диапазон статистических данных будет выведен для каждого столбца или для каждой строки входного диапазона в зависимости от положения переключателя Группирование.
8) Новый лист. Установите переключатель, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A 1. Если в этом есть необходимость, введите имя нового листа в поле, расположенном напротив соответствующего положения переключателя.
9) Новая книга. Установите переключатель, чтобы открыть новую книгу и вставить результаты анализа в ячейку A 1 на первом листе в этой книге.
10) Итоговая статистика. Установите флажок, если в выходном диапазоне необходимо получить по одному полю для каждого из следующих видов статистических данных: Среднее, Стандартная ошибка (среднего), Медиана, Мода, Стандартное отклонение, Дисперсия выборки, Эксцесс, Асимметричность, Интервал, Минимум, Максимум, Сумма, Счет, Наибольшее (#), Наименьшее (#), Уровень надежности.
В результате Вы получите статистические показатели, такие, как среднее, дисперсия, среднее квадратичное отклонение и т.д. (рис. 11).

Рис. 11
ОПРЕДЕЛЕНИЯ ОПИСАТЕЛЬНЫХ СТАТИСТИК
Рассмотрим определения описательных статистик для их дальнейшего использования. Наряду со средними величинами в качестве описательных характеристик выборочных данных применяют моду и медиану.
Медианой называют значение признака, приходящееся на середину ранжированного ряда наблюдений.
Модой называют такое значение признака, которое наблюдалось наибольшее число раз.
Средние величины, характеризующие ряд числом, не отражают изменчивости наблюдавшихся значений признака, т.е. вариацию. Простейший показатель вариации – вариационных размах, равный разности между наибольшим и наименьшим значениями в ряду. Вариационный размах – приближенный показатель вариации, так как не зависит от изменения вариантов, а крайние варианты, которые используются для его вычисления, как правило, ненадежны. Более правильно использовать меру рассеяния наблюдений вокруг средних величин: это выборочные дисперсия и среднеквадратическое отклонение.
Выборочная дисперсия находится по формуле:
 ,
,
а выборочное среднее квадратическое отклонение равно арифметическому значению корня квадратного из дисперсии и имеет ту же размерность, что и значение признака.
Выборочным коэффициентом ассиметрии называют отношение центрального момента третьего порядка к кубу среднеквадратического отклонения. Если в выборочном ряду преобладают варианты меньше 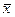 , то выборочный коэффициент ассиметрии отрицателен, в этом случае имеет место левосторонняя ассиметрия.
, то выборочный коэффициент ассиметрии отрицателен, в этом случае имеет место левосторонняя ассиметрия.
Если преобладают варианты, большие , то выборочный коэффициент ассиметрии положителен, в этом случае имеет место правосторонняя ассиметрия. Выборочный коэффициент ассиметрии не имеет верхней или нижней границы, что снижает его ценность как меры ассиметрии. Практически коэффициент ассиметрии редко бывает особенно велик, а для умеренно ассиметричных рядов он обычно меньше 1.
Выборочный эксцесс – это уменьшенное на 3 единицы отношение центрального момента четвертого порядка к четвертой степени среднеквадратического отклонения. За стандартное значение эксцесса принимают нуль-эксцесс нормальной кривой. Кривые, у которых эксцесс отрицателен по сравнению с нормальной кривой, менее крутые, имеют более плоскую вершину и называются плосковершинными.
Рассмотрим отличие функции распределения данного ряда наблюдений от нормального распределения.
1. Коэффициенты ассиметрии и эксцесса для нормального распределения равны 0. Коэффициент ассиметрии характеризует скошенность распределения по отношению к математическому ожиданию.
2. Наряду со средним значением в качестве показателя центра группирования используется медиана. Для нормального распределения медиана и среднее совпадают.
3. Для нормального распределения мода и среднее должны совпадать.
Д ЛЯ ПОСТРОЕНИЯ ПОЛЯ КОРРЕЛЯЦИИ можно воспользоваться мастером ДИАГРАММ.
Сначала выделите курсором исходные данные, для которых будете строить Поле корреляции (рис. 12).
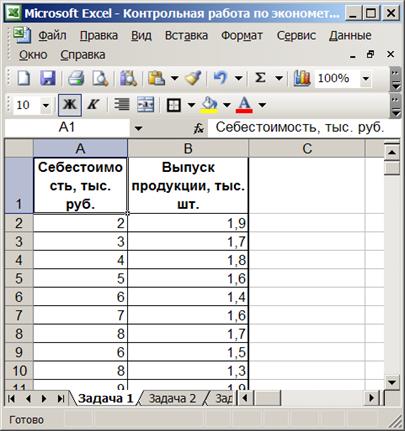
Рис. 12
Затем, выберите: ВСТАВКА Диаграмма или на панели инструментов воспользуйтесь значком Мастер диаграмм После этого появится диалоговое окно Мастер диаграмм (Шаг 1 из 4) (рис. 13). Выберите Точечную Диаграмму и нажмите Далее.

Рис. 13
Если перед вызовом Мастера диаграмм Вы выделили Диапазон исходных данных, для которого хотите построить диаграмму, то в следующем диалоговом окне Мастер диаграмм (Шаг 2 из 4) Вы увидите Поле корреляции для выделенных исходных данных (рис. 14). На рис. 12 выделенные ряды исходных данных Себестоимость и Выпуск продукции.
Если исходные данные не были выделены перед началом работы Мастера диаграмм, то в следующем диалоговом окне Мастер диаграмм (Шаг 2 из 4) в пунктах меню Диапазон данных или Ряды, можно задать исходные данные. Если исходные данные располагаются в смежных столбцах, то следует воспользоваться пунктом меню Диапазон данных.
Если данные для построения графика находятся не в смежных столбцах, то выберите Меню Ряды и, установив курсор сначала в окно Значения Х, выделите курсором мыши на рабочем листе соответствующие значения X, а затем, установив курсор в окно Значения Y, выделите на рабочем листе соответствующие значения Y (рис. 14).

Рис. 14
После чего, нажмите кнопку Далее. Появится диалоговое окно Мастер диаграмм (шаг 3 из 4). В этом окне можно задать Параметры диаграммы, например,подписи данных, названия для осей координат и т.д.
Послешага 2 можно сразу перейти на шаг 4, выполнив команду Готово. В этом случае Вы сразу перейдете в диалоговое окно Мастер диаграмм (шаг 4 из 4). В этом окне выберите месторасположение Поля корреляции: на листе, где находятся исходные данные (текущем), или на новом. После выполнения команды Готово на заданном листе будет нарисована диаграмма рассеяния переменных (Поле корреляции) (рис. 15).

Рис. 15
В ЕXCEL ПАРНЫЕ КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ МОЖНО ВЫЧИСЛИТЬ с помощью встроенных статистических функций КОРРЕЛ и ПИРСОН.
Для этого надо выбрать:
ВСТАВКА
 Функции
Функции
Статистические
КОРРЕЛ
или ПИРСОН
отметив в качестве массивов 1 и 2 столбцы интересующих переменных.
Расчет матрицы выборочных парных коэффициентов корреляции осуществляется с помощью Пакета анализа. Выбираем в меню Сервис — Анализ данных — Корреляция.

Рис. 16
Диалоговое окно «Корреляция» (рис. 16) содержит:
Входной диапазон. Необходимо указать массив исходных показателей (выделив мышкой все значения исследуемых переменных)
Группирование. В зависимости от расположения данных (в нашем случае по столбцам), необходимо установить переключатель в положение По столбцам или По строкам.
Метки в первой строке/Метки в первом столбце. Если первая строка исходного диапазона данных содержит названия столбцов, установите переключатель. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически.
Выходной интервал. Можно указать ссылку на левую верхнюю ячейку выходного диапазона.
Новый лист. Если в этом есть необходимость, то можно установить переключатель, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейка А1.
Рассмотрим пример, в котором исследуется линейная зависимость между переменными Y, X 1, X 2, X 3 (рис. 17).

Рис. 17
После нажатия на кнопку «ОК» на новом рабочем листе появится корреляционная матрица (рис. 18).

Рис. 18
Эту матрицу можно записать в виде:
|
| Y | X1 | X2 | X3 |
| Y | 1 |
|
|
|
| X1 | 0,46250 | 1 |
|
|
| X2 | 0,00715 | 0,12434 | 1 |
|
| X3 | 0,56890 | -0,01972 | -0,03078 | 1 |

Если в настройке корреляционного анализа не был поставлен флажок в Метки в первой строке, то матрица будет выведена без названий переменных, и их необходимо ввести вместо номеров столбцов:
|
| Столбец 1 | Столбец 2 | Столбец 3 | Столбец 4 |
| Столбец 1 | 1 |
|
|
|
| Столбец 2 | 0,46250 | 1 |
|
|
| Столбец 3 | 0,00715 | 0,12434 | 1 |
|
| Столбец 4 | 0,56890 | -0,01972 | -0,03078 | 1 |
Для построения регрессионной зависимости между переменными воспользуйтесь модулем «Регрессия».

Рис. 19
После активизации Регрессии в окне Анализ данных появится соответствующее диалоговое окно Регрессия, в котором нужно задать Входные данные, Метки, Параметры вывода и Остатки (рис. 20).
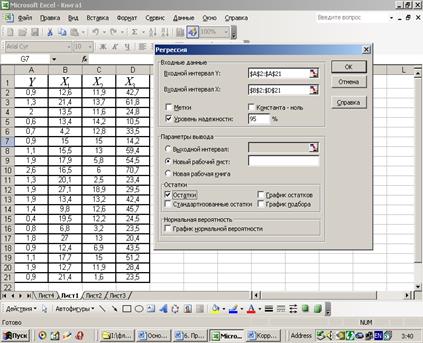
Рис. 20
Элементы диалогового окна Регрессия содержат (рис. 21):
1) Входной интервал Y. Введите ссылку на диапазон анализируемых зависимых данных. Диапазон должен состоять из одного столбца.
2) Входной интервал X. Введите ссылку на диапазон независимых данных, подлежащих анализу. Microsoft Excel располагает независимые переменные этого диапазона слева направо в порядке возрастания. Максимальное число входных диапазонов равно 16.
3) Заголовки. Установите флажок, если первая строка или первый столбец входного интервала содержит заголовки. Снимите флажок, если заголовки отсутствуют; в этом случае подходящие названия для данных выходного диапазона будут созданы автоматически.
4) Уровень надежности. Установите флажок, чтобы включить в выходной диапазон дополнительный уровень. В соответствующее поле введите уровень надежности, который будет использован дополнительно к уровню 95%, применяемому по умолчанию.
5) Константа – ноль. Установите флажок, чтобы линия регрессии прошла через начало координат.

Рис. 21
6) Выходной диапазон. Введите ссылку на левую верхнюю ячейку выходного диапазона. Отведите, по крайней мере, семь столбцов для итогового диапазона, который будет включать в себя: результаты дисперсионного анализа, коэффициенты регрессии, стандартную погрешность вычисления Y, среднеквадратичные отклонения, число наблюдений, стандартные погрешности для коэффициентов.
7) Новый лист. Установите переключатель, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. Если в этом есть необходимость, введите имя нового листа в поле, расположенном напротив соответствующего положения переключателя.
8) Новая книга. Установите переключатель, чтобы открыть новую книгу и вставить результаты анализа в ячейку A1 на первом листе в этой книге.
9) Остатки. Установите флажок, чтобы включить остатки в выходной диапазон.
10) Стандартизированные остатки. Установите флажок, чтобы включить стандартизированные остатки в выходной диапазон.
11) График остатков. Установите флажок, чтобы построить диаграмму остатков для каждой независимой переменной.
12) График подбора. Установите флажок, чтобы построить диаграммы наблюдаемых и предсказанных значений для каждой независимой переменной.
13) График нормальной вероятности. Установите флажок, чтобы построить диаграмму нормальной вероятности.
В результате Вы получите следующее решение:
| ВЫВОД ИТОГОВ |
| ||
| Регрессионная статистика | |||
| Множественный R | 0,49 |
| |
| R-квадрат | 0,24 | Коэффициент детерминации | |
| Нормированный R-квадрат | 0,10 |
|
|
| Стандартная ошибка | 0,55 | Среднеквадратичное отклонение = корень из оценки дисперсии модели | |
| Наблюдения | 20 | Объем выборки |
|
| Дисперсионный анализ | |||||
| df | SS | MS | F | Значимость F | |
| Регрессия | 3,00 | 1,58 | 0,53 | 1,71 | 0,21 |
| Остаток | 16,00 | 4,93 | 0,31 | Проверка гипотезы о значимости модели | |
| Итого | 19,00 | 6,51 |
| ||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | |||||
| Y-пересечение | 0,36 | 0,53 | 0,68 | 0,50 | ||||
| Переменная X 1 | 0,03 | 0,02 | 1,39 | 0,18 | ||||
| Переменная X 2 | 0,00 | 0,03 | -0,08 | 0,93 | ||||
| Переменная X 3 | 0,01 | 0,01 | 1,81 | 0,09 | ||||
|
| Искомые оценки коэффициентов регрессии | Среднеквадратичные отклонения оценок коэффициентов регрессии | Проверка гипотез о значимости коэффициентов регрессии | |||||
| Нижние 95,0% | Верхние 95,0% | |||||||
|
| -0,76 | 1,48 | ||||||
|
| -0,02 | 0,08 | ||||||
|
| -0,06 | 0,06 | ||||||
|
| 0,00 | 0,03 | ||||||
|
| Доверительные интервалы | |||||||
| ВЫВОД ОСТАТКА |
|
|
| Наблюдение | Предсказанное Y | Остатки |
| 1 | 1,30 | -0,40 |
| 2 | 1,82 | -0,52 |
| 3 | 1,08 | 0,92 |
| 4 | 0,88 | -0,28 |
| 5 | 0,92 | -0,22 |
| 6 | 0,98 | -0,08 |
| 7 | 1,61 | -0,51 |
| 8 | 1,63 | 0,27 |
| 9 | 1,81 | 0,79 |
| 10 | 1,28 | 0,02 |
| 11 | 1,54 | 0,36 |
| 12 | 1,32 | 0,58 |
| 13 | 1,25 | 0,15 |
| 14 | 1,26 | -0,86 |
| 15 | 0,88 | -0,08 |
| 16 | 1,43 | 0,37 |
| 17 | 1,31 | -0,41 |
| 18 | 1,56 | -0,46 |
| 19 | 1,11 | 0,79 |
| 20 | 1,33 | -0,43 |
Для построения прогноза зависимой переменной Y, необходимо в массиве исходных данных добавить строку для значений независимых переменных X1, X2, X3, для которых Вы хотите найти прогнозное значение Y. В нашем примере – эта 22 строка (рис. 22). И затем активируйте функцию ТЕНДЕНЦИЯ.

Рис. 22
Использование функции ТЕНДЕНЦИЯ для определения точечного прогноза по линейной функции. Для этого надо выбрать:
ВСТАВКА  Функции
Функции
Статистические
ТЕНДЕНЦИЯ,
отметив в качестве массивов столбцы интересующих переменных.

Рис. 24
В результате получим прогнозное значение переменной Y. В примере результат помещен в ячейку 22А, и при прогнозных значений Х 1=20, Х 2=12, Х 3=50, прогнозное значение Y будет равно 1,6219.

Рис. 25